


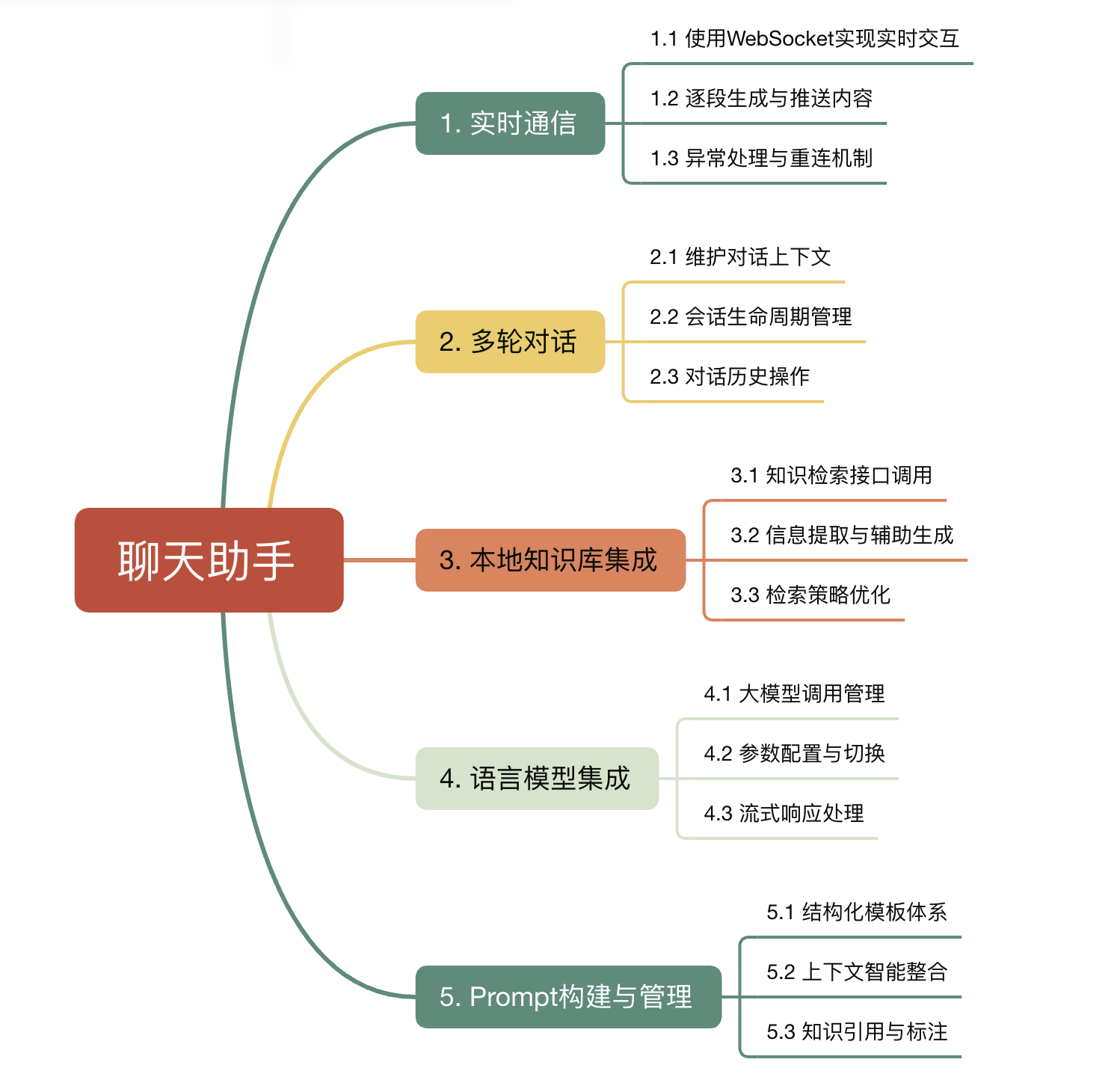
聊天助手模块是派聪明系统的核心组件之一,承载了用户与系统之间的主要交互能力。
模块通过 WebSocket 协议实现双向通信,支持大语言模型(接入了 DeepSeek)输出内容的流式返回;为支持多轮连续对话,该模块集成了 Redis 用于存储和维护用户会话上下文,确保大模型在生成回答时能够“记住”前文内容,维持语义连贯性。
同时,模块深度集成了 Elasticsearch,可以为用户提供结构化文本的全文索引和关键词匹配,通过这套混合检索机制,派聪明能在海量本地知识中快速定位与用户问题相关的信息片段。
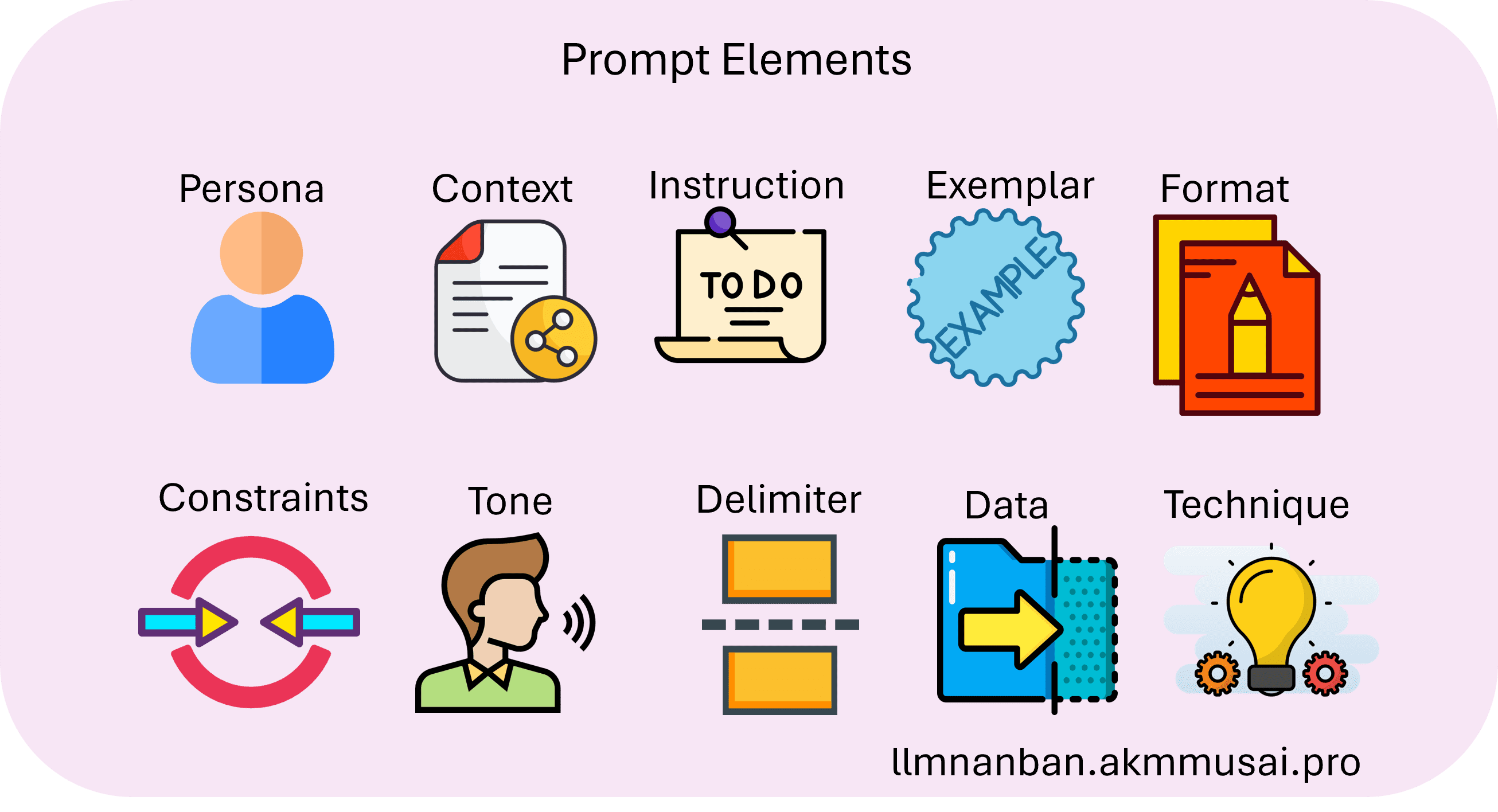
为了更好地引导大语言模型生成高质量回答,系统特别强化了 Prompt 构建与模板管理能力:
- 根据检索结果动态生成 Prompt;
- 支持多种 Prompt 模板配置与调优;
- 确保内容组织清晰、有重点,引导模型围绕核心信息生成响应。
这一机制是实现 RAG 的关键保障,确保模型回答既有语义逻辑,又有知识依据。
一、功能需求
二、技术选型
| 功能模块 | 技术选型 | 备注 |
|---|---|---|
| 实时通信 | WebSocket(基于Spring WebSocket) | 支持STOMP子协议 |
| 对话上下文存储 | Redis(使用Spring Data Redis) | 高性能缓存,支持TTL |
| 本地知识库(当前) | Elasticsearch | 支持混合检索 |
| 本地知识库(规划) | Faiss | 提升向量检索性能 |
| 语言模型调用 | DeepSeek API | 通过WebClient调用 |
| Prompt管理 | 自研模板引擎 | 支持动态模板和变量替换 |
| 异步处理 | Spring WebFlux | 支持响应式编程 |
| 安全认证 | JWT | 确保WebSocket连接安全 |
三、关键流程
01、用户发起对话流程
当用户在页面上开始一次对话时,系统的第一步是由客户端主动发起一个 WebSocket 连接请求,这个请求里会带上用户的 JWT 身份认证信息。
服务端收到请求后,会先验证用户的身份和权限,确认无误后,就会和客户端建立一个稳定的 WebSocket 长连接,用于后续的实时对话。
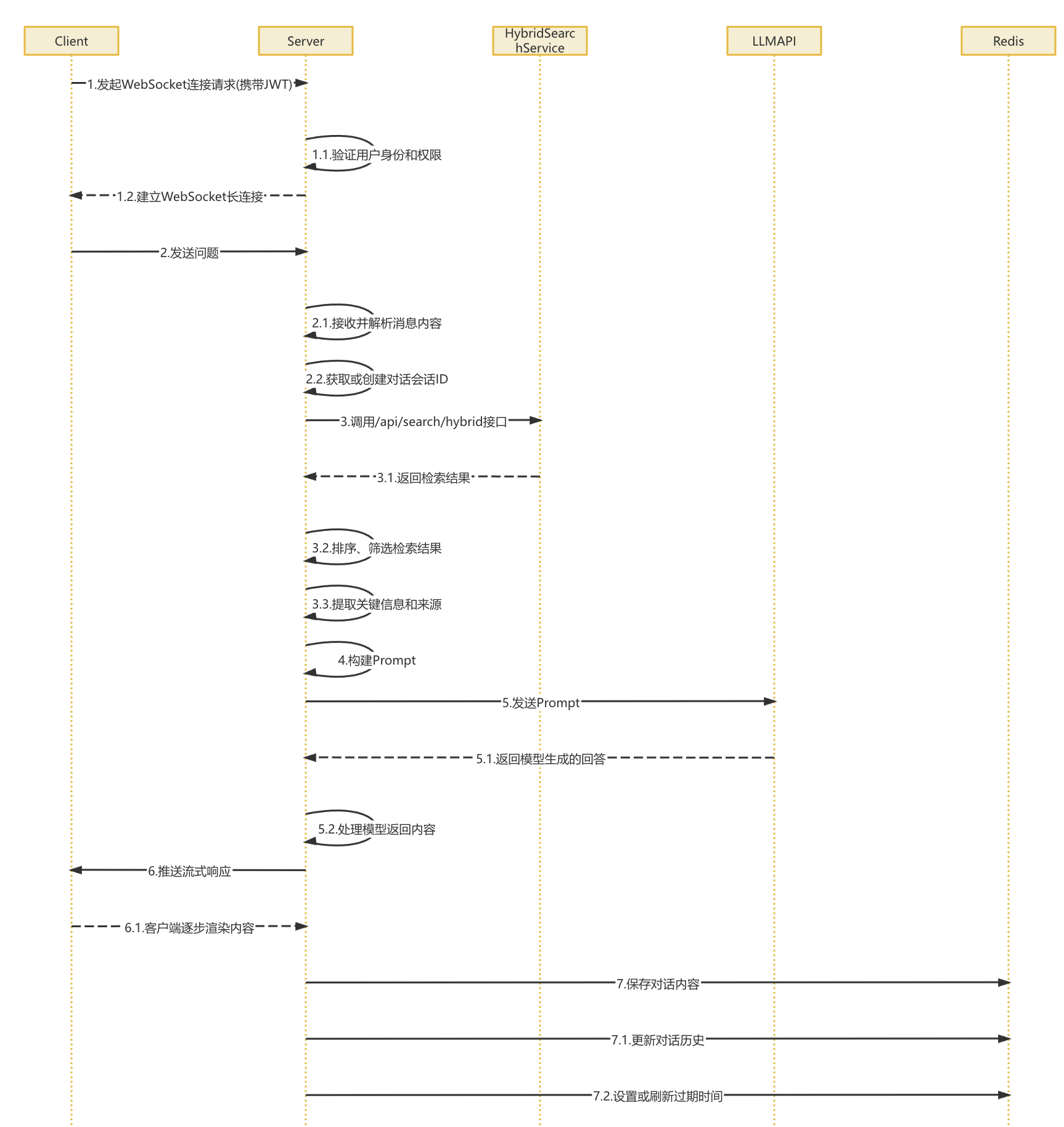
连接建立之后,用户可以开始提问了。客户端会把用户输入的问题通过 WebSocket 发给服务端。服务端这边接收到消息后,会先解析内容,然后根据情况获取一个当前的会话 ID,如果是新的对话,就创建一个。
接着系统会启动知识库检索流程。它会调用内部的 /api/search/hybrid 接口,执行一轮“混合检索”,也就是结合关键词匹配和语义匹配的方式,快速从本地知识库中找出和用户问题最相关的文档。这些结果还会再经过筛选、排序,并提取出关键内容和出处信息,为后面生成回答做准备。
在拿到检索结果后,系统会开始构建 Prompt,也就是发送给大模型的提问模板。它会根据问题类型选择一个合适的 Prompt 模板,然后把刚刚检索到的内容填进去,同时还会加上一些系统级的指令或限制条件。这个过程中还会管理好上下文的长度,保证多轮对话的连贯性,最终生成一份结构化的 Prompt。
准备好 Prompt 之后,系统会把它发送给大语言模型的 API(比如 DeepSeek)。大模型会开始生成回答,系统这边则以流式的方式逐段接收内容。为了保证体验,还会处理模型返回中的异常或错误,比如超时、内容为空等问题。
生成内容后,系统会把这些文本切分成一段一段,再通过 WebSocket 实时地推送给客户端。这样用户就能一边看到内容一边...

16人已点赞










热门评论
10 条评论
回复