


大家好,我是二哥呀。
历经 4 个月,派聪明 RAG 知识库项目终于完工(包括源码和教程,全部交付给大家)!
不容易啊。
派聪明如何写到简历上:https://paicoding.com/column/10/2
这篇内容我先带大家了解一下什么是派聪明,我为什么要做派聪明这个企业级的 RAG 知识库?派聪明这个 AI 项目能让大家学到什么?以及如何解锁派聪明的源码仓库和教程?

一、派聪明的起源
了解技术派的球友应该知道,派聪明最初是技术派实战项目中一部分,主打的服务是和 AI 大模型进行聊天对话(没有检索增强生成)。
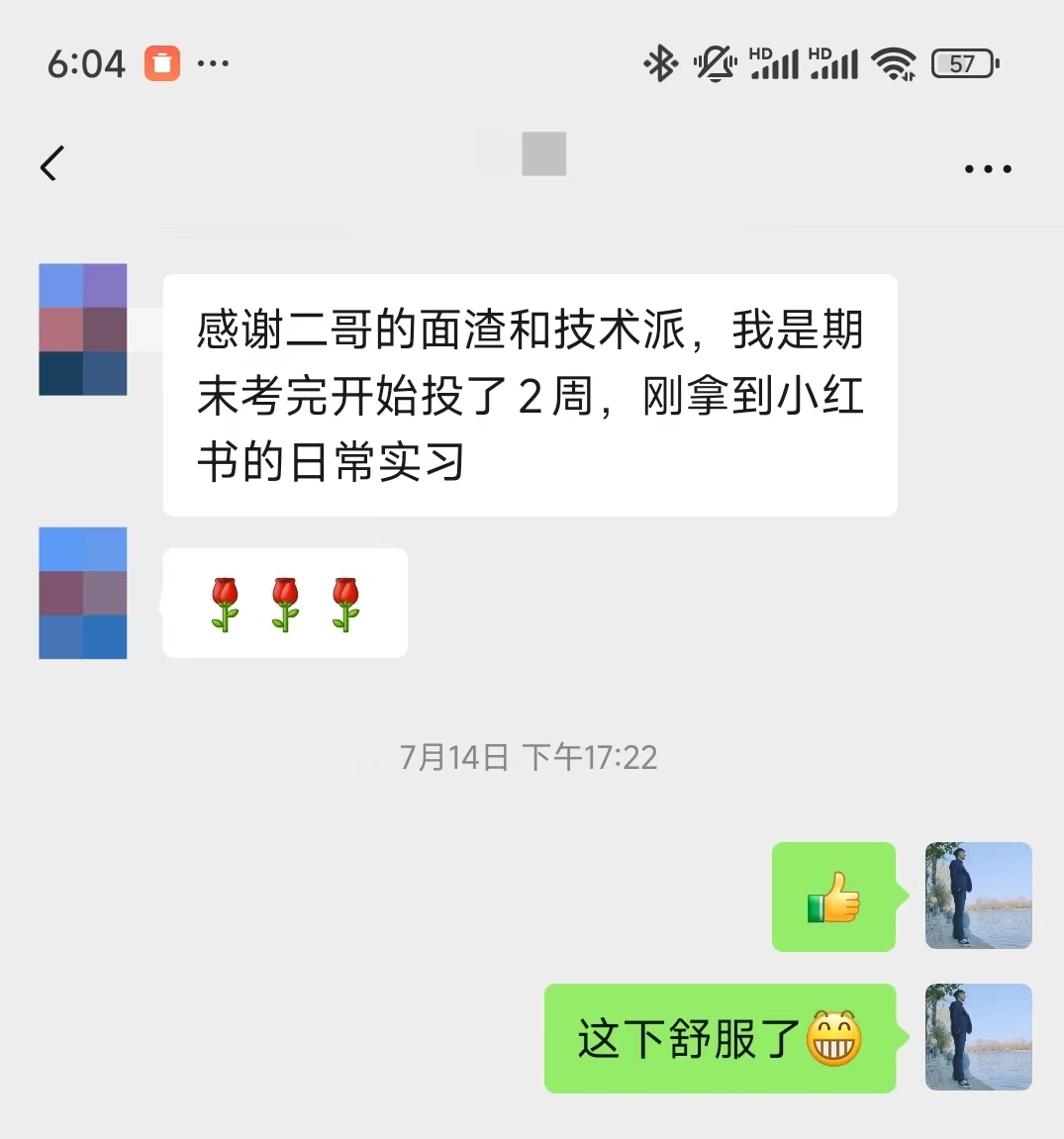
技术派这个项目也是非常经典,帮助 24、25 届,以及 26 届同学斩获了很多超出预期的 offer,我们这里就不多讲了,只贴一个喜报,一位球友靠技术派和面渣逆袭,投了两周拿下小红书的日常实习。
技术派这个项目如果你能认真学完,会收获非常非常多,基本上一个企业级的 Web 开发项目用到的技术栈,技术派都覆盖到了。

那为了延续正宗的皇家血脉,我把派聪明这三个字延续到了新的 RAG 项目,也就是大家目前看到的这个派聪明 AI 知识库项目(界面还是非常清爽的 😄)。
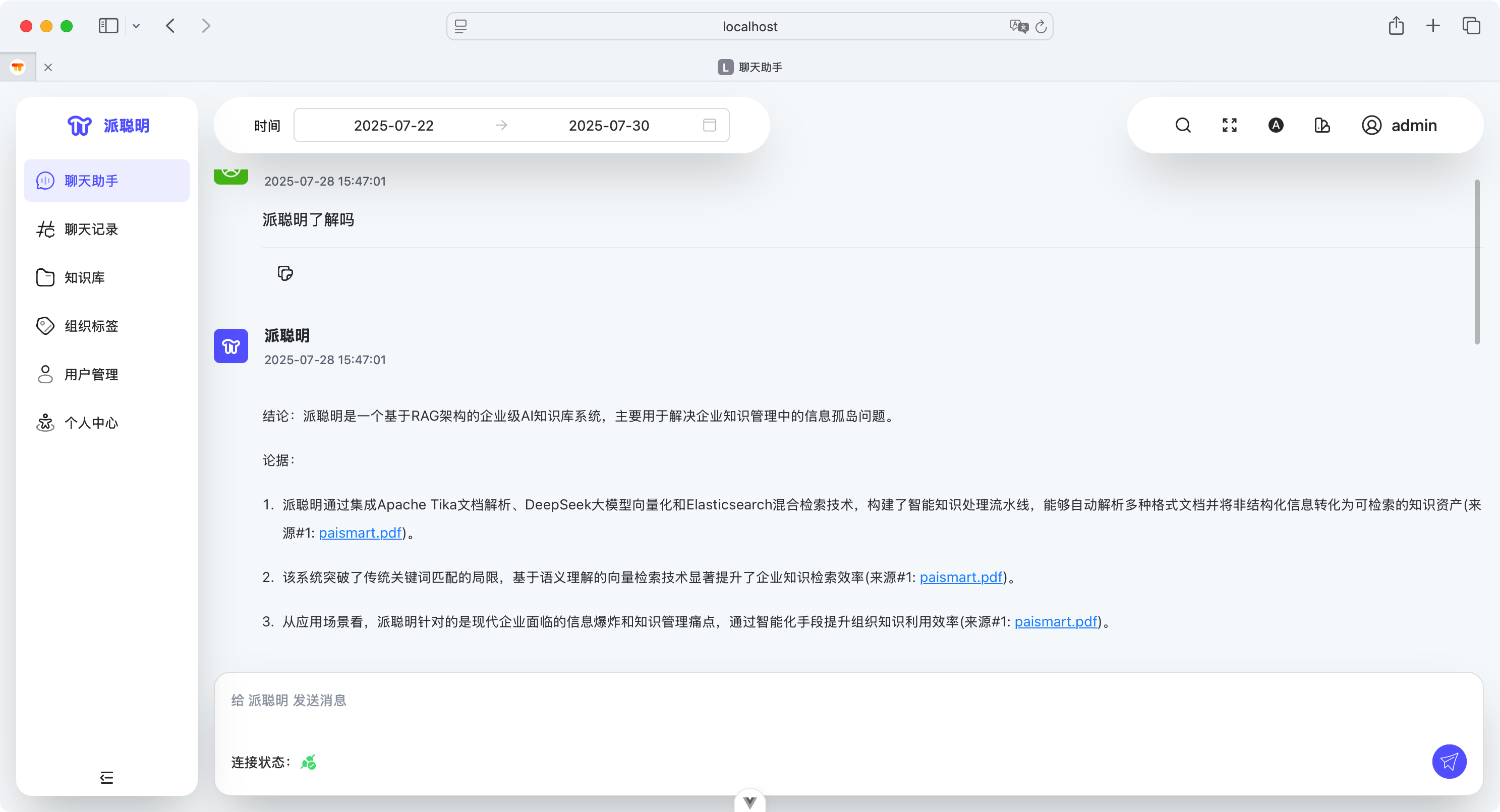
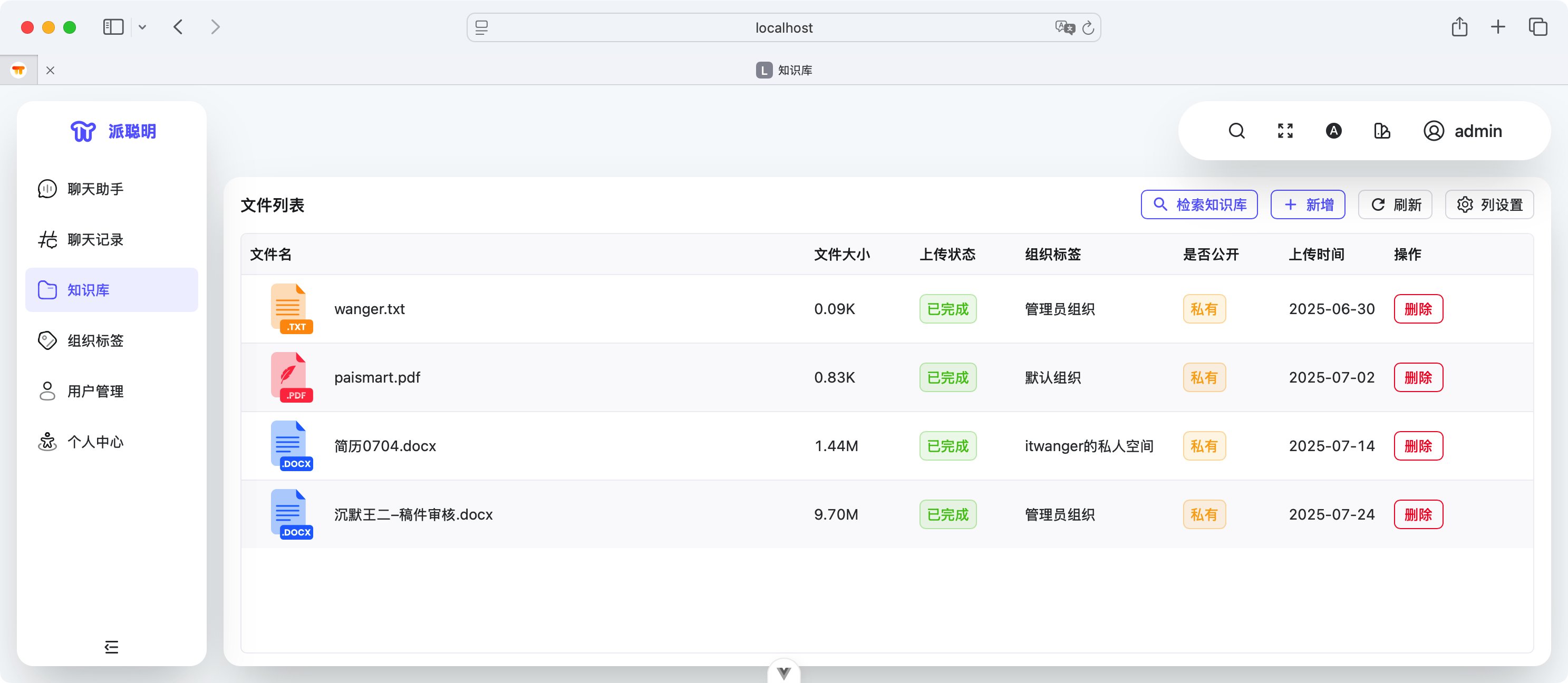
做 AI 知识库的起源,当然还是 DeepSeek 刚出来那会,我在本地用 Ollama+DeepSeek+Anythingllm 搭了一个本地的面渣逆袭知识库,当时觉得这玩意挺有意思的。刚好星球球友 Lan 来找我说,要不一起做点事吧,我就把我这个想法交给他去落实了。
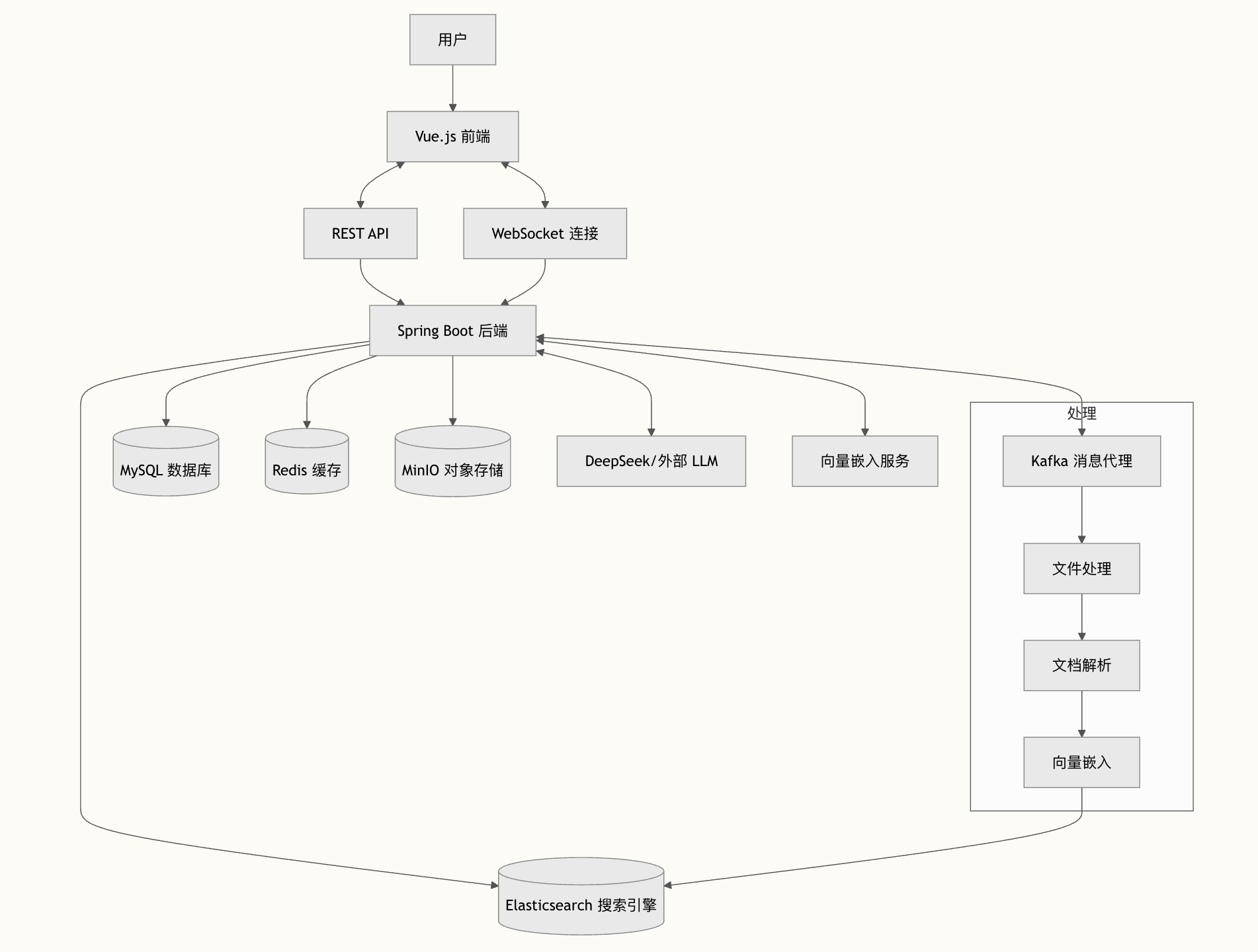
当时我没有抱很大的期待,因为从一个 idea 萌芽到开花结果,真的很难,但 Lan 信守承诺,很快就把后端搭建好了。用了很多我觉得对大家求职很有帮助的技术栈,比如说 JDK17、ElasticSearch、MySQL、Redis、MinIO、Kafka 等等,并且涉及到了很多 AI 的知识,比如说目前很火的 RAG 技术。
4 月份的时候,机缘巧合,我和朋友【我糖呢】闲聊,就讲起这个项目,他已经悄咪咪的成为一名前端大佬,于是索性我就喊他来做前端,就这样,我们的派聪明团队就算是正式成立了。
下个版本,我打算把 MCP 和 Agent 也加进来。所以,这个项目在 AI 时代,绝对是一个明星级、现象级的实战项目。
二、派聪明的技术栈
先说后端的:
- 框架/依赖管理 : Spring Boot 3.4.2 (Java 17)+Maven
- 数据库 : MySQL 8.0 + Spring Data JPA
- 缓存 : Redis
- 搜索引擎 : Elasticsearch 8.10.0
- 消息队列 : Apache Kafka
- 文件存储/解析 : MinIO + Apache Tika
- 安全认证 : Spring Security + JWT
- AI 集成 : DeepSeek API/本地 Ollama+豆包 Embedding
- 实时通信 : WebSocket
- 响应式编程 : WebFlux
后端的整体项目结构:
src/main/java/com/yizhaoqi/smartpai/
├── SmartPaiApplication.java # 主应用程序入口
├── client/ # 外部API客户端
├── config/ # 配置类
├── consumer/ # Kafka消费者
├── controller/ # REST API端点
├── entity/ # 数据实体
├── exception/ # 自定义异常
├── handler/ # WebSocket处理器
├── model/ # 领域模型
├── repository/ # 数据访问层
├── service/ # 业务逻辑
└── utils/ # 工具类
前端其实用到的技术栈也非常新,包括:
- 框架 : Vue 3 + TypeScript
- 构建工具 : Vite
- UI 组件 : Naive UI
- 状态管理 : Pinia
- 路由 : Vue Router
- 样式 : UnoCSS + SCSS
- 图标 : Iconify
- 包管理 : pnpm
前端的整体项目结构:
frontend/
├── packages/ # 可重用模块
├── public/ # 静态资源
├── src/ # 主应用程序代码
│ ├── assets/ # SVG图标,图片
│ ├── components/ # Vue组件
│ ├── layouts/ # 页面布局
│ ├── router/ # 路由配置
│ ├── service/ # API集成
│ ├── store/ # 状态管理
│ ├── views/ ...
28人已点赞









热门评论
10 条评论
回复