



大家好,我是二哥呀。
学不动了,真学不动了。
前脚刚把 Skill、Subagent 这一坨概念给大家盘明白,后脚 Anthropic 就甩出一个新名词——Claude Managed Agents。
点开公告页一看,好家伙,原来 Anthropic 自己亲自下场,把 Harness 这件事做成产品了。
大家有没有发现?最近一周讨论最多的已经不是 OpenClaw,而是 Harness。
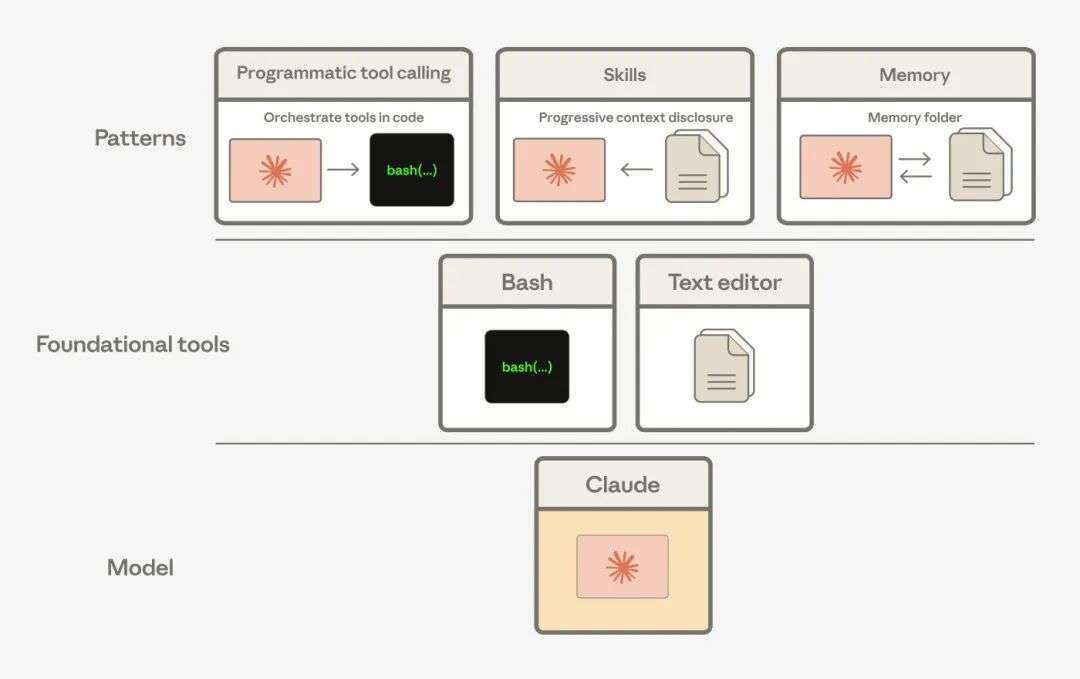
Agent = 大模型 + Harness。模型是脑子,Harness 负责把脑子变成能跑、能交付的生产系统。
沙箱、会话状态、权限作用域、端到端追踪、断线续跑、子 Agent 编排,哪一项做不好 Agent 都只能停在 demo 阶段。
4 月 8 号,A 厂直接把这套基础设施做成了托管服务,叫 Claude Managed Agents。

01、Harness 到底在解决什么
工具结果要不要全塞进上下文?
模型跑两小时突然断网,进度怎么办?
多个子任务并行怎么编排?谁来审计每一步?谁来拦截越权操作?
这一堆问题都不属于“模型的问题”,属于“基础设施的问题”。
Harness 就是解这一堆问题的总称——把模型包起来的运行环境,决定模型在哪里工作、用什么工作、出错了怎么恢复、做了什么要被记录。
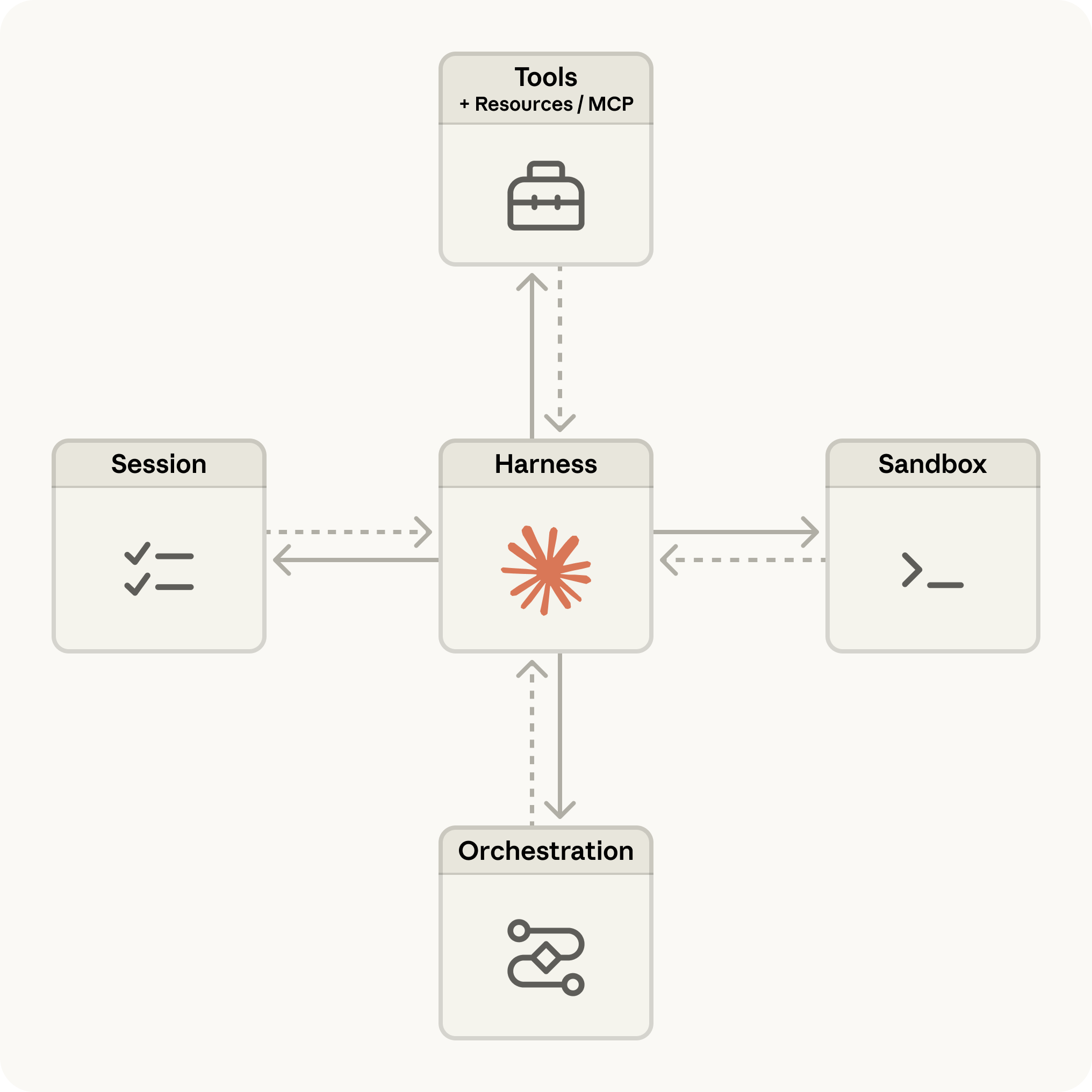
模型是脑子,沙箱、文件系统、工具执行是手脚。
说白了,Harness 不是新概念,是过去一年大家被折磨出来的统一叫法。Claude Code 之所以好用,本质上就是因为内部有一套精心设计的 Harness。
去年大家自己造的那些“Agent 框架”,本质上就是在造 Harness。LangGraph、AutoGen、CrewAI 各自有各自的一套,做法不同,但解决的问题是一样的:怎么让 Agent 在生产环境里跑起来,并且尽量满足人的预期。
这个市场本来是给第三方框架做的,Anthropic 现在直接下场,亲自给自己的模型配一套官方 Harness。
现在 Anthropic 把这套东西从 Claude Code 里抽出来,变成所有人都能调用的 API。
02、Claude Managed Agents 是什么
官方对它的定义是:a composable suite of APIs to build and deploy cloud-hosted Claude agents——一套可组合的 API 套件,用来构建和部署托管在云上的 Claude Agent。
听上去很抽象。我们拆开来看。
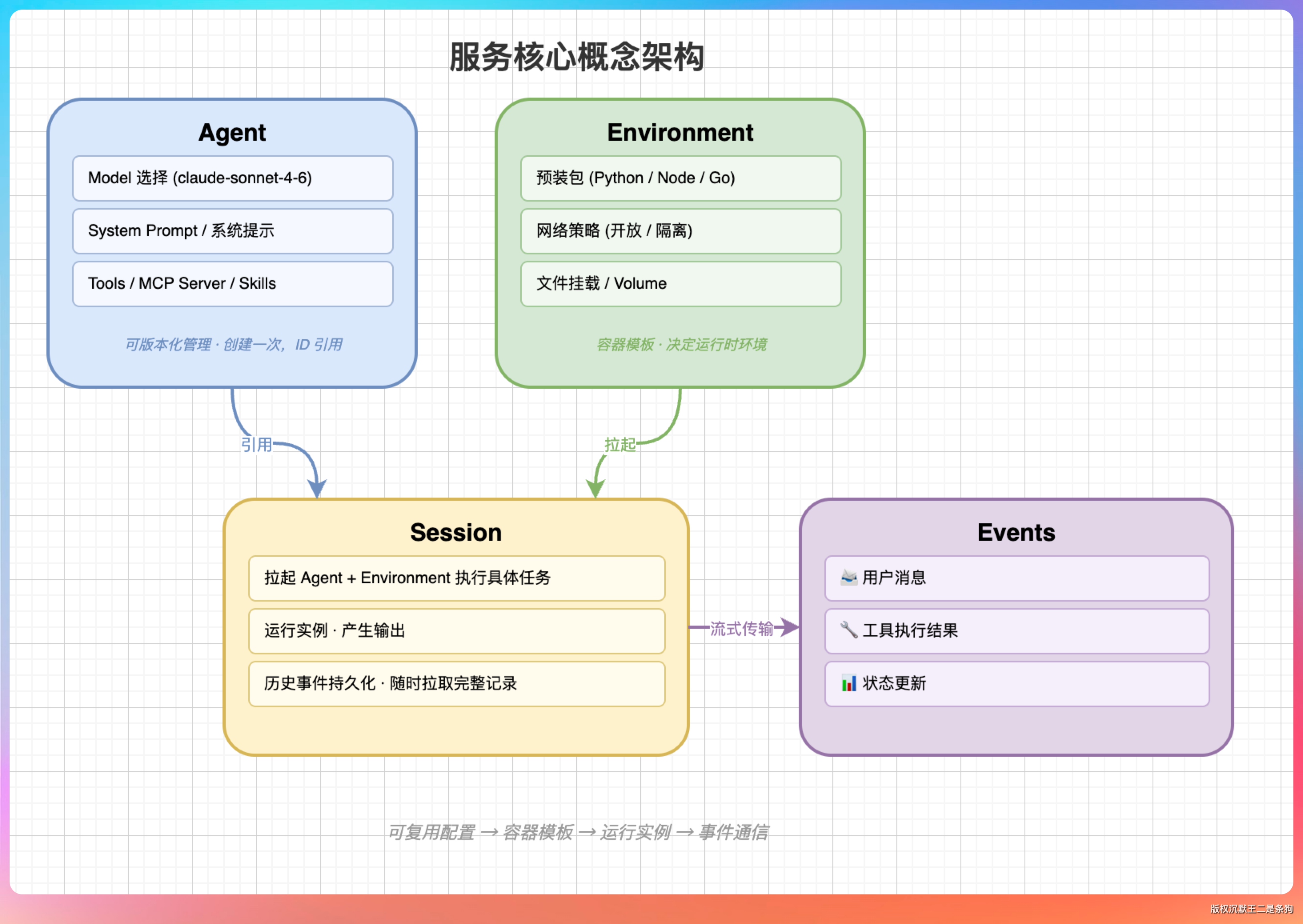
整套服务围绕四个核心概念运转:
Agent 是可复用的配置对象,包含模型选择(比如 claude-sonnet-4.6)、系统提示词、工具列表、挂载的 MCP Server 和 Skills。创建一次,用 ID 引用,可以版本化管理。
Environment 是容器模板,决定 Agent 跑在什么环境里——预装了哪些包(Python、Node.js、Go……),网络是否开放,挂载了哪些文件。
Session 是一次实际的运行实例,拉起 Agent 和 Environment,执行具体任务,产生输出。每个 Session 的历史事件持久化在服务器端,随时可以拉取完整记录。
Events 是你和 Agent 之间通信的媒介——用户消息、工具执行结果、状态更新,全部用 SSE 传输。
这个设计有一个很有意思的地方:Agent 和 Environment 是分开的。
同一个 Agent 可以在不同的 Environment 里跑——生产环境网络受限、测试环境完全开放、本地调试只挂载特定文件。配置复用,环境隔离,各司其职。
官方给了一个对比表格,我直接翻译过来:
| 维度 | Messages API | Claude Managed Agents |
|---|---|---|
| 是什么 | 直接调用模型 | 预置 Harness,托管基础设施 |
| 适合什么 | 自定义 Agent 循环、精细控制 | 长时任务、异步工作 |
| 状态管理 | 自己实现 | 平台接管 |
| 工具执行 | 自己实现 | 内置 bash、文件、Web 搜索 |
一句话:想要灵活掌控就用 Messages API,想省心省力跑长任务就用 Managed Agents。两者不是替代关系,而是场景分工。
三步起一个 Session
纸上得来终觉浅。直接看代码,体感最直接。
第一步,创建 Agent:
from anthropic import Anthropic
client = Anthropic()
agent = client.beta.agents.create(
name="Coding Assistant",
model="claude-sonnet-4-6",
system="You are a helpful coding assistant. Write clean, well-documented code.",
tools=[
{"type": "agent_toolset_20260401"},
],
)
print(f"Agent ID: {agent.id}, version: {agent.version}")
agent_toolset_20260401 是 Anthropic 预打包的全套工具集,包括 bash 执行、文件读写、Web 搜索和 WebFetch,一行搞定,不用挨个配置。
第二步,创建 Environment:
environment = client.beta.environments.create(
name="quickstart-env",
config={
"type": "cloud",
"networking": {"type": "unrestricted"},
},
)
print(f"Environment ID: {environment.id}")
第三步,建 Session,发消息,拿结果:
session = client.beta.sessions.create(
agent=agent.id,
environment_id=environment.id,
title="Quickstart session",
)
with client.beta.sessions.events.stream(session.id) as stream:
client.beta.sessions.events.send(
session.id,
events=[{
"type": "user.message",
"content": [{"type": "text", "text": "帮我写一个 Python 脚本,生成前 20 个斐波那契数并保存到 fibonacci.txt"}],
}],
)
for event in stream:
match event.type:
case "agent.message":
for block in event.content:
print(block.text, end="")
case "agent.tool_use":
print(f"\n[正在使用工具: {event.name}]")
case "session.status_idle":
print("\n\nAgent 完成任务。")
break
注意一个细节:所有 Managed Agents 的 API 请求都需要带 managed-agents-2026-04-01 这个 beta header,SDK 会自动处理,curl 手写的话需要手动加。
Agent 在跑的过程中,所有事件通过 SSE 流式推送回来。
agent.message 是模型的文字输出,agent.tool_use 是工具调用事件,session.status_idle 表示 Agent 完成了本轮任务没有其他要做的了。这个空闲信号很重要,我们在它出现的时候才能确定 Agent 真正做完了,而不是在等后续工具结果。
另一个好用的地方是中途介入。
Session 跑到一半,发现方向不对,可以直接再往 events 里发一条用户消息,Agent 会读到这条新的指令并调整方向,不需要重启整个 Session。
这个能力在长任务里特别实用——比如 Agent 已经把代码写好了,你突然想加个需求,不用重头来,直接插一句话就行。
这三步走下来,一个跑在云端、带完整工具集的 Agent 就起来了。以前要自己搭 Docker、自己实现 Agent 循环、自己处理状态持久化,现在都不需要了。

03、Anthropic 的三个设计原则
把文档翻了一遍,Anthropic 在官博里总结了他们设计 Claude Managed Agents 的三个核心思路,每一个都值得细品。
用 Claude 已经成熟的工具
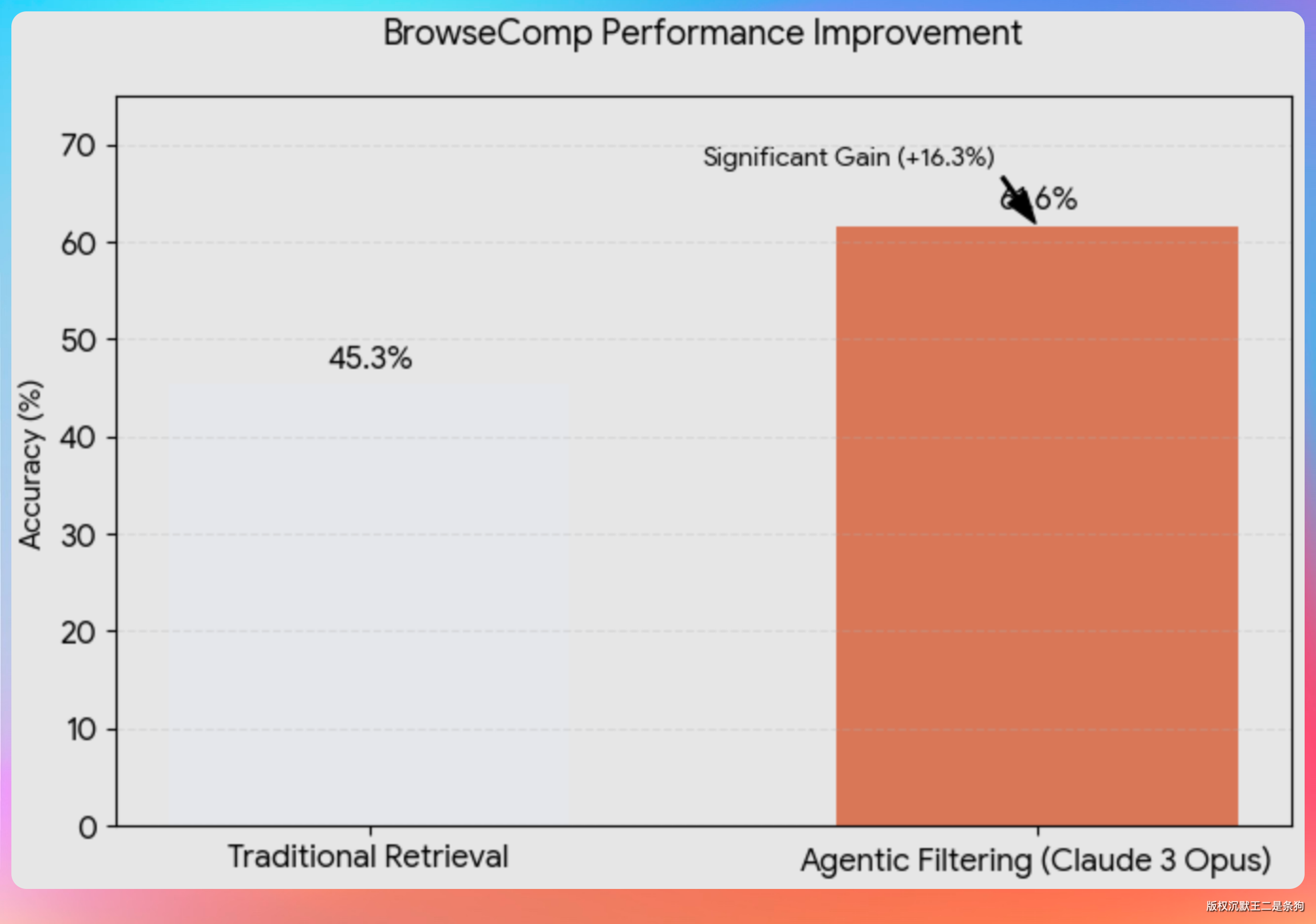
在 2024 年底的 SWE-bench Verified 基准测试上,Claude 用两个工具就拿到了 49% 的成绩——一个 bash 工具,一个文本编辑器工具。当时这是 SOTA 水平。
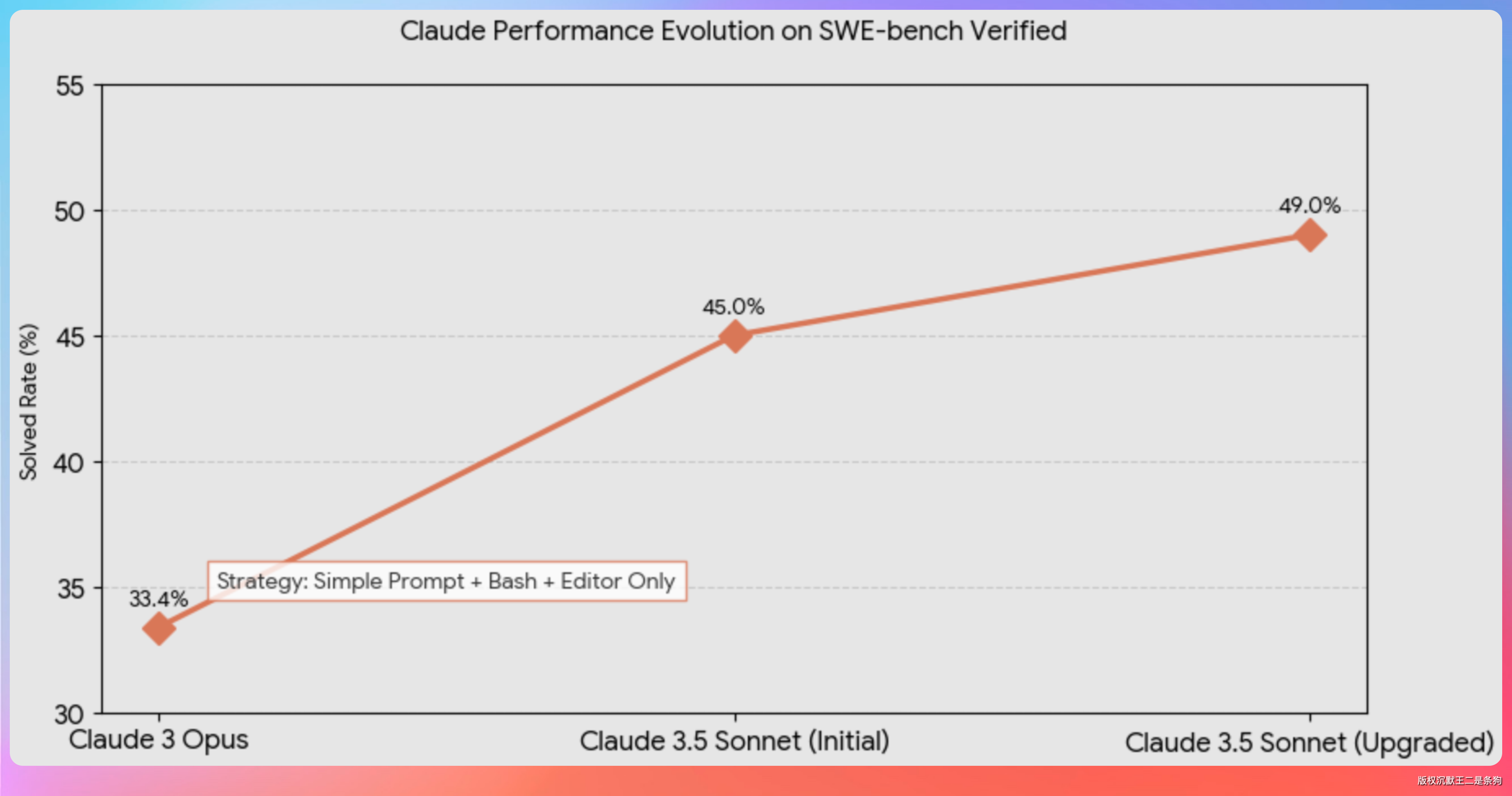
这个数字背后的含义是:Claude 对 bash 的使用已经非常成熟,bash 能做的事远比大多数人想象的多。
文件操作、网络请求、数据处理、代码执行,一条 bash 命令往往能搞定一个复杂的子任务。
反过来看,这也说明 Anthropic 在过去几年里在代码能力上投入很重。模型能写 bash,能理解执行结果,能根据报错调整策略,这不是一蹴而就的,是一点一点打磨出来的。
所以 Anthropic 在设计默认工具集的时候,没有上来就搞一堆专用工具,而是把 bash 和文件操作打包进 agent_toolset_20260401,作为最基础的能力块。其他工具按需选配。
把决策权还给模型
这是我觉得最有技术深度的一个设计决策。
很多 Harness 会偷偷塞进去一些“Claude 自己做不了”的假设,但随着模型能力提升,这些假设需要被重新检验。
最典型的一个假设是:每个工具调用的结果都必须先经过 Claude 的上下文窗口,Claude 才能决定下一步怎么走。
听起来理所当然,但这其实是一种浪费——很多结果只是中间产物,需要塞给下一个工具用,Claude 根本不需要看;很多结果的体积巨大,Claude 只关心其中一小段,把整段塞进窗口又慢又贵。
那怎么办?
给 Claude 一个 bash 工具。Claude 自己写代码,自己决定哪些结果要看、哪些直接管道传给下一个调用、哪些过滤掉只留摘要。只有最终输出才进入上下文窗口,编排逻辑从 Harness 转移到了模型本身。
Skills 也是同一个思路的产物。每个 Skill 的 YAML 头部是一段简短描述,会被预加载到上下文里,但 Skill 的完整内容不加载。Claude 看到这段描述之后,自己判断“这个 Skill 我现在用得上”,然后主动调用读取文件工具去把完整内容拉进来。用得到才加载,这就是渐进式展开。
把决策权还给模型,这句话看着简单,但背后是 Anthropic 对模型能力边界的持续重新评估。
边界要谨慎设,但该设的地方一定要设
前两个原则说的是“把权力还给模型”,第三个说的是“什么时候不能还”。
bash 工具给了 Claude 很大的自由度,但它对 Harness 来说就是一个字符串——每个操作的形状都一样,Harness 看不出 Claude 是在删文件还是在读日志。
如果某些操作需要做审计、做权限拦截、做用户确认,那就必须把它们提升为专用工具,让 Harness 拿到带类型的参数,能拦截、能渲染、能记录。
Claude Code 的自动模式(Auto Mode)是这个原则的一个有趣实现——让另一个 Claude 来读 bash 命令字符串,判断这条命令安不安全。一个 Claude 干活,另一个 Claude 看着,互相牵制。
这套“用 AI 监督 AI”的思路,在 Managed Agents 里也有体现。权限作用域(Scope)是执行追踪(Execution Trace)的配合方:Scope 决定 Agent 能做什么,Trace 记录 Agent 做了什么,两者合起来才能在事后说清楚“Agent 在这次任务里干了哪些事、有没有越界”。
对企业客户来说,这个可审计能力是合规的前提。没有 Trace,Agent 就是一个黑盒;有了 Trace,Agent 的每一步都有据可查。
这三个原则放在一起,体现的是 Anthropic 对 Harness 设计哲学的完整表达:能让模型自己决定的,就让模型决定;必须由基础设施把关的,绝不手软。
04、还在 Research Preview 的三块
Claude Managed Agents 目前已经全面公测,但有三个高级能力还处于 research preview 阶段,需要单独申请:
Outcomes(结果评估) 可以让你定义 Agent 任务的成功标准,平台会自动评估每次执行是否达成目标。这对于构建可度量的 Agent 流水线很关键。
Multiagent(多 Agent 协调) 是主 Agent 派生子 Agent 并行干活的能力。一个主 Agent 把任务拆解成多个子任务,每个子 Agent 负责一个,跑完汇总。
Notion 那个案例里提到“数十个任务并行”,底层依赖的就是这个。
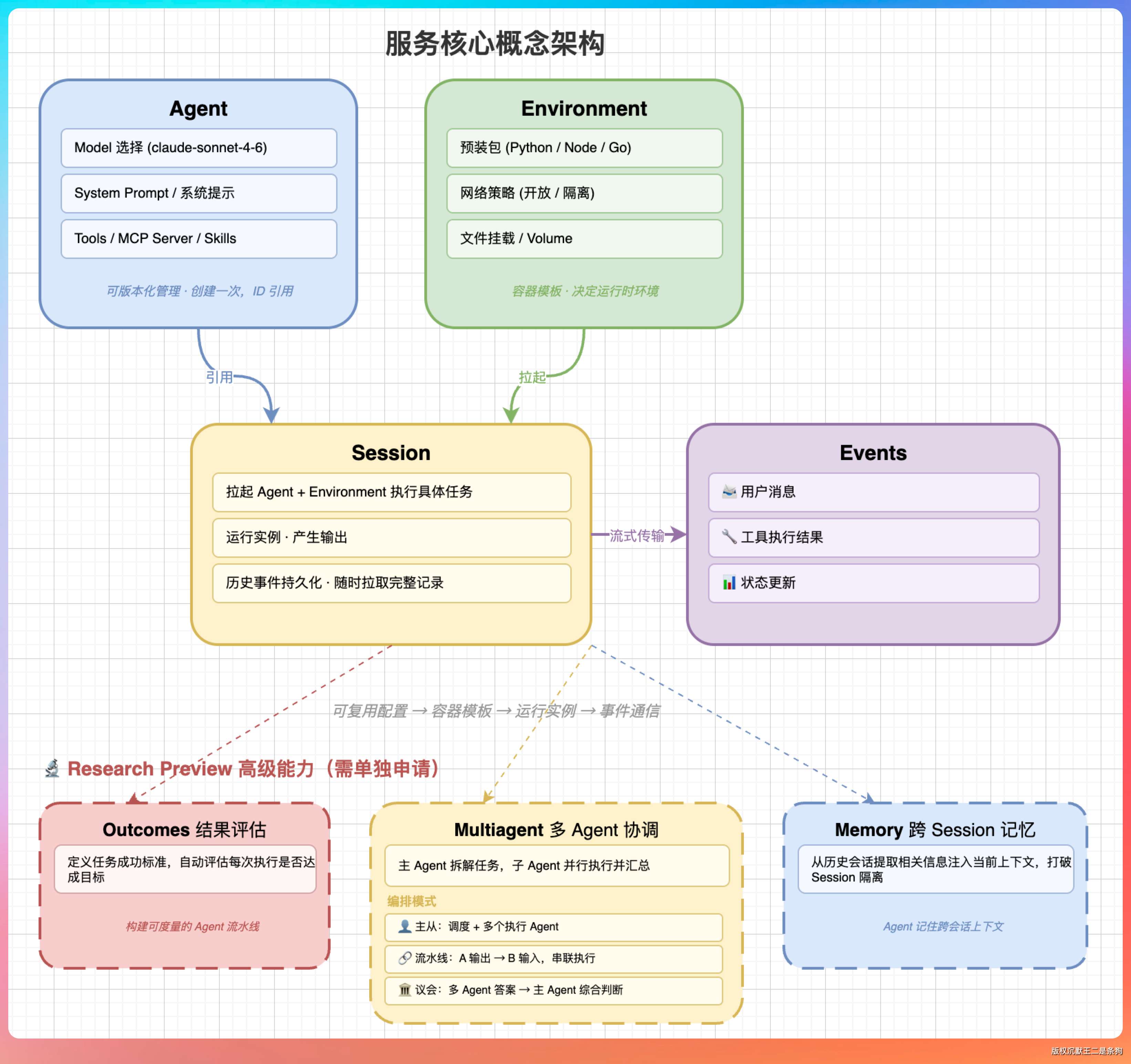
多 Agent 的编排模式有几种玩法:一个调度 Agent + 多个执行 Agent,这是最常见的主从结构;也可以是流水线结构——Agent A 的输出作为 Agent B 的输入,串联下去;还可以是议会结构——多个 Agent 对同一个问题分别生成答案,再由主 Agent 做综合判断。
Memory(跨 Session 记忆) 是让 Agent 记住跨会话上下文的能力。默认情况下每个 Session 的上下文是独立的,开了 Memory 之后,Agent 可以从历史会话里提取相关信息注入当前上下文。
讲真,Multiagent 和 Memory 这两块是整个产品最有想象力的地方,等正式开放,Agent 应用的天花板又要往上走一截。
05、真实客户说了什么
Anthropic 这次发布带了一组分量很重的客户案例,我挑几个细节说说。
Notion 把 Claude 直接集成进了工作空间,让团队可以把任务“派单”给 Claude(目前在 Notion Custom Agents 私有 alpha 阶段)。
工程师用它写代码,知识工作者用它生成网站和演示文稿,数十个任务可以并行跑。
Notion 产品经理 Eric Liu 的原话是:Managed Agents 能处理长会话、管理记忆、长期稳定交付高质量输出。
最直白的数据来自 Vibecode。Vibecode 帮客户把一段提示词变成一个部署好的 App,核心交付路径就是 Managed Agents。
在 Managed Agents 出现之前,用户必须手动在沙箱里跑 LLM、管理生命周期、配齐工具、监督执行,整个过程要花几周到几个月才能搭起来。现在只需要几行代码,用户启动同样的基础设施至少快 10 倍。
这个“快 10 倍”背后的逻辑其实很简单:原来搭一套完整的 Agent 基础设施,要写 Docker Compose、要处理凭证隔离、要实现状态持久化、要搞定断线恢复,每一项都是独立的工程任务。现在这些全部变成了 API 调用,从几百行基础设施代码变成了十几行业务代码。速度不快才奇怪。
ending
把上面这些信息消化一遍,再来看这次发布到底意味着什么。
商业定位变了,但不只是商业层面的事。
过去 Anthropic 提供的是模型 API,开发者按 token 付费。现在它提供的是完整的 Agent 运行环境:从沙箱、会话管理到权限控制,全部托管。
这个方向一旦确立,Anthropic 的 ARR 曲线可能会跟之前很不一样。
说真的,看到这个发布,我第一反应不是兴奋,是松了一口气。
选择 Managed Agents 还是自建 Harness,这是一道工程决策题。如果你的 Agent 任务很标准,对延迟和成本没有极致要求,直接用托管服务省时省力;如果你的场景很特殊,需要精细控制每一步,或者对数据安全有严格要求不能上云,自建 Harness 才是正路。两条路都有人走,关键是想清楚自己的场景再做选择。
【真正改变行业的,不是更聪明的模型,而是更稳的环境。】
Agent 时代的基础设施战争,Anthropic 打响了第一枪。
我们下期见。


回复