


1.当一个用户在搜索框里输入一句话然后点击搜索,系统大致会经历一个怎样的处理流程?
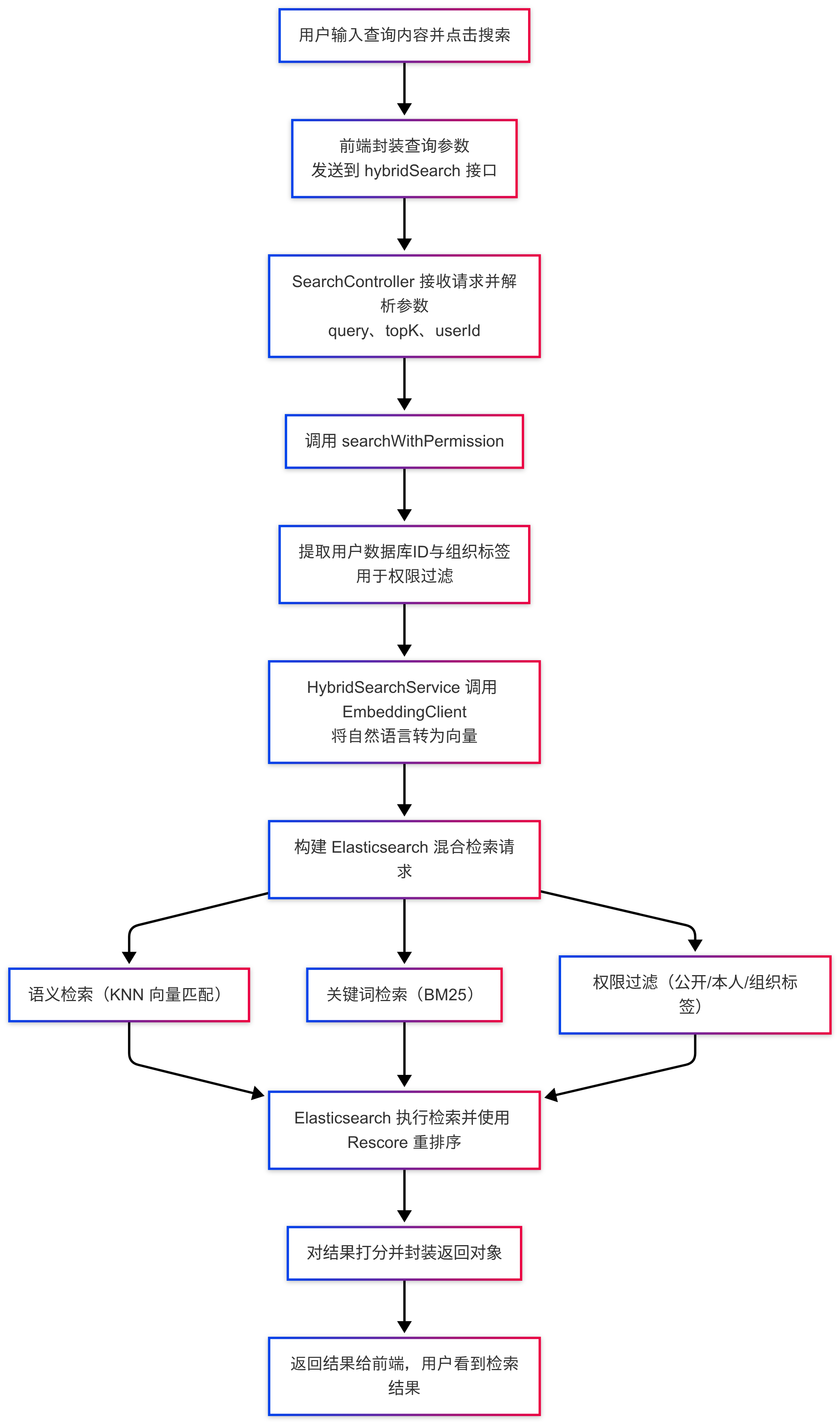
首先,用户通过前端页面输入搜索内容并提交,前端会将查询语句、用户信息等参数封装成 HTTP 请求发送到后端。后端接收到请求后,会解析出查询关键词和用户身份。
在进入搜索逻辑前,系统首先会调用外部的 Embedding 模型将用户的自然语言查询转化为向量表示。这一步是实现语义相似度搜索的基础。同时,系统还会提取出用户对应的组织标签,用于后续的权限过滤。
随后,系统会构造出一个 Elasticsearch 混合查询。融合了三类能力:首先是基于查询向量的 KNN 语义检索,用于找出语义上最接近的文本块;其次是基于关键词的 BM25 检索,用于匹配关键词相似的文档;最后是权限过滤机制,确保返回的文档必须是公开的、或属于该用户本人,或其组织标签在用户的有效标签列表中。
为了提高结果的相关性和精度,我们还会使用 Elasticsearch 的 rescore 机制,根据 BM25 与向量匹配的得分对初步召回的结果进行重排序,找到最终排名靠前的文档,并打分后返回给前端。
- 什么是 KNN?https://www.elastic.co/cn/what-is/knn
- 什么是 BM25:https://www.elastic.co/cn/blog/practical-bm25-part-2-the-bm25-algorithm-and-its-variables
备注:
kNN 又称 k 最近邻算法,会使用临近度来将一个数据点与训练时所使用并已记住的一个数据集进行对比,从而做出预测。其中字母 k 表示在分类或回归问题中所考虑的最近邻的数量,NN 代表 k 所选数字的最近邻。
面试时可以这样回答:kNN 是 Elasticsearch 的一个向量相似度搜索功能。它允许我们搜索‘内容语义’而不仅仅是‘关键词’——比如用问题匹配知识库答案,本质是让搜索引擎具备‘联想’的能力。
想象传统图书馆用关键词查书(BM25),而 kNN 像一位懂内容的图书管家:
- 内容转密码(Embedding):管家会把每本书的核心思想(文本 / 图片 / 音频)翻译成一组数字密码(向量),比如《sanguoyanyi》可能编码为
[0.8, -0.2, 0.3,...]。 - 相似即邻近(向量空间):内容相似的书,数字密码在坐标系中的距离越近(比如《shuihu传》靠近《sanguoyanyi》,远离《量子力学》)。
- 按距离推荐(kNN 查询):当你问:“找和《sanguoyanyi》风格类似的书”,管家立刻在坐标系中锁定离它最近的 k 本书(k=5 就是找最相似的 5 本)。
在 Elasticsearch 中,kNN 通过两类方式实现:
- Exact kNN:暴力计算目标向量与所有向量的距离,语法上用 knn 查询 + vector 字段。
- ANN(Approximate Nearest Neighbor):使用 HNSW 算法(分层导航小世界)建立向量索引,语法上在创建索引时定义
"type": "dense_vector" + "index": true
// 示例:HNSW 索引定义
PUT my_index
{
"mappings": {
"properties": {
"content_vector": {
"type": "dense_vector", // 向量类型
"dims": 768, // 维度数(需与模型匹配)
"index": true, // 启用ANN索引
"similarity": "cosine" // 相似度算法(余弦/点积/L2)
}
}
}
}
BM25 是 Elasticsearch 的默认搜索评分算法,它的核心任务是 判断文档和搜索关键词的相关性。可以把它想象成一个公平的裁判——不仅看关键词出现次数,还要看关键词的“含金量”,同时防止长文档zuobi。
- 关键词在 当前文档 出现次数越多,得分越高。
- 关键词在 所有文档中越稀有(比如“量子计算机” vs “的”),含金量越高,得分越高。
- 惩罚长文档guanshui —— 比如“区块链”在 10 页的报告zhongchu现 5 次,比在 100 页的教材zhongchu现 5 次更可信。
综述:BM25 是 Elasticsearch 默认的相关性打分算法,充当了一个很聪明的裁判——用三把尺子来量文档:词频(TF)、关键词含金量(IDF)、以及文档长度惩罚机制。比如搜索‘pingguo手机’时,它会优先选聚焦主题的短文,而非泛泛而谈的长文,同时抑制堆砌关键词的行为。

30人已点赞










热门评论
10 条评论
回复