


通过✅派聪明需求分析,我们已经了解到:
派聪明是一个基于 RAG 的 AI 知识库智能问答平台,通过结合大语言模型(如 DeepSeek)和向量化技术,为用户提供高效、精准的问答服务。
用户可以通过上传文档构建专属的私有知识库,并实时与派聪明进行交互提问。派聪明支持多轮对话、语义检索和动态知识库更新,适用于企业内部知识管理、教育、客服等场景。
那基于派聪明的需求分析,我们梳理了下列需求(思维导图一目了然):
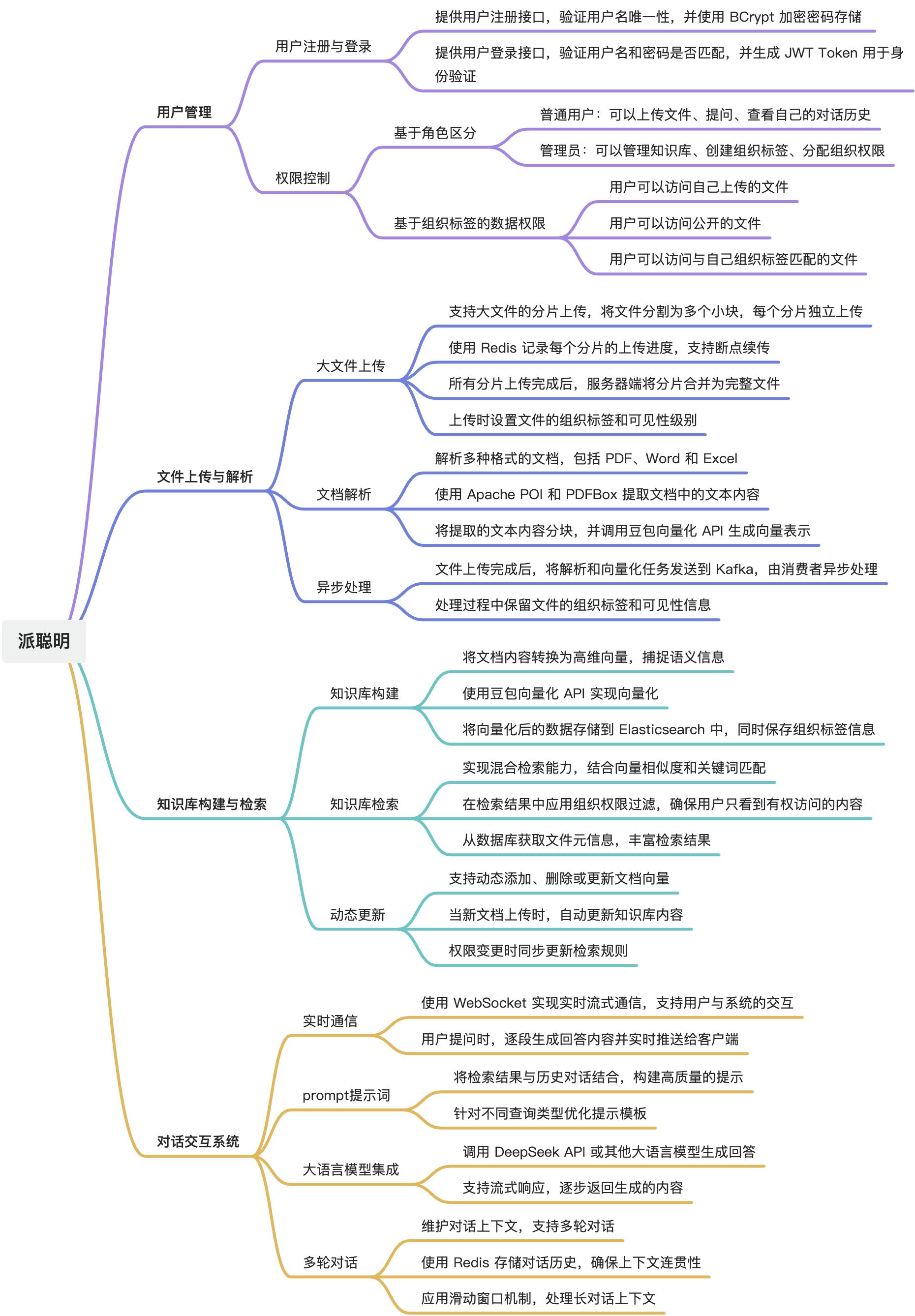
一、业务架构设计
基于派聪明的需求梳理,我们设计了这样一个三层业务架构图:
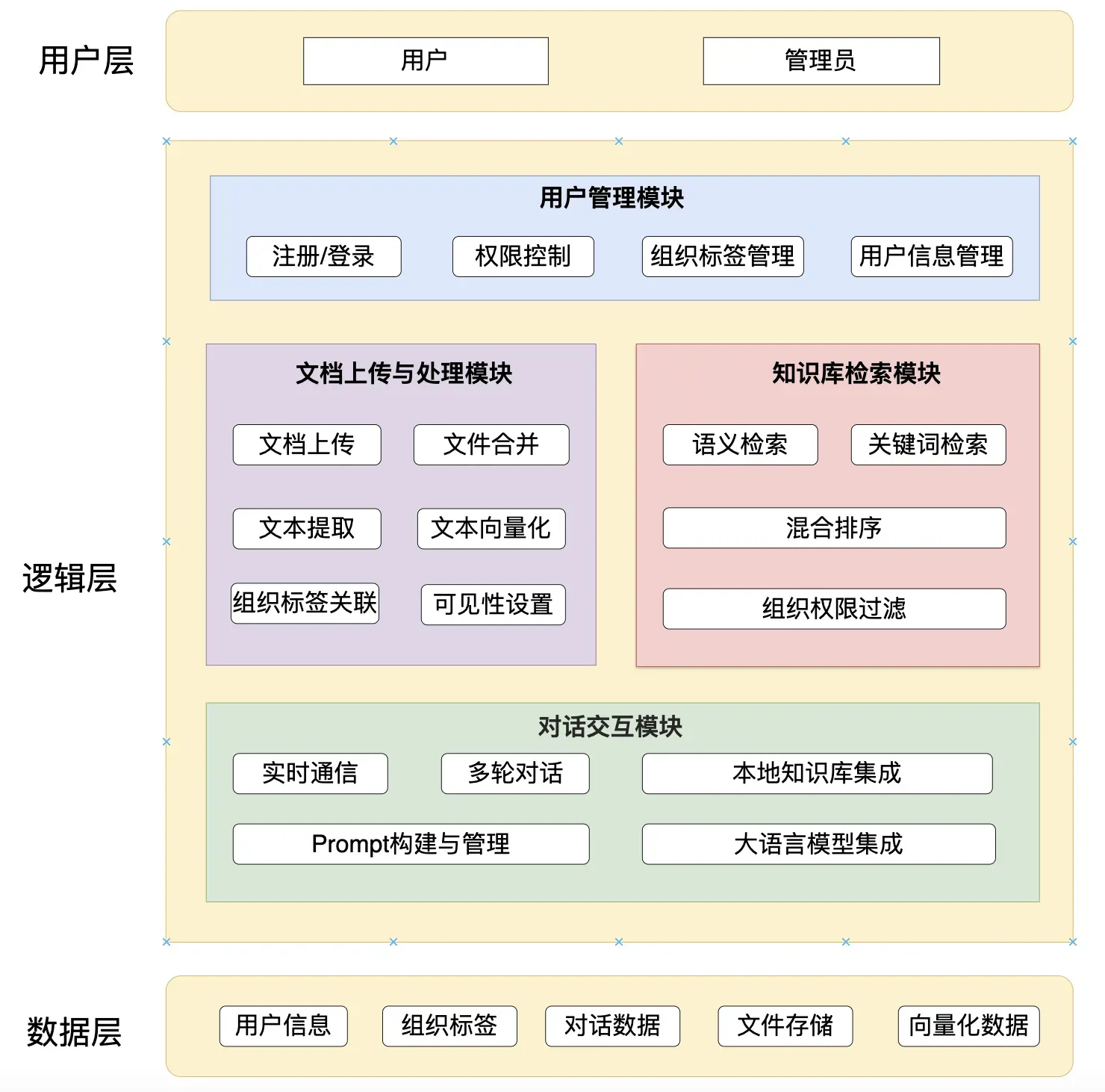
01、用户层
用户层是整个系统的入口,主要面向两类用户群体。普通用户可以通过这一层进行日常的知识查询、文档上传和智能对话等操作,他们是系统的主要使用者,通过简洁直观的界面就能享受到智能的知识服务。
管理员则拥有更高的权限,可以进行系统配置、用户管理、数据监控等管理工作,确保整个平台的稳定运行和安全性。
02、逻辑层
逻辑层是整个系统的核心,包含四个主要的功能模块,每个模块都承担着特定的业务职责。
①、用户管理模块
该模块是系统安全和权限控制的基础。注册登录功能为用户提供了基础的身份认证机制,确保只有合法用户才能访问系统资源。
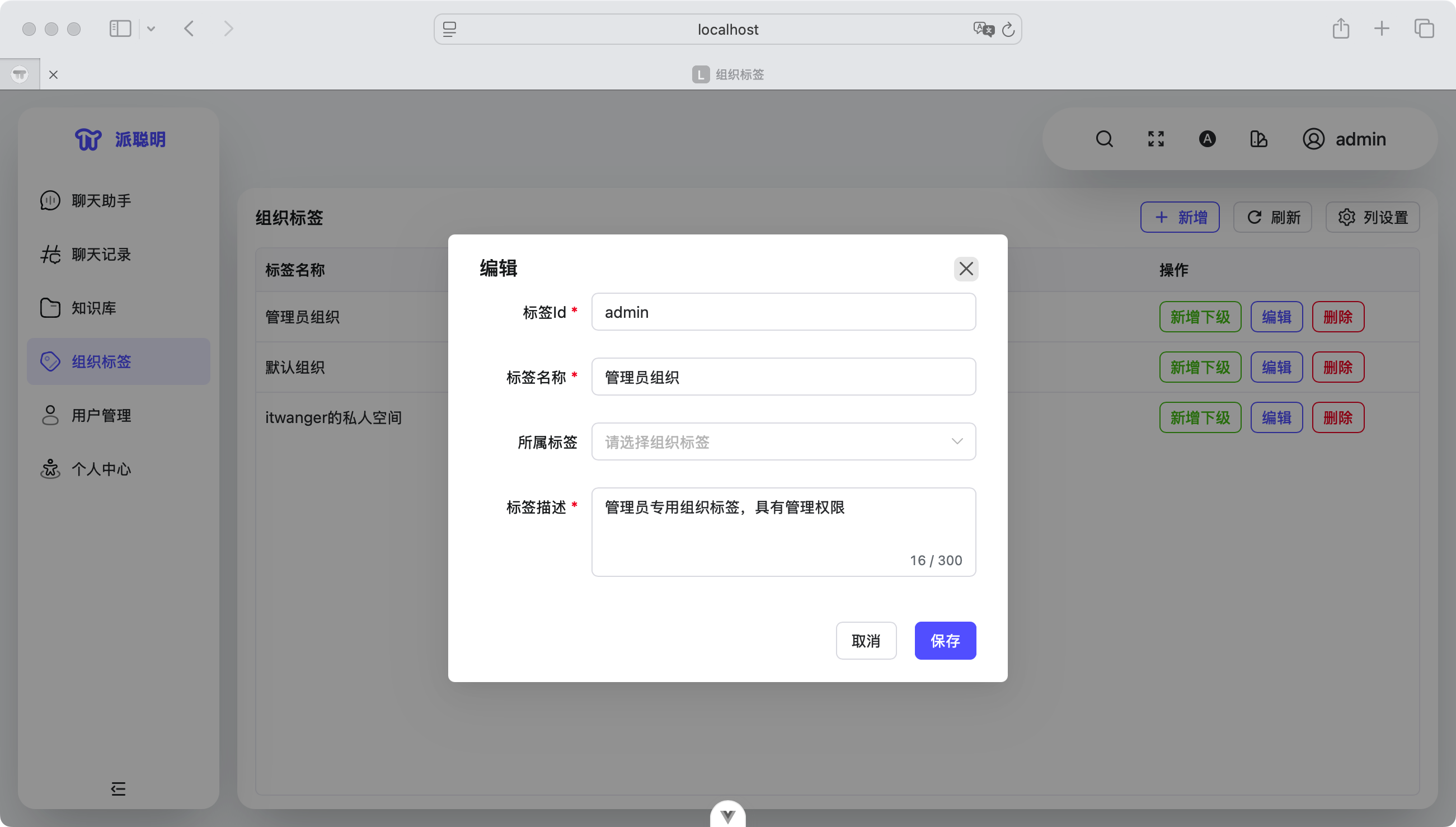
权限控制功能会根据用户的角色和级别,精确控制用户能够访问的功能和数据范围,比如某些敏感文档只有特定部门的用户才能查看。组织标签管理功能帮助企业按照部门、项目或其他维度对用户进行分组管理,使得权限分配更加灵活和精确。
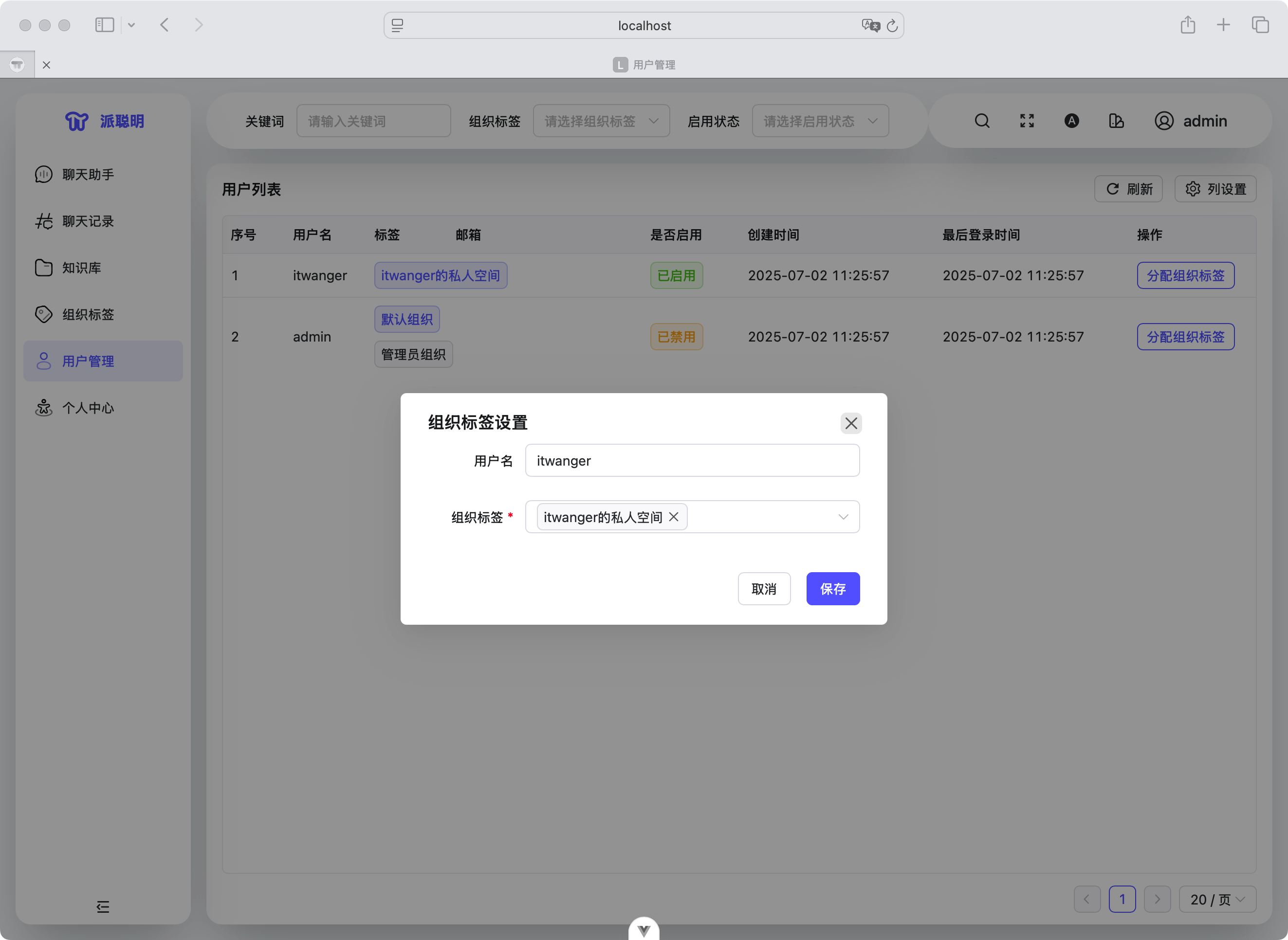
用户信息管理功能则负责维护用户的基本信息、偏好设置等,为个性化服务提供基础数据支持。
②、文档上传与处理模块
该模块是知识输入的关键环节,负责将各种格式的文档转化为系统可以理解和处理的知识内容。文档上传功能支持多种常见的文档格式,包括 PDF、Word、文本文件等,系统会自动进行格式识别和处理。

文本提取功能是这个模块的核心技术之一,我们使用了 Apache Tika 的文档解析技术,能够准确地从各种格式的文档中提取出纯文本内容,同时保留重要的结构信息。文本向量化功能则将提取出的文本转换为计算机可以理解的数学向量,这是实现语义搜索的关键技术,让系统能够理解文本的真正含义而不仅仅是关键词匹配。
组织标签关联功能确保每个文档都能正确地归属到相应的组织或部门,这不仅有助于权限控制,也便于用户在自己的权限范围内快速找到相关文档。可见性设置功能则允许文档上传者设定文档的可见范围,比如设为公开、部门内可见或仅个人可见,灵活满足不同的共享需求。
③、知识库检索模块
检索模块是用户获取知识的主要途径,我们采用了先进的混合检索技术。语义检索功能利用 RAG 技术,能够理解用户查询的真正意图,即使用户使用的词汇与文档中的表述不完全一致,系统也能找到相关的内容。比如用户搜索"如何提升销售业绩",系统不仅能找到包含这些关键词的文档,还能找到讨论"销售技巧"、"客户关系管理"等相关主题的内容。

关键词检索功能则提供了传统的精确搜索方式,当用户需要查找特定的术语、人名、地名或其他精确信息时,这种检索方式能够快速定位到相关文档。混合排序功能将语义检索和关键词检索的结果进行智能融合,综合考虑相关性、权威性、时效性等多个因素,为用户提供最有价值的搜索结果。
组织权限过滤功能确保用户只能看到自己有权限访问的搜索结果,这不仅保护了敏感信息的安全,也提高了搜索结果的精准度,避免用户被无关的信息干扰。
④、聊天助手模块
聊天助手模块为用户提供了更加自然和智能的知识获取方式。基于 WebSocket 进行实时通信,用户方法就像和真人助手交流一样。多轮对话功能让系统能够记住对话的上下文,用户可以进行连续的提问,系统会根据之前的对话内容来理解当前的问题。

本地知识库集成功能是这个模块的核心优势,系统会根据用户的问题自动搜索相关的文档内容,并将这些信息整合到回答中。这样用户不仅能得到通用的答案,更能获得基于企业内部知识的专业回答。
Prompt 构建与管理功能负责优化与 AI 模型的交互方式,通过精心设计的提示词模板,确保 AI 能够更好地理解用户意...

64人已点赞










热门评论
10 条评论
回复