


✅派聪明 RAG 知识库的Prompt设计
一、Prompt是什么?
Prompt,也就是提示词,可以理解为 “给大模型制定的一个指令”,把我们希望模型扮演的角色、使用的资料、遵循的规则、回答的任务一次性告诉它。
常见元素有:
- system (系统指令)
- user (本轮问题)
- assistant (历史回复)
- 额外上下文(检索结果、函数签名等)
我们都知道,AI 很强大。但是,如何让 AI 理解我们的需求,给出符合我们预期的回答呢?这就需要用到 prompt。
举一个最简单的例子,很多同学在第一次使用 AI 时,习惯问一句“你是谁”,这个你是谁,其实就是一个提示词。

但提示词越符合 AI 的习惯,我们就越容易得到最想要的回复。
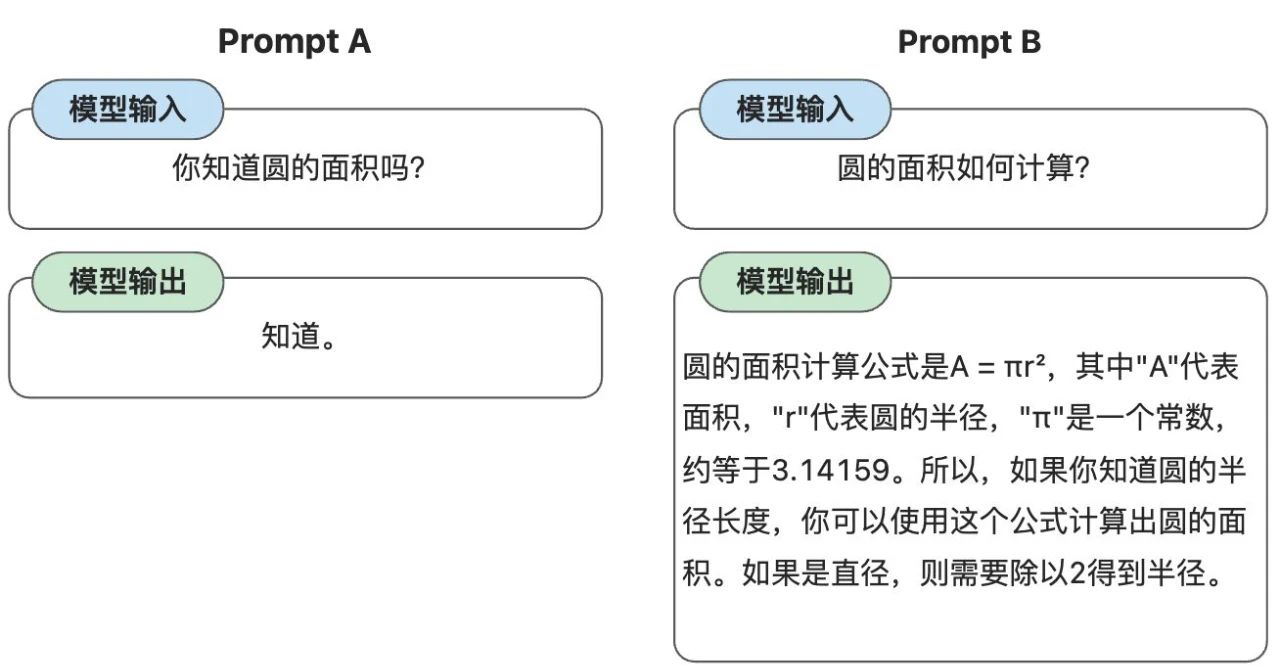
右侧的提示词的可能会比左侧的提示词,更能从 AI 那里得到我们预期的回答。
那针对派聪明的提示词,我们主要用到了这些:
① 角色设定,比如说:
{
"role": "system",
"content": "你是一位严谨的图书编辑,所有回答必须使用正式中文并引用页码。"
}
再比如说:
{
"role": "system",
"content": "以下是年份与销量数据表,请在回答时引用表内数字:\n\n| 年份 | 销量 |\n| 2020 | 2.1M |\n| 2021 | 3.4M |"
}
那派聪明的系统级提示词主要是从配置文件中 prompt 动态拼接的。

我们会把规则、引用的知识库添加到到 system 中。
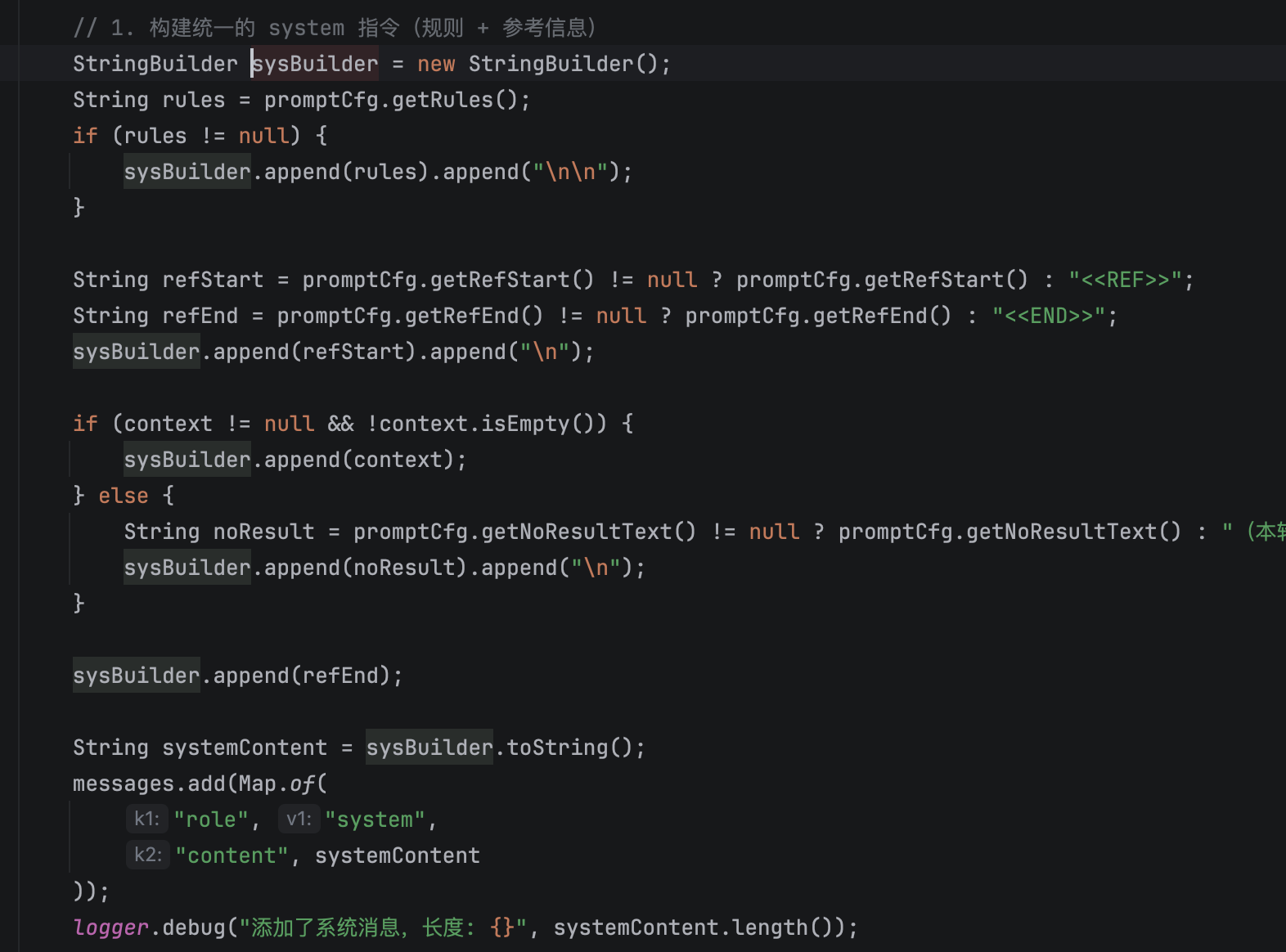
② 历史对话:
{
"role": "assistant", "content": "您好,我可以帮助您查询产品信息。"
}
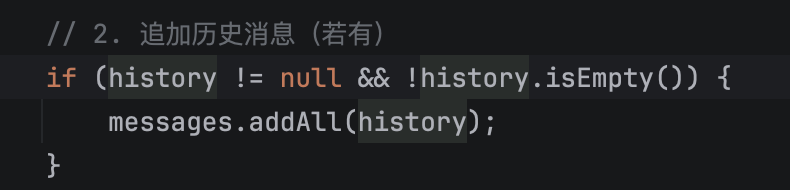
派聪明会把用户在聊天助手中的历史记录动态拼接进来。
代码主要是在 buildMessages 的方法中。
③ 完整的 RAG Prompt
[
{ "role": "system", "content": "你是企业知识库助手…" },
{ "role": "system", "content": "<>\n[1] …检索片段…\n<>" },
{ "role": "user", "content": "请解释合同中不可抗力条款" }
]
简单讲,Prompt 就是把人物设定 + 资料 + 任务打包发给模型的“提纲”。
二、Prompt 为什么能决定 RAG 的成败?
RAG 的核心是“用检索到的外部知识束缚模型”。Prompt 如果在参数上失控,就会直接削弱 RAG 的价值。
01、派聪明 prompt 的关键参数
| 关键参数 | 含义 & 推荐做法 | 设置不当的后果 |
|---|---|---|
| 指令优先级 | 规则必... |

10人已点赞










热门评论
5 条评论
回复