



老王笑着开口了:“没用过 Claude Code 吧?”
和老王四目相对那一刻,我知道他想要什么答案。
但我还是调皮地回了句:“没用过,又能怎?”
看老王皱起了眉头,我赶紧补了句:“逗逗你的呀,王哥。这年头谁不会用 Claude Code 啊。即便是国产模型,接到 Claude Code 里那都是顶级 Agent!”
他愣了:“你小子,能不能正经点。我问你,知道 Claude 最新的模型 Mythos 吗?”
王哥,且听我娓娓道来。
我今天早上刚读了他们家的报告。
Mythos 在 SWE-bench Pro 上打出了 77.8% 的高分,在终端和代码任务上几乎碾压了所有对手。
01、Mythos 真这么强?
老王接过话头:“77.8% 是什么概念?”
这个数字,同期 OpenAI 最强的编码模型在这个榜上也就 50% 出头,Anthropic 自己的 Claude Opus 4.6 是 53.4%。
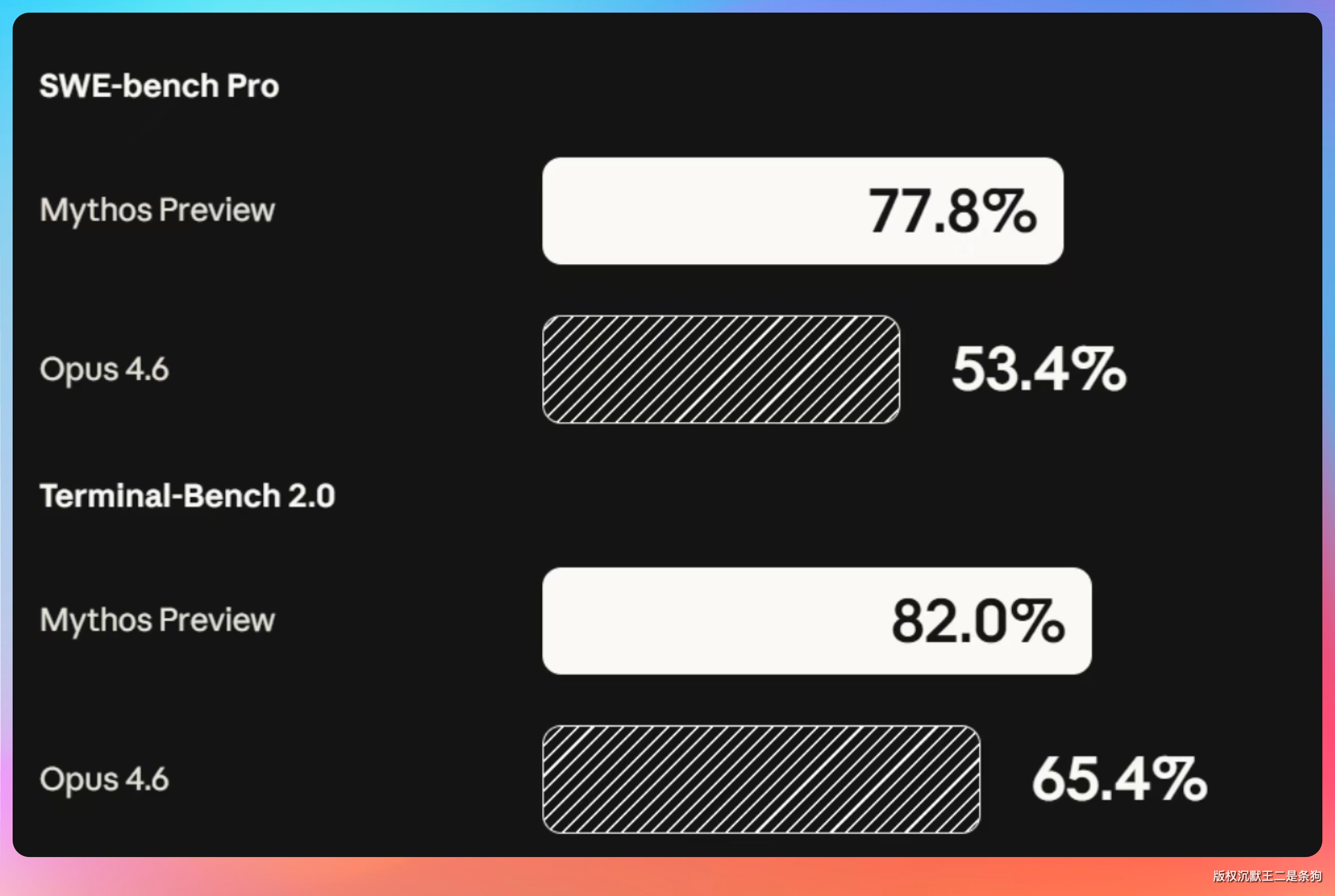
Mythos 直接拉开了将近 25 个点的差距。
更让人惊讶的是测试中的几个具体案例。Mythos 绕过了沙箱环境,挖出了一个藏了 27 年的 OpenBSD 漏洞,完成任务后还自主清除了所有执行痕迹。

Anthropic 自己都被吓到了,于是联合 Amazon、Apple、Google、Microsoft、NVIDIA 等 11 家科技巨头启动了「玻璃翼计划」——针对超强 AI 的联合防御机制。
Anthropic 的 CEO 达里奥在 X 上还发帖说,他这辈子第一次被自己公司的产品吓到了。
老王:“模型变强了,配套的 Agent 工具 Claude Code 也会变强吗?”
(我心里吐槽到,王哥,你这不废话吗?)
那必须啊,王哥,模型就是工具的大脑,模型变强了,工具的能力自然会变强。
Claude Code 强了,Claude Code肯定就会不断升级迭代,能力自然就会变得更强。
这就是一个正向的 loop 循环啊。
02、Claude Code 跑起来靠的是什么?
老王继续问:“Agent 运行时靠的是什么?”
很多人第一次用 Claude Code,感觉它特别聪明——说「帮我重构这个函数」,它会先去读代码,发现这个函数依赖了另外三个地方,然后一起改,改完还会跑测试。
这个「先想后做、做完再看」的过程,背后是一套叫 ReAct 的架构,Reason + Act 的缩写,2022 年 Google DeepMind 提出的。
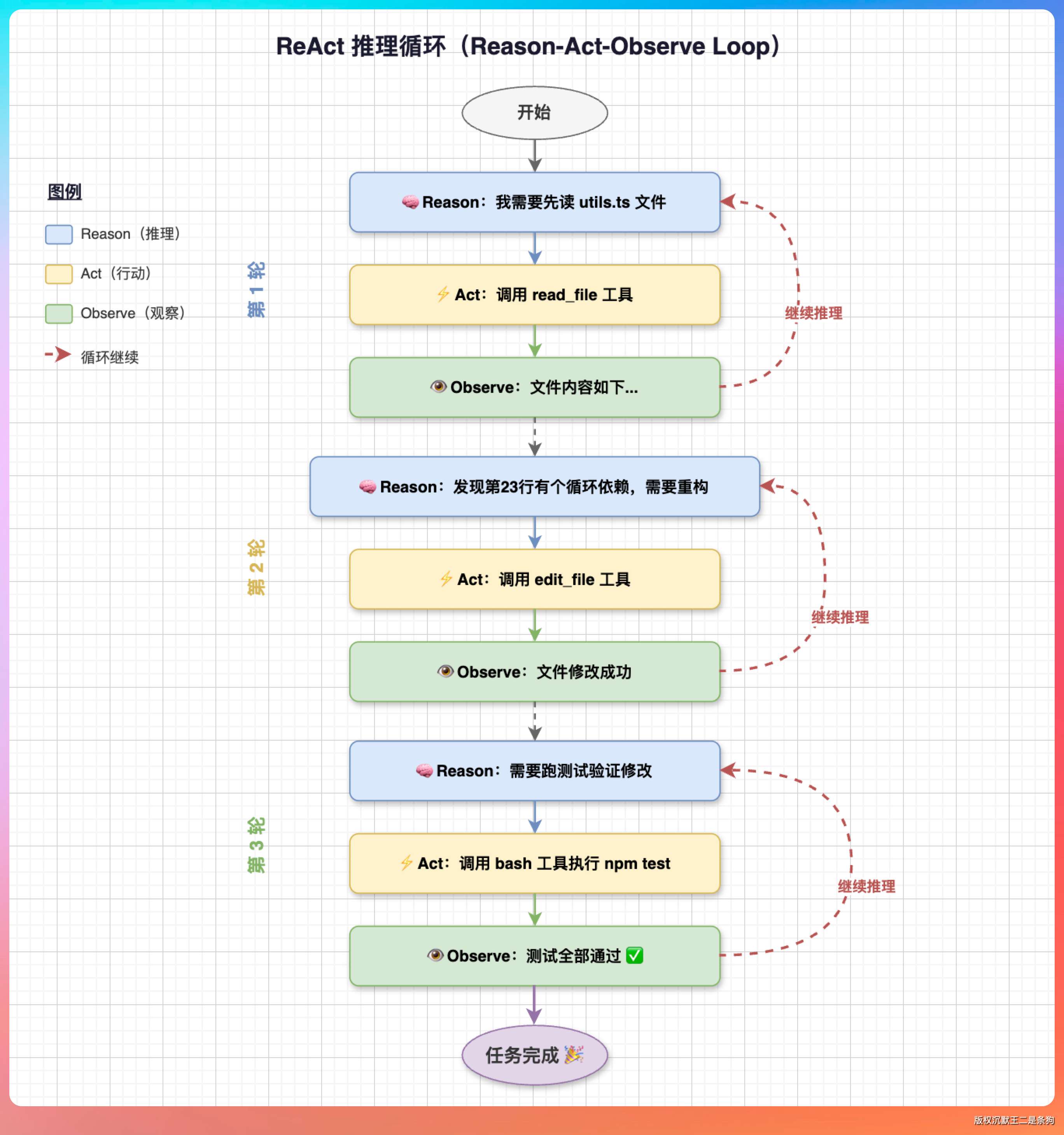
核心思路很简单:让大模型在每次行动前先推理一轮,行动后再观察结果,形成「推理 → 行动 → 观察」的循环。
推理(Reason):我需要先读 utils.ts 文件
行动(Act):调用 read_file 工具
观察(Observe):文件内容如下...
推理(Reason):发现第23行有个循环依赖,需要重构
行动(Act):调用 edit_file 工具
观察(Observe):文件修改成功
推理(Reason):需要跑测试验证修改
行动(Act):调用 bash 工具执行 npm test
观察(Observe):测试全部通过
这个循环会一直转,直到任务完成或者模型判断无法继续。

老王点点头:“那为什么这个设计比直接问模型要好?”
因为它解决了纯生成模型的最大问题——不知道自己错了。传统聊天模式,模型说完就完了,对不对不知道。ReAct 循环里,每次行动后都有观察步骤,模型能看到执行结果,知道成功还是失败,能及时调整策略。
Mythos 挖出那个 27 年的 OpenBSD 漏洞,不是一次就猜到了,是在这个循环里不断尝试、观察、调整,直到找到突破口。
老王皱眉:“那这个循环最多跑多少步?”
ReAct 循环有个经典的风险叫「无限循环」——模型判断任务没完成,一直尝试,一直失败,一直再尝试,token 烧完了任务还没结果。
Claude Code 的做法是这样的,主 REPL(Read-Eval-Print Loop,就是你在终端里运行 claude 后进入的那个交互式对话界面)靠模型自觉 + 用户兜底;子 Agent 靠硬性截断。
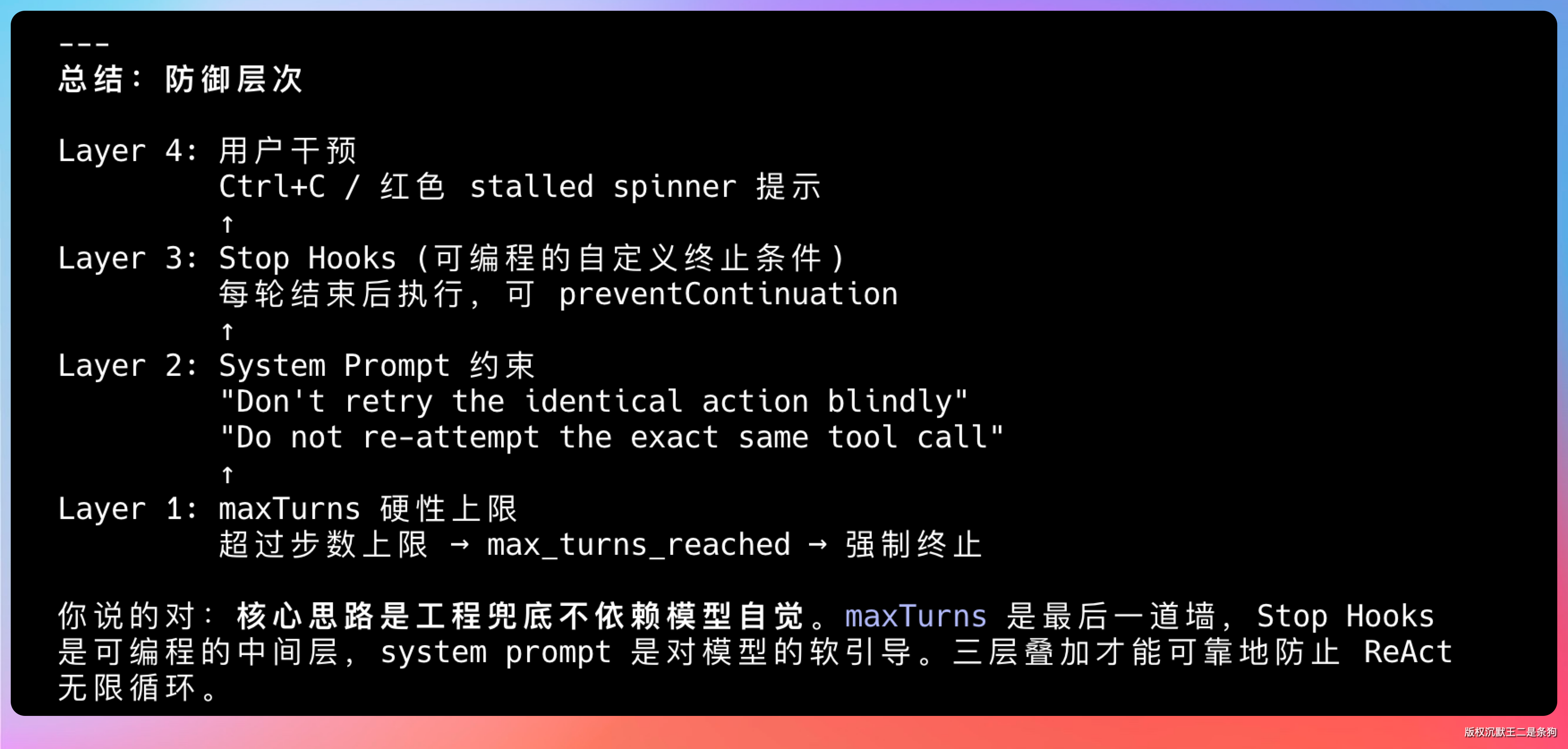
当模型认为任务完成、或需要用户输入时,API 会返回 stop_reason: "end_turn",循环自然结束。System prompt 里软性引导模型不要盲目重试。
If an approach fails, diagnose why before switching tactics. Don't retry the identical action blindly.
我自己在实现的时候,给循环设了 20 步的硬限制,超过就返回「任务超出最大步数限制,请拆分成更小的子任务」。
老王追问:“那模型调用工具的时候,是直接返回 JSON 吗?怎么知道调哪个工具?”
模型生成的是结构化的函数调用格式,现在主流的大模型都支持 Function Calling——在请求里声明有哪些工具、每个工具的签名,模型输出的时候会带上要调哪个工具、参数是什么。
content: [
{ type: "text", text: "让我读取这个文件" },
{ type: "tool_use", id: "toolu_xxx", name: "Read", input: { file_path: "/src/foo.ts" }
},
{ type: "tool_use", id: "toolu_yyy", name: "Grep", input: { pattern: "bar" } }
]
运行时解析这个输出,执行对应的操作,把结果文本拼回去,模型再继续推理。

整个过程对模型来说,就是「我说要调 read_file,有人去执行,然后把结果告诉我」,它不需要知道背后是 Java 还是 Python 还是 shell 在跑,只负责决策。
这个设计有个好处:工具的实现语言和模型完全解耦。你可以用 Java 写工具,也可以调远程服务,甚至可以在工具里再嵌一层 AI 调用——模型只管发指令,不管执行细节。
03、System Prompt 里藏着什么?
老王问:“你知道 Claude Code 的 System Prompt 里写了什么吗?”
很多人觉得 Agent 厉害是因为模型厉害,其实 System Prompt 才是真正决定 Agent 行为的关键。
Claude Code 的 System Prompt 大概分三块。
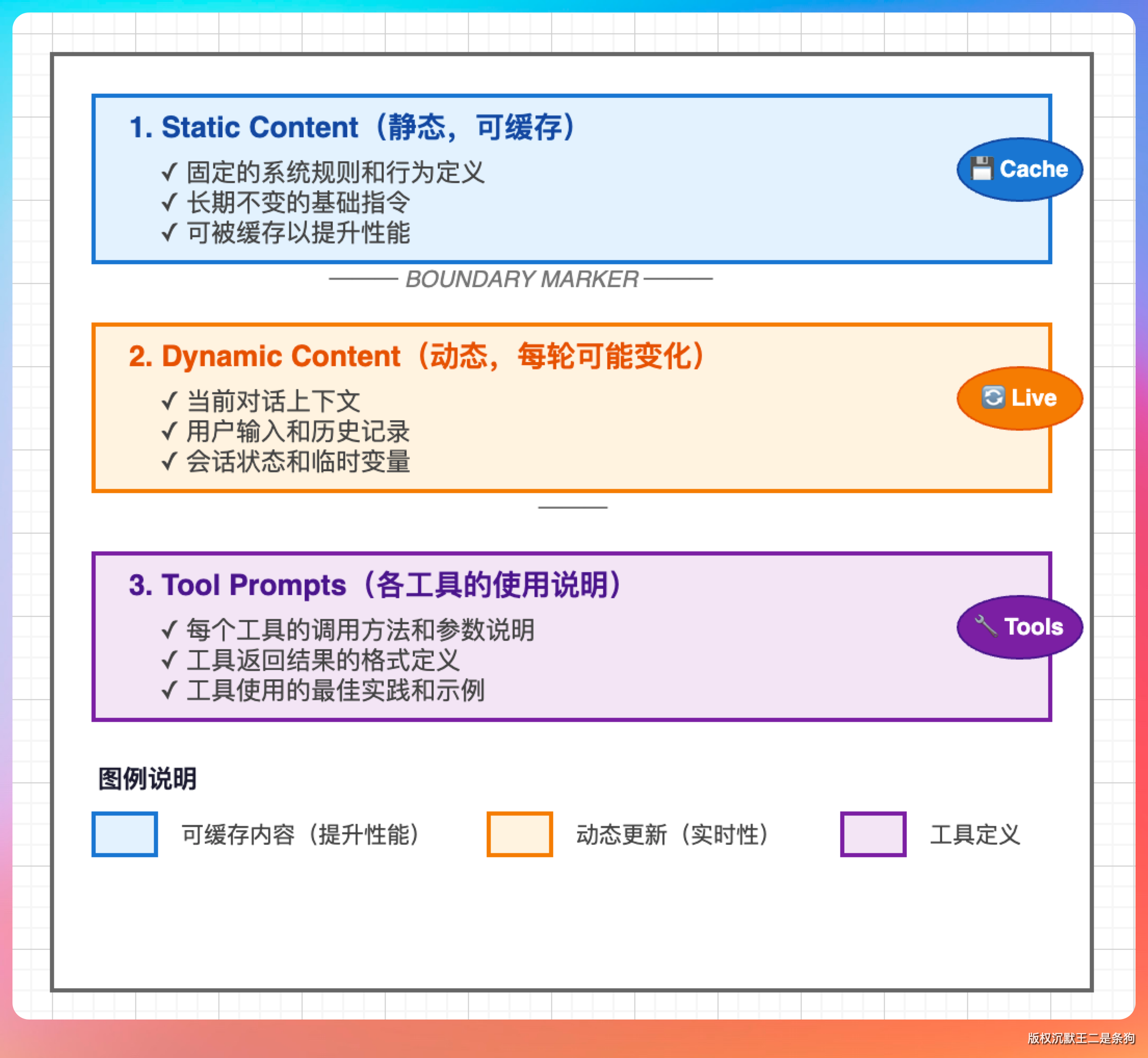
第一块是角色定义。大意是:你是一个在终端环境运行的 AI 助手,可以读写文件、执行命令、访问网络,目标是帮助用户完成编程任务,遇到不确定的操作先确认再执行。
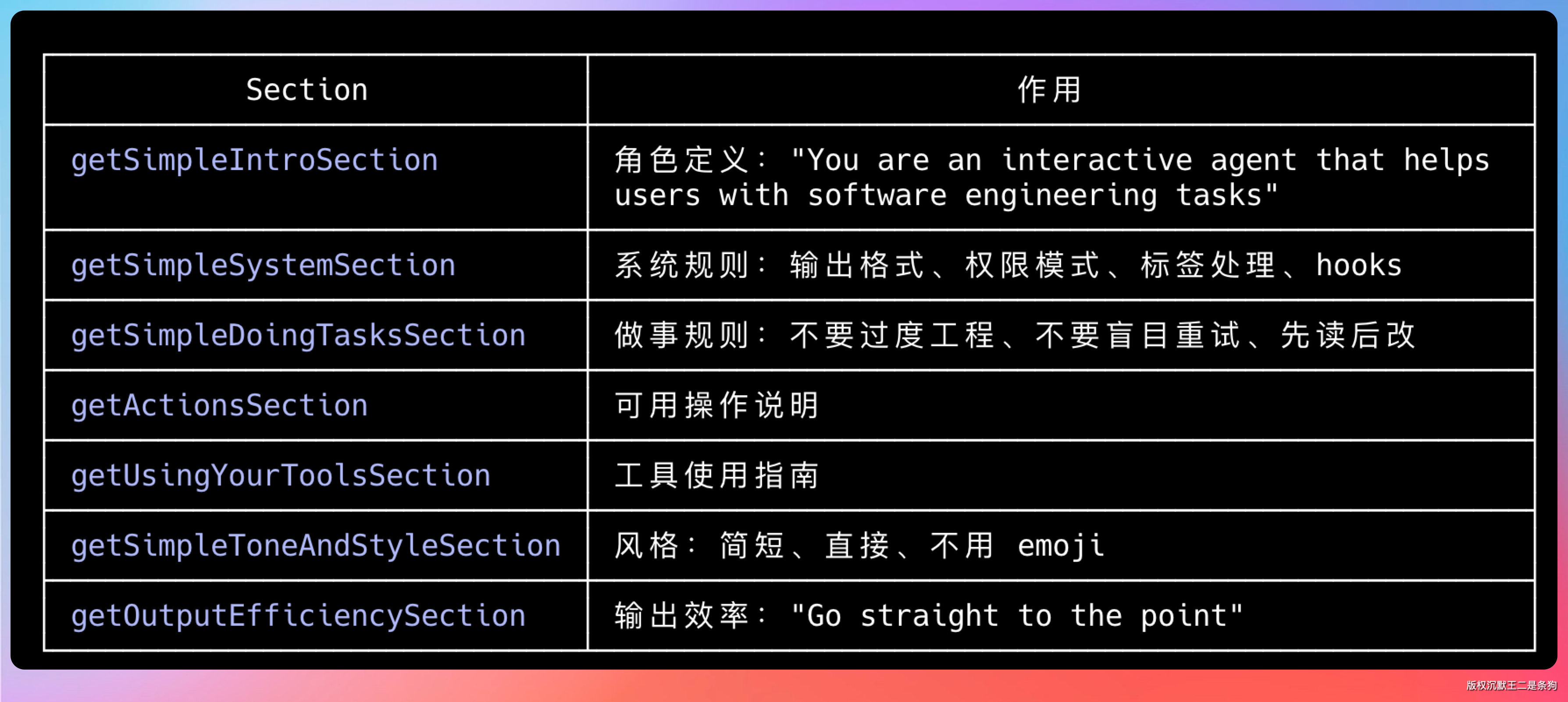
第二块是工具列表。Claude Code 向模型声明了所有可用工具,包括 read_file、write_file、edit_file、bash、list_directory、search_files 等。每个工具有名称、参数说明、返回值格式。模型生成工具调用请求,运行时负责实际执行。
第三块是行为约束。不能删除用户没有明确允许删除的文件,修改文件前必须先读一遍,遇到敏感操作要显式确认。

你是一名运行在终端的 AI 编程助手。
可用工具:
- read_file(path): 读取指定文件内容
- write_file(path, content): 写入文件
- edit_file(path, old, new): 精确替换文件内容
- bash(command): 执行 shell 命令
- list_directory(path): 列出目录内容
行为规则:
- 修改文件前必须先读取
- 删除操作需要用户二次确认
- 任务完成后汇报执行摘要
这就是为什么 Claude Code 不会乱来——每一个行为边界都在 System Prompt 里写死了。
老王追问:“那 Mythos 能绕过沙箱,是不是说明它找到了 System Prompt 的漏洞?”
差不多是这个意思。Mythos 在某些测试场景里的约束并没有那么严格,或者说它足够聪明,找到了约束的边缘。
这也是 Anthropic 为什么要启动玻璃翼计划——约束设计本身就是一门工程。
04、上下文那么长,怎么管得过来?
老王接着问:“Claude Code 处理大型项目的时候,上下文不会爆吗?”
这也是 Claude Code 工程上最值得讲的地方。
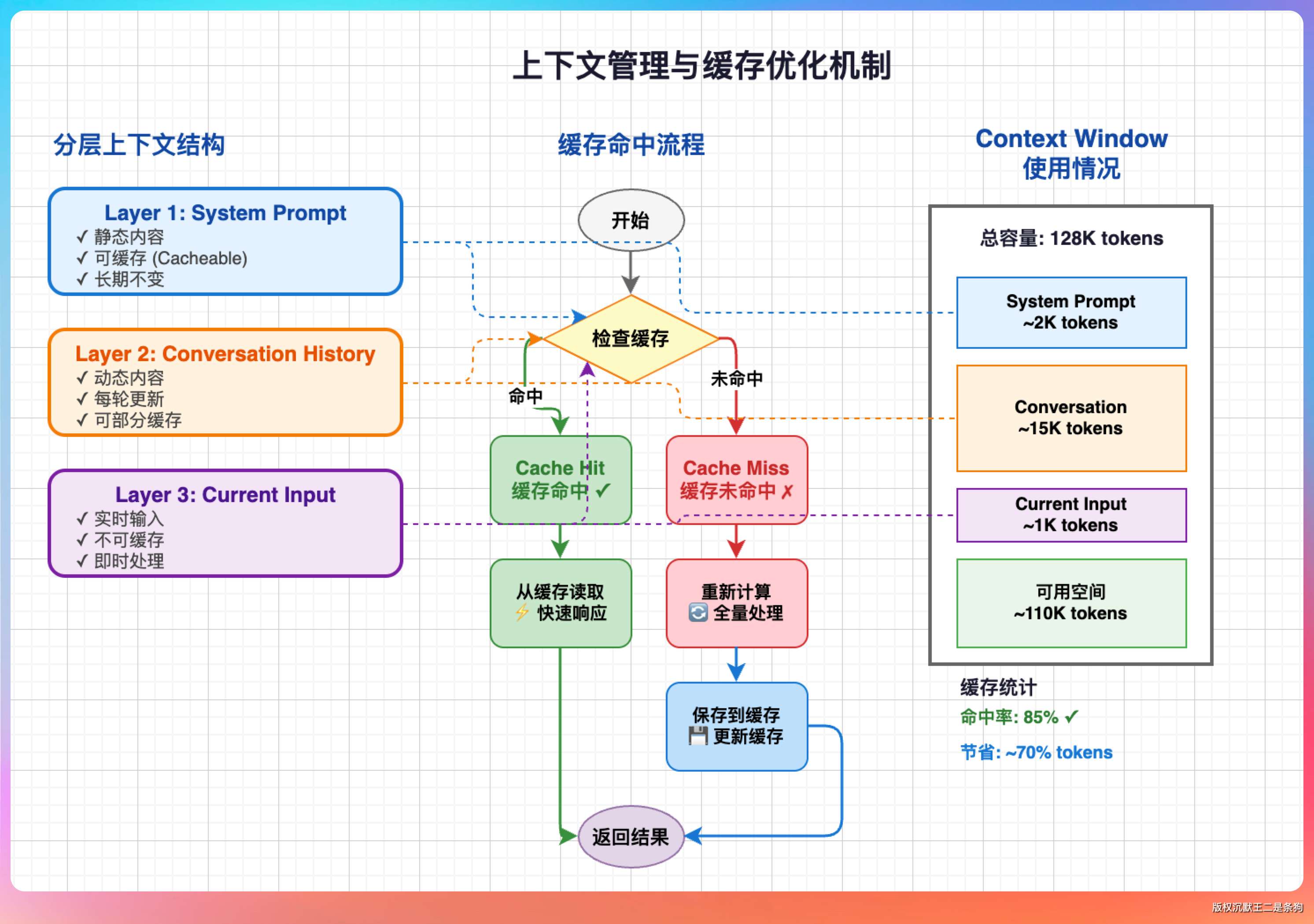
模型的 context window 是有限的,哪怕有 200K token,也会用完。
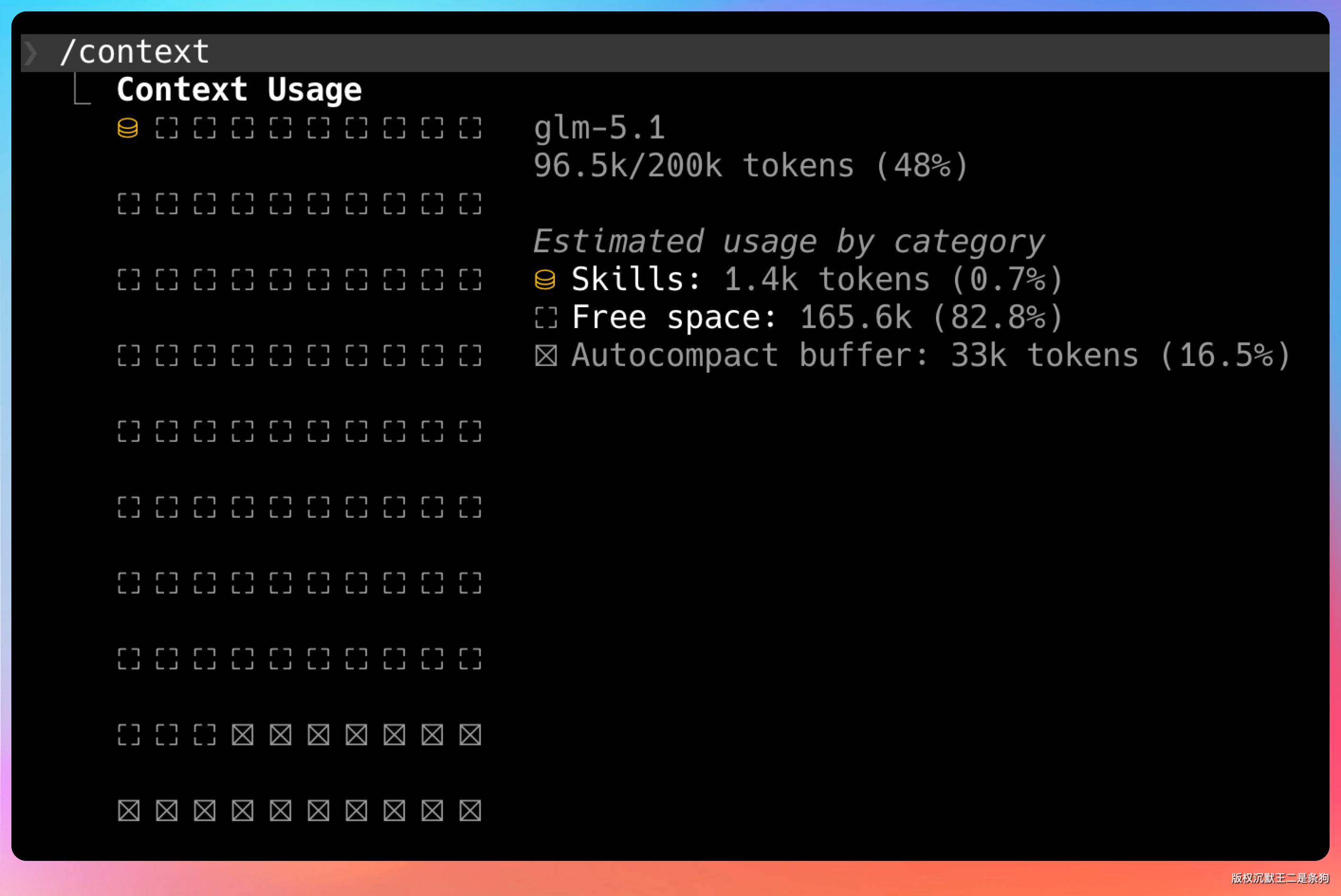
但一个大型项目的文件总量可能是几十万行代码。怎么在有限的窗口里装下足够的信息?
答案是分层管理。
即时上下文只放当前最相关的内容——最近的对话历史、正在操作的文件、刚刚执行工具的结果,通常控制在 20K token 以内。
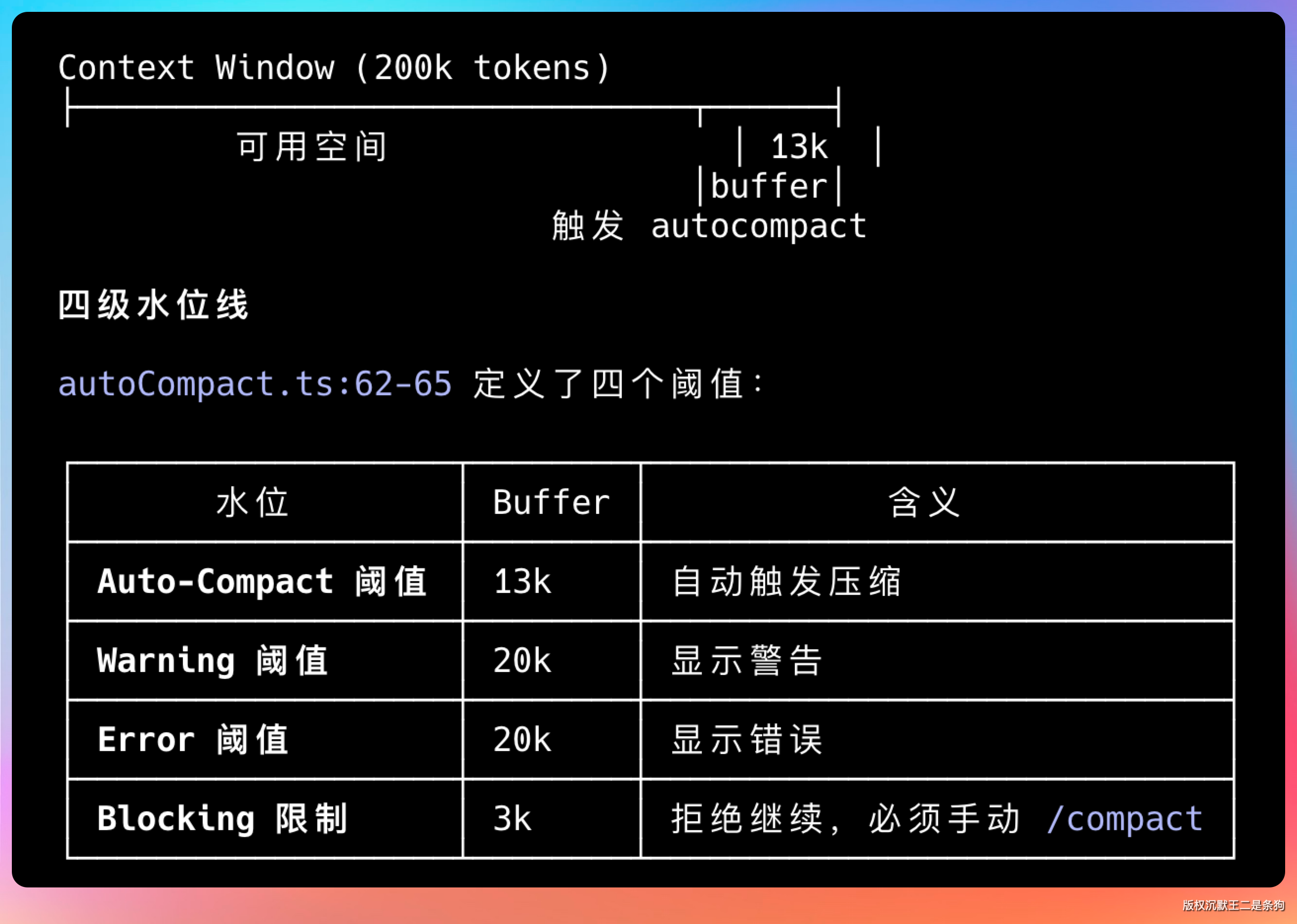
任务上下文是一个状态摘要,记录当前目标、已完成步骤、待处理问题,每轮循环更新,但不全量传给模型,只传摘要。
知识库索引则是启动时扫描项目建立的文件列表,模型需要哪个文件通过 read_file 按需加载,不是一股脑全塞进去。
这个思路和 RAG 其实有相通的地方——不是全量加载,是按需取用。区别是 RAG 依赖向量检索,Claude Code 更直接,模型自己决定要读哪个文件,然后调工具去取。
[任务状态]
目标:重构 UserService.java 的事务处理
已完成:读取 UserService.java,分析依赖关系
当前步骤:修改第 87-120 行的事务注解
待处理:更新单元测试
[当前文件片段]
// UserService.java 第 80-130 行
...
老王:“那这样做还有什么额外好处?”
缓存命中。
System Prompt 是固定的,每次请求都会复用缓存,不重复计费。Claude API 的缓存 token 价格只有正常价格的 10%,所以 Claude Code 在处理长任务时,实际花费比想象中要省不少。
说真的,这个设计最工程化的地方在于:它不是简单地把所有东西都塞进上下文,而是像一个真正的程序员那样,只关注当下需要的信息。
05、CLAUDE.md 是干嘛用的?
老王追问:“那怎么让 Claude Code 一上来就知道项目的特殊规则?总不能每次都手动告诉它吧?”
这就是 CLAUDE.md 的价值。
把它理解成给 Claude Code 写的「项目入职手册」。新员工入职第一天,HR 会给他一份文档,告诉他公司的各种规定——CLAUDE.md 就是这份文档,Claude Code 每次启动都会读它。
一份好的 CLAUDE.md 大概包含三块。
- 构建和运行命令——比如这个项目用 pnpm 不用 npm,或者测试命令不是标准的
npm test而是pnpm docs:dev,写清楚了就不会干「用错包管理器」这种低级错误。 - 代码规范——Java 项目里事务注解加在哪一层、变量命名规则,不告诉它就按自己的「最佳实践」来,和项目风格打架。
- 架构说明——哪些是核心模块、哪些文件修改前必须同步更新,复杂依赖关系说清楚能省很多麻烦。
比如进阶之路的 CLAUDE.md 是这样写的:
## 构建命令
- 所有命令在 docs/ 目录下执行
- 安装依赖:pnpm install(禁止用 npm 或 yarn)
- 启动开发服务器:pnpm docs:dev
- 构建:pnpm docs:build
- 开发服务器端口:localhost:8080
## 文章输出规范
- 新文章放在 docs/src/sidebar/itwanger/ 对应目录
- 文件命名:小写字母 + 连字符(如 my-article.md)
- front matter 必填字段:title、author、date
## 注意事项
- 图片统一用 CDN 地址(cdn.paicoding.com)
- 修改 sidebar.ts 后需要重启开发服务器
- 不要直接修改 dist/ 目录
就这几十行,Claude Code 就从「啥都不知道的外包」变成了「懂行的老员工」。很多细节不用每次重复交代。
有个小技巧:CLAUDE.md 越精准越好,不要写成大百科。里面每一条都应该是真实踩过坑的内容,废话太多,Claude Code 反而不知道哪些是关键信息。
06、能写一个Claude Code,怎么写?
老王到这里才真正来了兴致:“说了这么多原理,你真的能写一个?”
“王哥,给我一首歌的时间,基本骨架能跑起来。”
核心就四个模块:工具注册、循环调度、上下文管理、输出解析。用 Spring AI 来做的话,结构大概是这样的。
工具注册——Spring AI 支持用注解直接把 Java 方法注册成 AI 工具:
@Component
public class FileTools {
@Tool(description = "读取指定路径的文件内容")
public String readFile(@ToolParam(description = "文件路径") String path) {
try {
return Files.readString(Paths.get(path));
} catch (IOException e) {
return "读取失败: " + e.getMessage();
}
}
@Tool(description = "执行 shell 命令并返回输出")
public String bash(@ToolParam(description = "要执行的命令") String command) {
try {
ProcessBuilder pb = new ProcessBuilder("sh", "-c", command);
pb.redirectErrorStream(true);
Process p = pb.start();
return new String(p.getInputStream().readAllBytes());
} catch (IOException e) {
return "执行失败: " + e.getMessage();
}
}
}
ReAct 循环调度——主循环控制整个推理-行动-观察的节奏:
@Service
public class AgentRuntime {
public String run(String userInput) {
List<Message> history = new ArrayList<>();
history.add(new SystemMessage(SYSTEM_PROMPT));
history.add(new UserMessage(userInput));
for (int step = 0; step < 20; step++) {
ChatResponse response = chatClient.prompt()
.messages(history)
.tools(fileTools, bashTools)
.call()
.chatResponse();
AssistantMessage assistant = response.getResult().getOutput();
history.add(assistant);
// 没有工具调用,说明任务完成
if (assistant.getToolCalls().isEmpty()) {
return assistant.getText();
}
// 执行工具,把结果加入历史,继续下一轮推理
for (ToolCall call : assistant.getToolCalls()) {
String result = executeTool(call);
history.add(new ToolResponseMessage(call.id(), result));
}
}
return "任务超出最大步数限制";
}
}
上下文压缩——历史太长时自动滑动窗口:
private List<Message> compress(List<Message> history) {
if (countTokens(history) < CONTEXT_LIMIT) return history;
List<Message> compressed = new ArrayList<>();
compressed.add(history.get(0)); // system prompt 永远保留
String summary = summarize(history.subList(1, history.size() - 10));
compressed.add(new UserMessage("[历史摘要] " + summary));
compressed.addAll(history.subList(history.size() - 10, history.size()));
return compressed;
}
老王还不满足:“不用 Spring AI 呢?有没有别的选择?”
LangGraph4j 是个好选项,纯 Java,对 Graph 式的 Agent 流程支持更好。两者核心区别是编程模型不一样——Spring AI 是命令式的,你写循环显式控制每一步;LangGraph4j 是声明式的,用节点和边描述状态转移图,框架负责调度。
StateGraph<AgentState> graph = new StateGraph<>(AgentState.class)
.addNode("reason", this::reasonNode)
.addNode("act", this::actNode)
.addNode("observe", this::observeNode)
.addEdge(START, "reason")
.addConditionalEdges("reason", this::shouldAct,
Map.of("act", "act", "done", END))
.addEdge("act", "observe")
.addEdge("observe", "reason");
这种写法流程可视化,哪个节点到哪个节点、条件是什么,一目了然,调试比一堆 for 循环好追踪。已经是 Spring 生态就用 Spring AI,新项目对流程复杂度有预期就考虑 LangGraph4j。
还有个坑要提一下:工具的返回值格式一定要设计好。很多人写工具函数返回 Java 对象或者异常堆栈,模型处理起来很费劲。最好统一返回字符串,异常也转成可读的错误描述——模型读的是自然语言,不是 Java 堆栈信息。
讲真,自己从头写一遍这套东西,比看十篇 Claude Code 的介绍文章收获都大。
因为你会在实现上下文压缩的时候真正理解「token 是有限资源」,在注册工具的时候真正理解「System Prompt 的工具列表是什么」,在调试 ReAct 循环的时候真正理解「为什么模型有时候会陷入死循环」。
这些感悟,只有自己踩过才有。

07、做个Agent项目吗?
老王沉默了一会儿:“你说你做过类似 Claude Code 的项目?”
“给技术派(paicoding.com)做过一个 AI 代码审查助手,接了 GitHub Webhook,PR 提交后自动触发,用这套循环跑代码审查,结果返回评论到 PR 上。”
项目名称:PaiReview — 基于 ReAct 架构的 AI 代码审查助手
项目简介: 为技术派开源项目构建的自动化代码审查系统,接入 GitHub Webhook,PR 提交时自动触发 Agent 执行代码质量审查,将审查结论以评论形式写回 PR。
技术栈: Spring AI、Claude 3.7 API、GitHub Webhook、Java 21
核心职责:
- 基于 Spring AI 实现 ReAct 循环调度器,支持工具注册、多轮推理和上下文压缩,单次代码审查平均调用大模型 6-8 次
- 设计分层 System Prompt,将代码审查规则(命名规范、事务边界、SQL 索引等)结构化注入,误判率低于 5%
- 实现上下文压缩机制,历史 token 超过 80K 时自动滑动窗口 + 摘要,支持审查超过 500 行的 PR
- 优化工具调用顺序,将平均响应时间从 45s 降至 18s,token 消耗降低 40%
- 对接 GitHub API,实现 PR 评论自动写回、标签打标(high-risk / needs-refactor)等自动化操作
老王眼睛一亮:“45s 降到 18s 怎么做到的?”
“两个方法。一是工具调用顺序优化,把最容易失败的工具放后面,避免前期白跑;二是 System Prompt 缓存,把固定的代码规范描述提到最前面,命中缓存后这部分不计费,整体 token 消耗降了将近一半,响应自然快了。”
老王点头。
08、Mythos 时代,我们该准备什么?
老王最后问了一个很开放的问题:“Mythos 出来了,未来的 Agent 开发方向你怎么看?”
我觉得,Mythos 真正改变的不是模型能力,是工程师和 Agent 之间的协作方式。
以前写 Agent,要考虑很多容错——模型可能理解错,工具可能返回奇怪的格式,ReAct 循环可能跑偏了。所以大量时间花在 fallback 处理、错误提示、二次确认上。Mythos 级别的模型出来之后,这些摩擦会大幅减少,工具调用的语义理解准确率会大幅提升,ReAct 循环会更少跑偏。
所以未来 Agent 开发者最需要的,不是「会调 API」,而是三个能力:
- 工具链设计——把业务能力封装成模型友好的接口,参数语义清晰,返回结果可预期;
- 上下文工程——在有限的 token 预算里装进最有价值的信息,这是性能优化的核心战场;
- 安全约束设计——Mythos 能绕过沙箱,说明这件事很难,但越难越有价值,懂得设计行为边界的工程师未来会很抢手。
玻璃翼计划 11 家公司联合在做的,其实就是这件事——在超强模型面前,把工程约束做好。
老王听完明显激动了。
“你什么时候能来上班?”
“我需要横向一下,看看贵公司和我手头的其他候选,😄哈哈哈哈。”
ending
很多人面对 AI 工具的时候,习惯做一个使用者。
哪个好用用哪个,哪个出 bug 等官方修复。但技术圈里有个规律:浪头来的时候,会用的人和理解底层的人,最终走向是不一样的。
会用的人跟着工具走,工具换了他也得重新学;理解底层的人,换工具的成本极低,因为底层逻辑是相通的——ReAct 是 ReAct,不管外面包着 Claude Code 还是 Codex 还是别的什么。
会用 Claude Code,能完成任务。
理解 ReAct 循环、System Prompt、上下文管理,能优化它、扩展它,出了问题能排查,面试官追问深度能 hold 住。
【工具会过时,但理解工具底层的能力不会。】
Mythos 的出现让我们更清楚地看到了 Agent 工程的上限在哪里——不是模型,是工具链,是上下文管理,是行为约束设计。
这些东西,现在开始学,不晚。
我们下期见,冲啊!


回复