


技术派之基于redis实现用户活跃排行榜
排行榜是一个很常见的需求场景了,当然对应的技术选型方案也可以说非常成熟,在技术派项目中,我们也引入了一个用户活跃度的排行榜,主要是基于redis的zset数据结构来实现,给大家实例演示一下,如何实现一个生产可用的排行榜
方案设计
在具体的代码介绍之前,先来了解一下业务场景
1. 场景说明
技术派中,提供了一个用户的活跃排行榜,当然作为一个博客社区,更应该实现的是作者排行榜;出于让大家更有参与感的目的,我们以用户活跃度来设计一个排行榜,区分日/月两个榜单
用户活跃度计算方式:
- 用户每访问一个新的页面 +1分
- 对于一篇文章,点赞、收藏 +2分;取消点赞、取消收藏,将之前的活跃分收回
- 文章评论 +3分
- 发布一篇审核通过的文章 +10分
榜单:
- 展示活跃度最高的前三十名用户
实际的榜单效果如下(可以在首页活跃排行榜侧边栏点击进入)
2. 方案设计
排行榜的业务属性比较清晰简单,对应的数据结构也可以很容易设计出来,核心的信息如下
存储单元
表示排行榜中每一位上应该持有的信息如下
// 用来表明具体的用户
long userId;
// 用户在排行榜上的排名
long rank;
// 用户的历史最高积分,也就是排行榜上的积分
long score;
数据结构
排行榜,一般而言都是连续的,借此我们可以联想到一个合适的数据结构LinkedList,好处在于排名变动时,不需要数组的拷贝
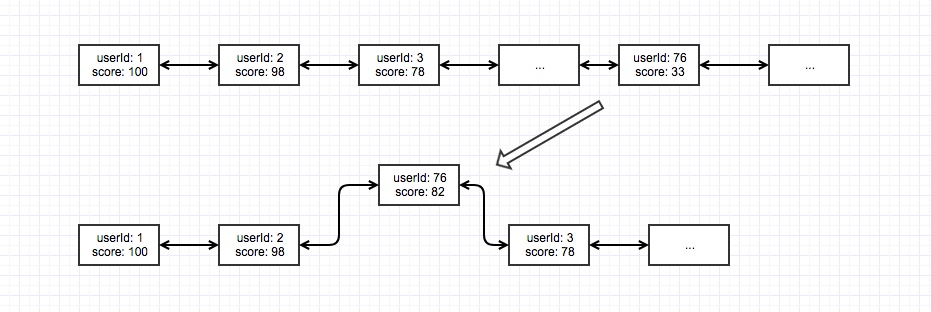
上图演示,当一个用户活跃度改变时,需要向前遍历找到合适的位置,插入并获取新的排名, 在更新和插入时,相比较于ArrayList要好很多,但依然有以下几个缺陷
问题1:用户如何获取自己的排名?
使用LinkedList在更新插入和删除的带来优势之外,在随机获取元素的支持会差一点,最差的情况就是从头到尾进行扫描
问题2:并发支持的问题?
当有多个用户同时更新score时,并发的更新排名问题就比较突出了,当然可以使用jdk中类似写时拷贝数组的方案
上面是我们自己来实现这个数据结构时,会遇到的一些问题,当然我们的主题是借助redis来实现排行榜,下面则来看下,利用redis可以怎么简单的支持我们的需求场景
3. redis使用方案
这里主要使用的是redis的ZSET数据结构,带权重的集合,下面分析一下可能性
- set: 集合确保里面元素的唯一性

15人已点赞










热门评论
5 条评论
回复