


1.介绍一下你做的派聪明RAG知识库项目,它主要是做什么的?你想通过它解决一个什么样的问题或者说有什么应用场景吗?
派聪明是一个企业级的 AI 知识库管理系统 。它的核心功能是对用户上传的私有文档(比如 Word、PDF、txt 等),进行语义解析和向量处理,然后存储到 ElasticSearch 中以供后续的关键词检索和语义检索。
当用户通过聊天界面进行对话时,系统会将用户输入的内容进行语义转化,通过 ES 的混合检索召回 TOPK 个相关信息,最后再将最近的上下文一起封装到 prompt,再发送给 LLM,从而实现检索增强生成,也就是利用 RAG 的技术架构来减少模型的输出幻觉。
派聪明主要解决的是在海量文档中快速、准确地获取信息的难题。传统的关键词搜索往往效率低下,无法理解问题的真实意图。派聪明通过结合 RAG 技术解决了这个问题。
它的工作流程包括四个关键步骤:
- 文档处理 :用户上传文档后,系统会像图书管理员一样,自动将文档内容拆分成一个个小的知识片段。
- 知识向量化 :接着,派聪明会利用豆包/阿里的向量模型为每个知识片段生成一个独特的“语义指纹”,并存入 Elasticsearch 中。
- 智能检索 :当用户提出问题时,系统会先将问题转换成“语义指纹”,然后在 ES 中寻找与问题意图最匹配的几个知识片段。
- 生成答案 :最后,派聪明会将用户的原始问题和找到的相关知识片段一起交给大型语言模型(比如 DeepSeek ),让这个“大脑”基于给定的上下文,生成一个精准、流畅、人性化的回答。
主要的应用场景包括:
①、企业内部知识库 :公司可以上传所有的规章制度、技术手册、培训材料等。员工不再需要翻阅成堆的文档,直接通过提问就能快速找到答案,例如“如何申请报销?”或“某个功能的代码实现逻辑是什么?”
②、智能客服 :将产品手册、常见问题解答等录入系统,可以打造一个 24 小时在线的智能客服,自动回答大部分用户的重复性问题,减轻人工客服的压力。
③、个人知识管理 :研究人员、学生或任何需要处理大量信息的人,可以上传自己的论文、笔记、文章,构建一个强大的私有的“第二大脑”,随时通过对话来回顾和利用自己的知识储备。
2.为了服务这些用户和场景,系统提供了哪几个最核心的功能?
首先是文档的管理,系统需要支持多种常见的文档,比如说 PDF、word 和 txt 等,这是知识库构建的基础;接着,上传后的文档能够被自动解析、切片,为后续的智能检索做准备。其次是智能问答和检索,这是整个系统的核心,用户可以通过类似 ChatGPT 的聊天界面,用自然语言进行提问。系统会理解问题并在关联的知识库中检索答案,然后生成回复。系统最好在支持语义向量搜索的同时,兼顾传统的关键词搜索。
最后,系统要支持多用户注册和登录,实现基于角色的访问控制,确保只有授权用户才能访问特定的知识库和功能。admin 用户还可以对用户、知识库、系统配置等进行统一管理。
3.项目的业务架构是怎么样的?不同模块之间的关系是什么?
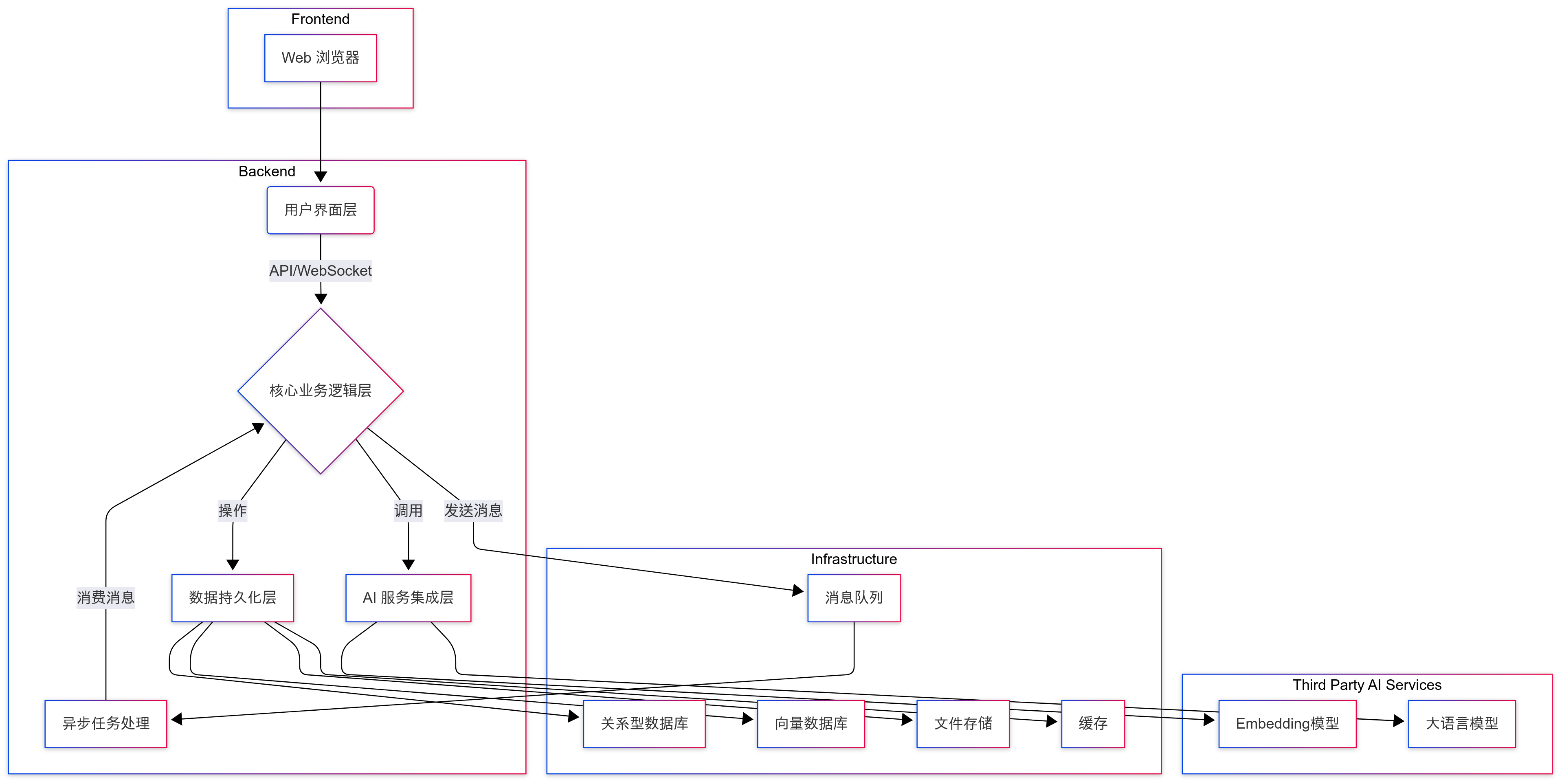
整个系统架构可以分为四层,分别是用户界面、业务逻辑、AI 集成和数据持久化。当然了,你也可以从 MVC 三层架构来回答(删掉 AI 集成层就好了)。
用户界面层基于 Vue 实现,是一个单页面应用。用户在这里完成登录、注册、文档上传和发起聊天等操作。是所有业务的入口,负责将用户的操作转化为请求,并将后端返回的响应呈现给用户。
业务逻辑层基于 Spring Boot 实现,负责处理前端请求。内部又可以细分为几个关键模块。首先是 API 网关,例如 UploadController 负责文件上传,ChatController 负责处理对话请求。接着是 Service 层,负责具体的业务实现,比如说 UploadService 负责文档接收,ParseService 负责文档解析,VectorizationService 负责调用 AI 服务生成向量,ElasticsearchService 负责持久化向量。此外,系统还通过 Kafka 优化耗时的任务执行,例如文件解析、向量化等。
AI 集成层可以理解为系统与 AI 模型之间的适配层。EmbeddingClient 负责连接向量生成模型,DeepSeekClient 负责对接大语言模型。通过这样的设计,AI 服务与业务逻辑层就实现了解耦,方便未来切换到不同的模型服务,例如换成 OpenAI、文心一言、通义千问等。
数据持久化层用于存储和管理所有业务数据。其中 MySQL 用于存储用户信息、文档元数据和对话历史;Elasticsearch 用于存储和检索文档向量;MinIO 用来存储用户上传的原始文件;Redis 用于缓存热点数据,加速数据访问。
4.既然你做的是RAG项目,讲讲你对RAG的了解?RAG解决了哪些问题?
简单来说,RAG 是一种将信息检索和文本生成模型相结合的技术框架。它要求大模型在回答问题前,先查一些前置知识再回答,避免幻觉。
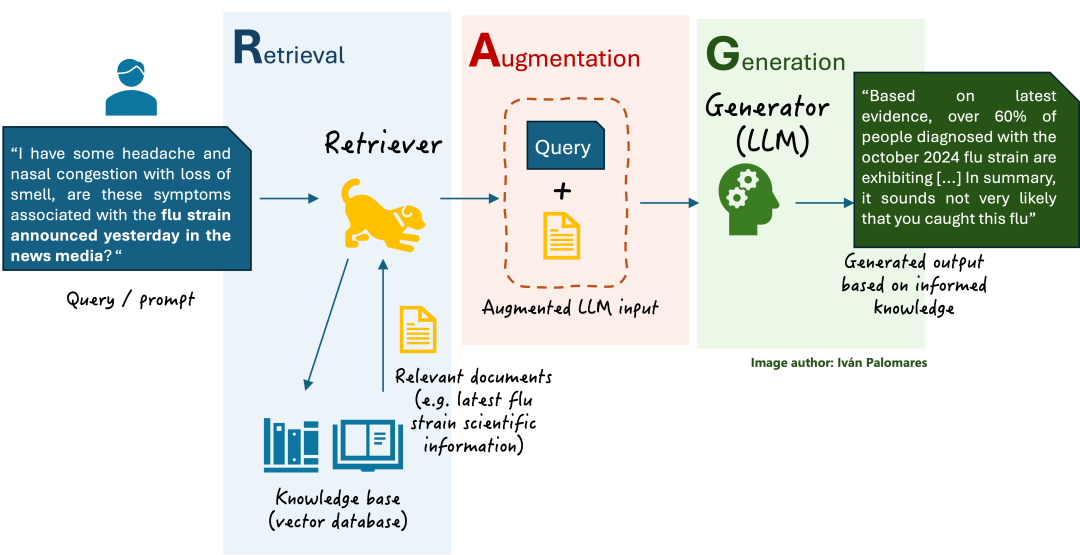
打个比方,没有 RAG 的大模型就像一个闭卷考试的学生,知识全靠记忆。而有了 RAG,大模型就变成了一个可以随时查阅指定参考资料的开卷考生,回答问题时更有据可依。RAG 主要解决了这几个痛点:
①、大模型在回答知识范围之外或不确定的问题时,会“一本正经地胡说八道”,编造看似合理但实际上是错误的信息。这在需要高度事实准确的企业场景中是致命的。RAG 通过强制大模型基于检索到的、可信的知识库来生成答案,极大减少了信息捏造的可能性。
②、大模型的知识库停留在训练数据截止的那个时间点,RAG 则将知识的存储与模型的训练分离,我们只需要把新的知识库投喂给大模型,系统就能立刻获取到最新的信息,大大缩减了训练成本。
③、 通用大模型对特定行业或企业内部的私有知识并不了解。但 RAG 能够让企业轻松地将自己的私有文档构建成一个知识库,从而让大模型更懂企业。
5.了解 LangChain 吗?
LangChain 是目前最知名、生态最庞大的大模型应用开发框架,几乎集成了所有主流的大模型、向量模型、向量数据库和 API 工具。

6.你的项目中是否用到了开源的RAG框架?为什么不使用开源的RAG框架?
派聪明没有直接使用像 LangChain4j 或 Spring AI 这样现成的、高度封装的开源框架。之所以不用,是因为:第一,我希望能够深度整合现有的技术栈,包括 Elasticsearch、Kafka 和 MinIO 等。通过自研,我可以更精细地控制数据处理流程,优化每个环节的性能。
第二,通过自研 RAG 的整个流程,我能够深入理解从文档处理、向量化、检索到生成等各个环节的核心技术细节。这不仅有助于我快速定位和解决问题,也为未来在 AI 领域的持续创新和技术迭代打下了坚实的基础。
7.你选择了以Java/Spring Boot为核心来构建这套系统。我们知道,目前Python在AI领域的生态(如LangChain)非常成熟。你当初为什么坚持选择用Java技术栈来实施一个RAG项目?
首先,我完全同意 Python 在 AI 领域的生态非常强大,特别是以 LangChain 为代表的框架,拥有无与伦bide成熟度。选择 Java 和 Spring Boot 作为派聪明项目的核心技术栈,是基于我们对项目最终形态的定位,我们希望能开发一个稳定、可持续迭代的企业级应用 ,而不仅仅是一个 AI 功能的简单封装。其次,我始终相信,Python 能做到的,Java 也能做到,这是我作为一名 Java 后端开发的自信。
8.从技术角度看,派聪明这个系统是怎么搭建的?是单体应用还是微服务?是前后端分离的吗?
派聪明是一个前后端分离的单体应用。前端使用 Vue 3 作为核心框架,并整合了构建工具 Vite, 状态管理 Pinia,以及路由 Vue Router。此外,前端还使用了 Naive UI 组件库和 UnoCSS 来快速构建用户界面。后端基于 Spring Boot 构建,负责所...
26人已点赞










热门评论
10 条评论
回复