


✅派聪明 RAG 系统的需求分析(非常重要)
在正式开发项目之前,我们需要先了解派聪明是什么,应用场景有哪些,分析它应该包含哪些业务模块,以及需要实现哪些功能。
在大厂,这部分工作会由专门的产品经理负责,他们会根据市场反馈或竞品调研提出需求、完成需求分析并给出 PRD,然后交由开发人员实现。
在中小型公司,这些工作可能会由研发人员承担。虽然需求分析并非开发人员的本职工作,但深入了解业务和需求对开发人员来说至关重要,能够帮助我们更好地理解产品目标和用户痛点。接下来,我将带大家一起完成派聪明的需求分析。
一、我们要做的派聪明是什么?
派聪明是一个基于私有知识库的智能对话平台,允许用户上传文档构建专属知识空间,并通过自然语言交互方式查询和获取知识。它结合了大语言模型(如 DeepSeek、ChatGLM 等)和向量检索技术,让用户能够通过对话形式与自己的知识库进行高效交互。
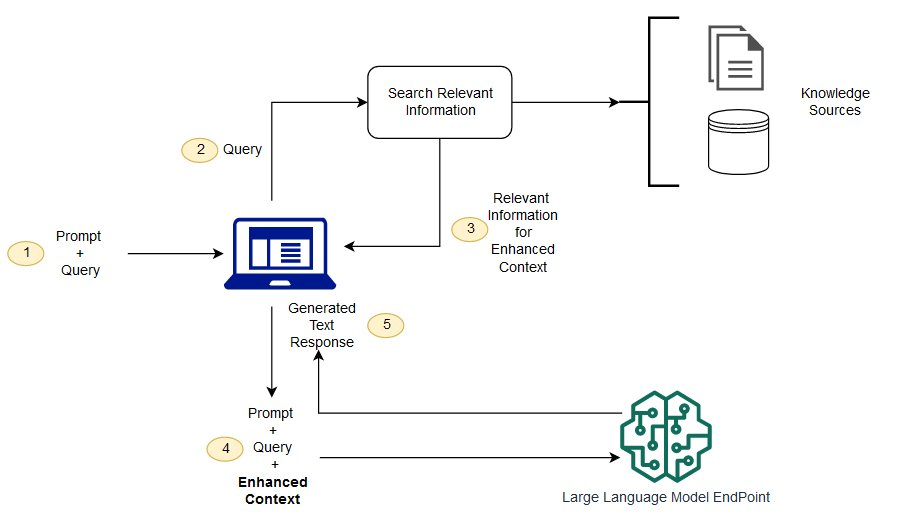
派聪明本质上是一个"知识增强型"AI 助手,它不仅仅依赖大模型固有知识,更重要的是能够基于用户提供的专属内容进行精准回答,确保信息的可靠性和私密性。
二、派聪明有什么应用场景?
派聪明的应用场景是很广泛的,不管是对于个人、学校或者企业,都会有构建私有知识库的需求,基于大模型精准检索知识库并回答,能显著提升信息的获取效率和知识的应用价值。常见的应用场景有下面几个:
个人用户场景
- 学习助手:学生可上传课程笔记、教材,构建个人学习知识库
- 研究工具:实验室里整理论文资料,进行跨文献知识连接与发现
- 创作辅助:作家、内容创作者管理素材,获取灵感和参考
企业用户场景
- 企业知识管理:整合公司制度、流程文档、技术文档等内部知识
- 新员工培训:加速新员工学习曲线,快速掌握公司业务知识
- 技术支持:技术团队快速检索产品文档、API 文档、故障处理方案
- 客户服务:客服人员实时获取产品信息,提供准确一致的客户回答
专业领域场景
- 法律咨询:律师整理法规、判例文档,辅助法律分析
- 医疗参考:医生整理医学文献、诊疗指南,辅助临床决策
- 教育培训:教师整理教学资料,为学生提供个性化辅导
三、派聪明解决了哪些痛点?
从技术角度来看,传统的企业知识管理存在很多痛点。最明显的就是信息孤岛问题,各个部门的文档散落在不同的系统里,有的在邮件附件,有的在共享文件夹,还有的在各种云盘里。员工想找个资料,得在好几个地方翻来翻去,效率极低。
派聪明通过统一的文件管理系统解决了这个问题。它不仅支持各种常见的文档格式,还...

69人已点赞










热门评论
10 条评论
回复