



大家好,我是二哥呀。
虽然只是一个小版本,但经过两天的高强度使用,GLM-5.1 给我的感受远不是 0.1 这个数字所能表达的。
他在长时间跨度、长链路依赖、多工具协同、强目标一致等关键能力上都令我印象深刻,仿佛吃了仙丹一样,Coding 方面的进化远超我的预期。
下面是我用 GLM-5.1 从 0 到 1 完成的一个 AI 智能简历生成 Agent——派简历的完整录屏测试。
咱们直接上实战。
系好安全带,咱们滴滴滴出发~
01、给 CC 配置 GLM-5.1
先确保你的 Claude Code 已经正确切换到了 GLM-5.1 模型。
编辑 Claude Code 的配置文件,把模型名称调整为 glm-5.1 就可以。
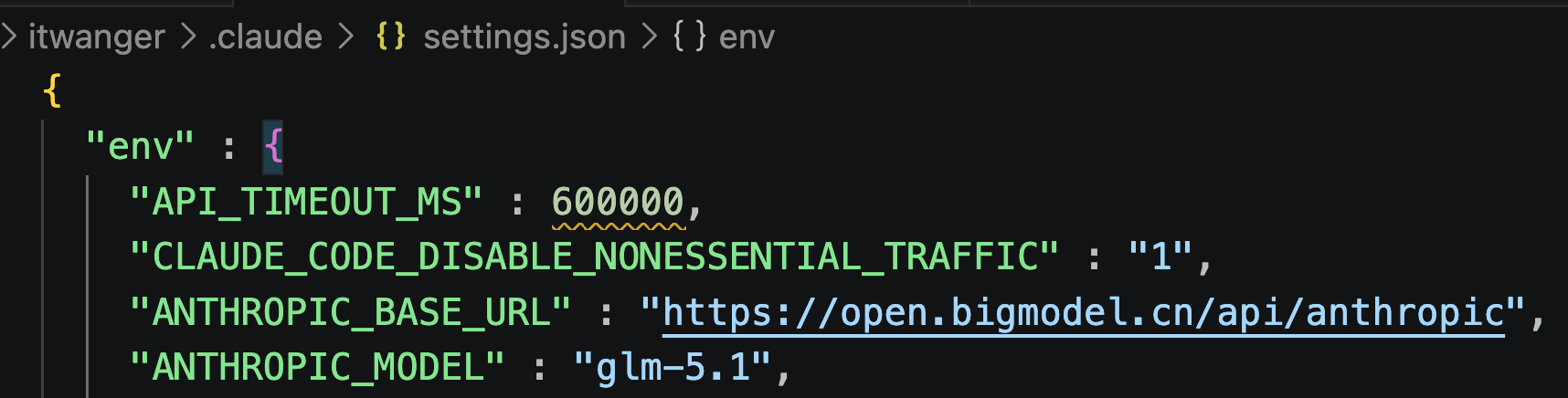
然后重启 Claude Code。
02、启用 MCP 操控浏览器
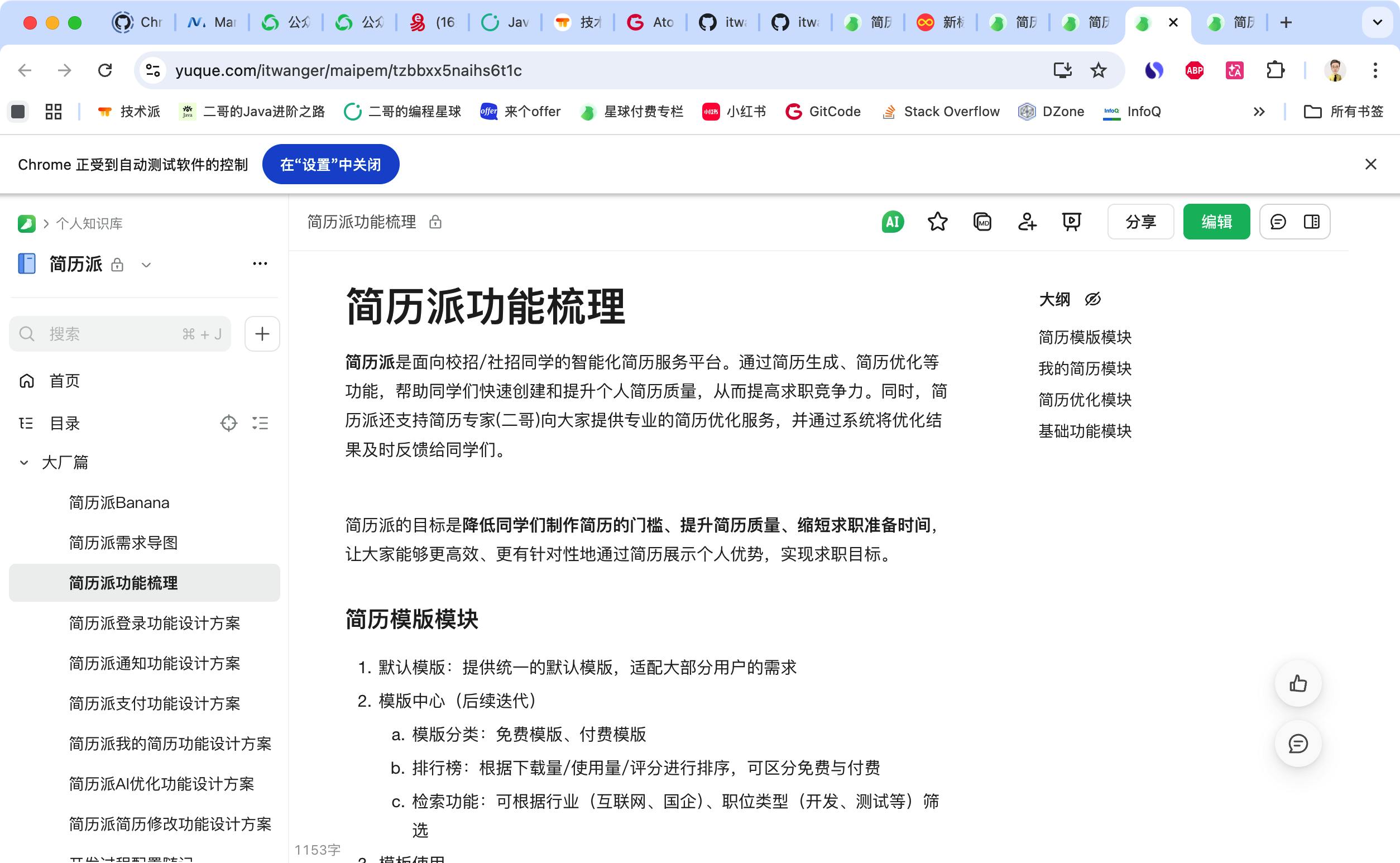
直接上测试,先调用 Chrome Devtools 打开我们的浏览器,通读一下语雀上我沉淀的需求文档。
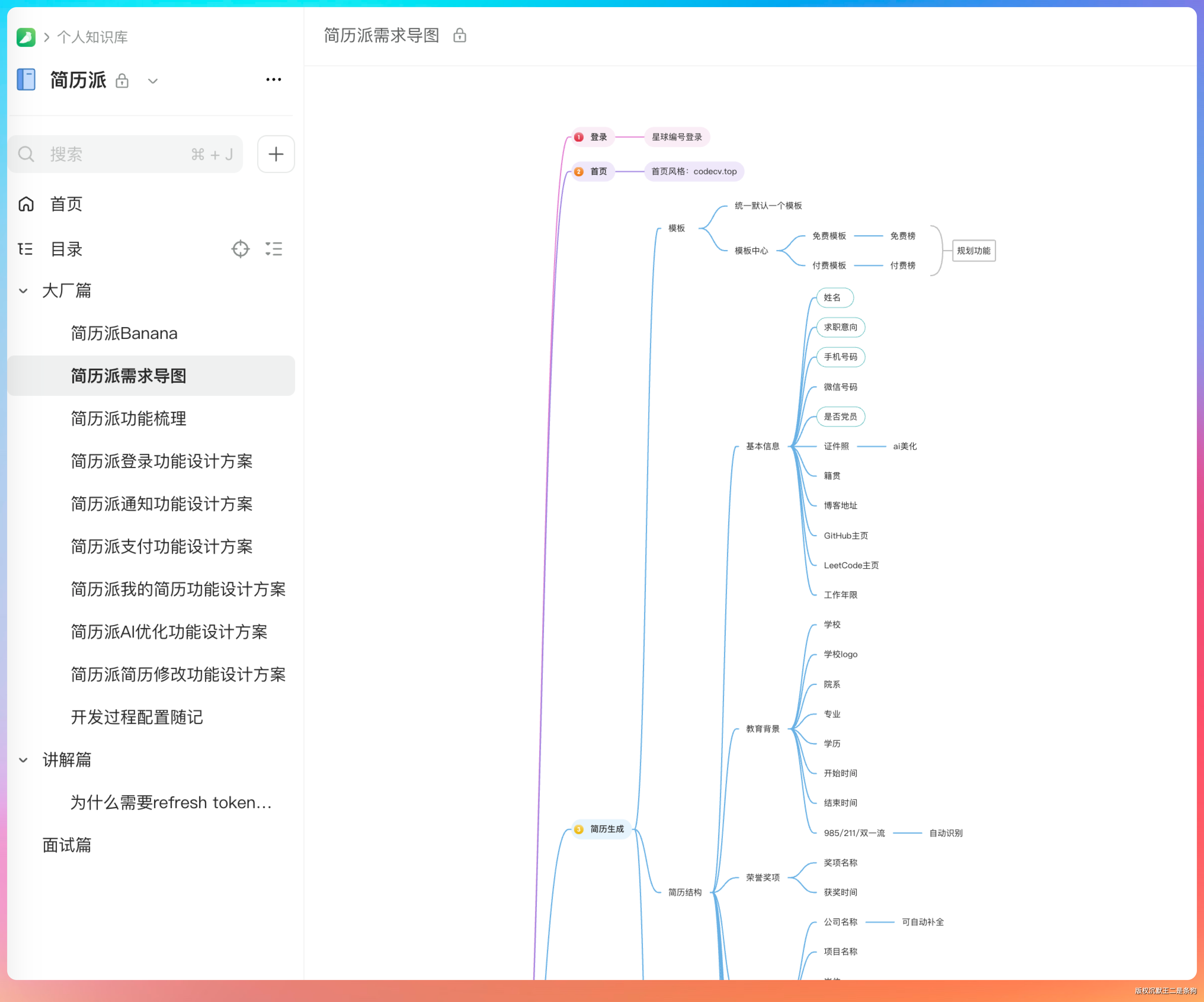
这份知识库的内容可不少。
提示词:我现在要重构一下这个项目,我们要启用 plan 模式,首先我有一份语雀文档,你先用 Chrome 打开通读一下:https://www.yuque.com/itwanger/maipem/cc15r3paz9onkz3c?singleDoc# 《简历派支付功能设计方案》 密码
Claude Code 会使用 Chrome Devtools MCP 打开浏览器,我直接把这个 MCP 工具加载到配置了,省得每次都要问我要权限。
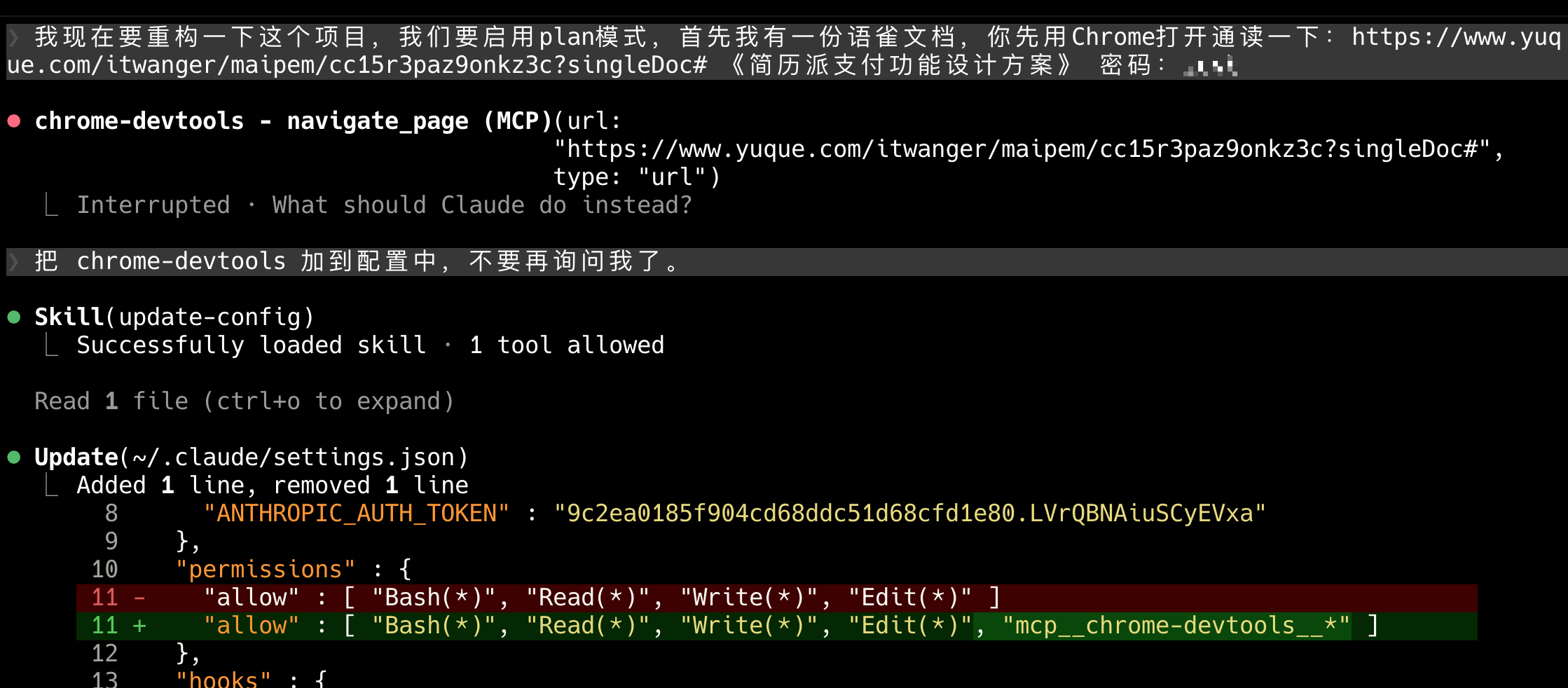
需要输入密码,可以直接告诉在 CC 中告诉他,也可以直接在浏览器里输入。完事后,模型就开始自动读取文档内容了。
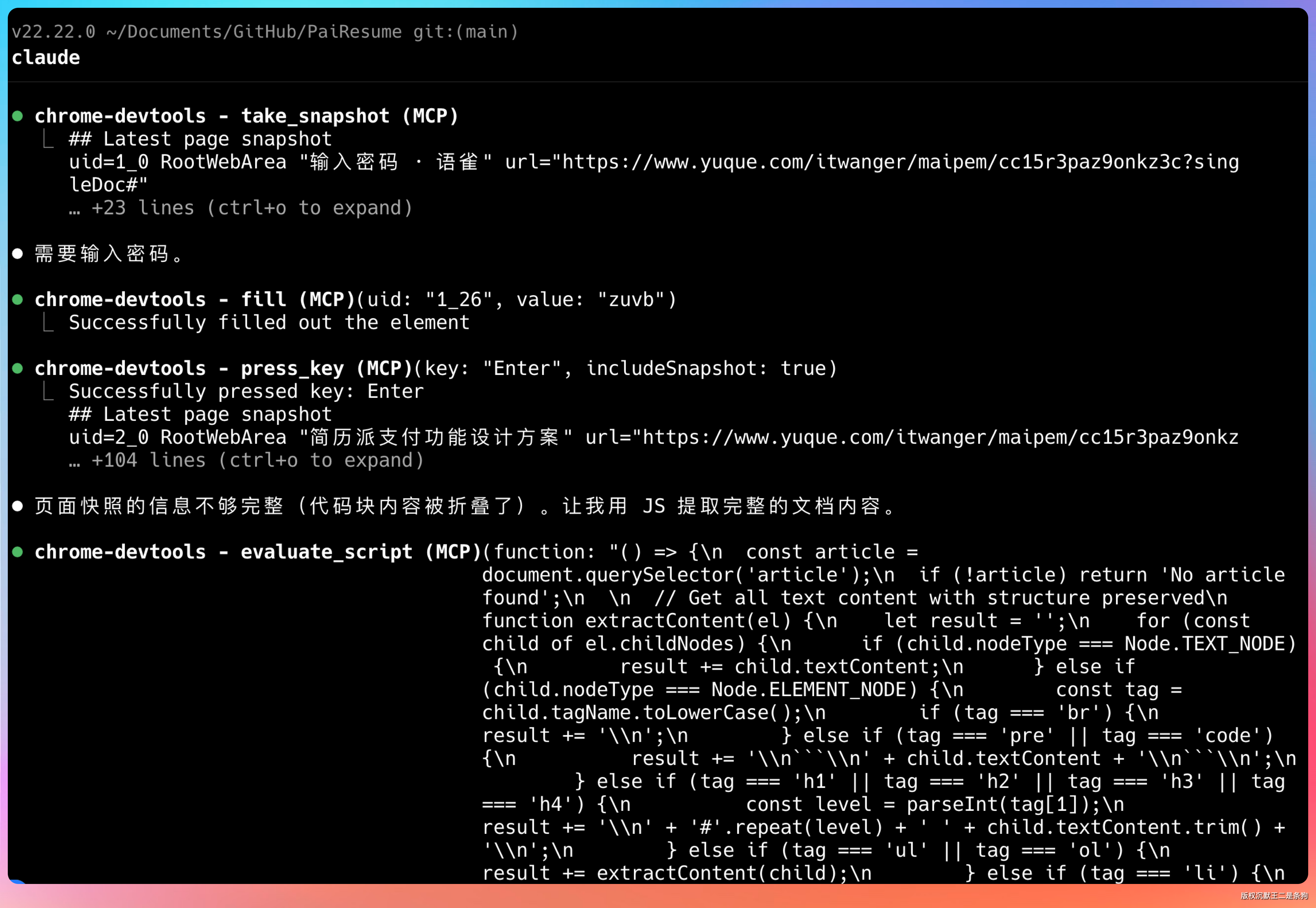
由于 GLM-5.1 的整体表现力非常出色,所以整个过程中并不需要我们人参与。
Chrome Devtools MCP 会自动翻页,然后读取完整内容。
这个过程中,模型会逐页分析文档的结构,提取关键信息:需求背景、功能模块、接口设计、库表结构这些都被分类整理好了。
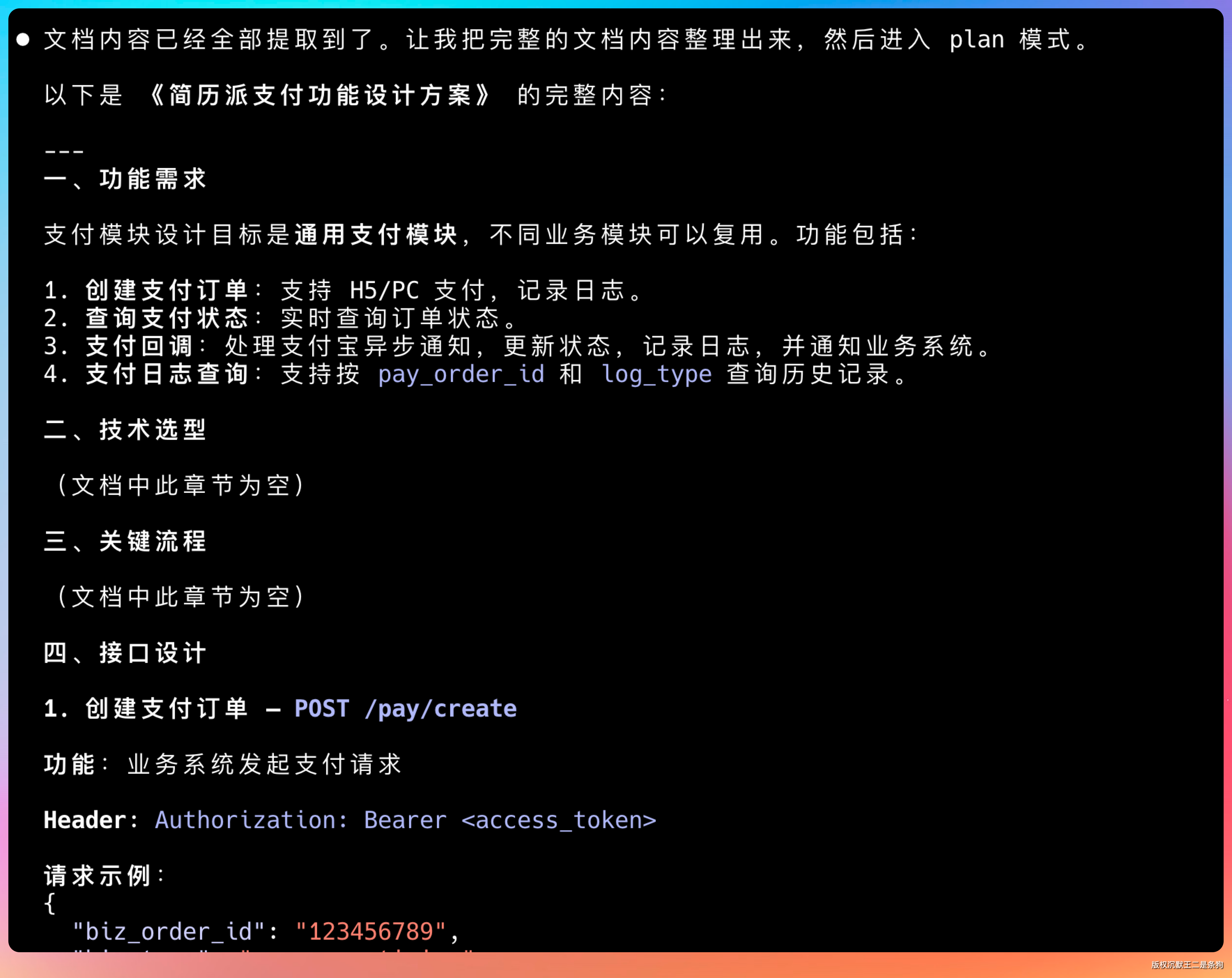
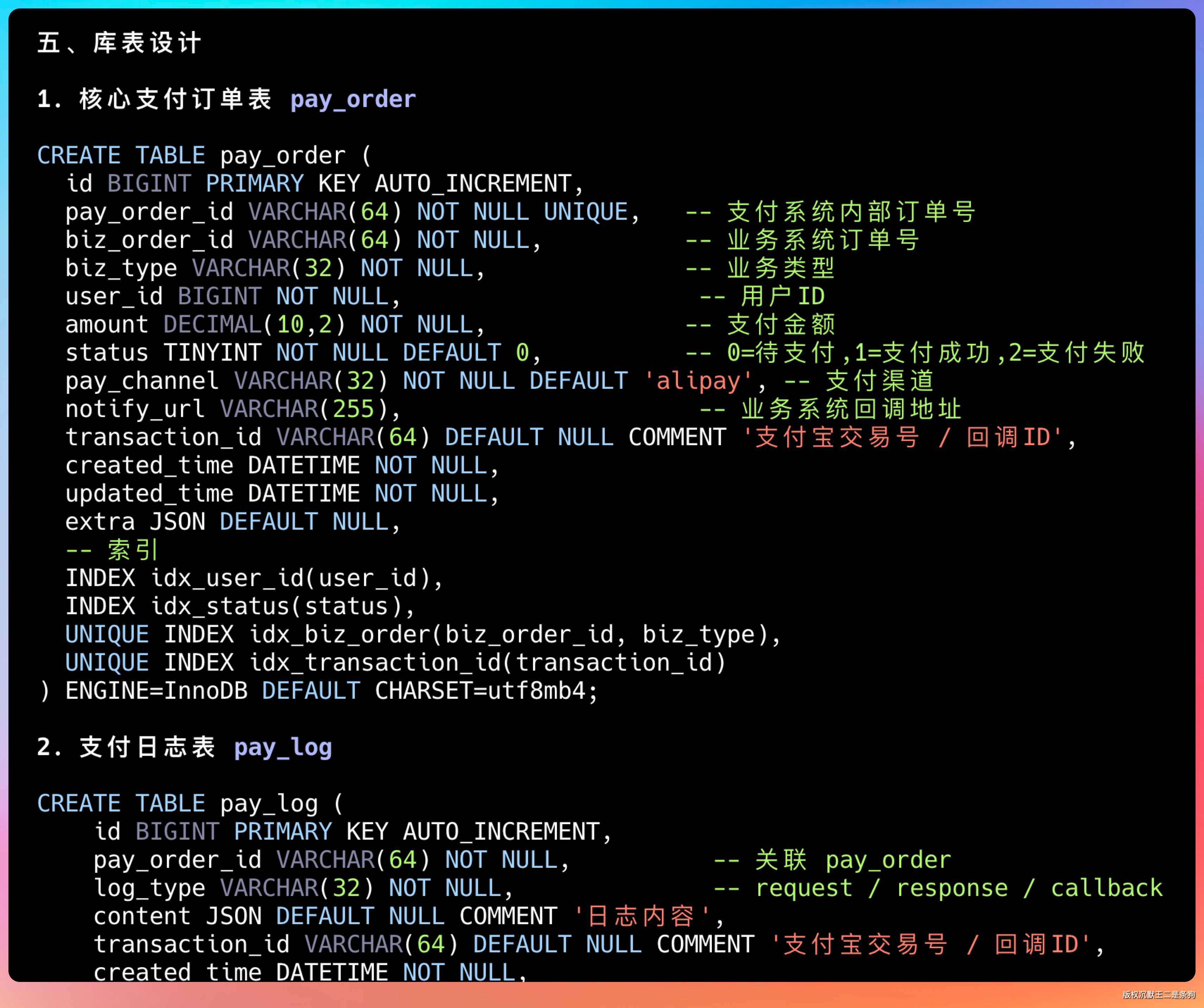
库表设计也能拿得到。
这一点很重要,因为很多模型在处理长文档时,容易漏掉表格、代码块这种结构化信息。
GLM-5.1 能把知识库中库表设计完整提取出来,字段类型、约束条件、索引设计都没有遗漏。
03、多子 Agent 读取需求文档
觉得一个 Agent 干活太慢,还可以用 web-access 这个 Skill 开启多个 Agent 读需求文档。
web-access 是专门用来并行处理网页抓取任务的,我之前也有分享过使用经验。
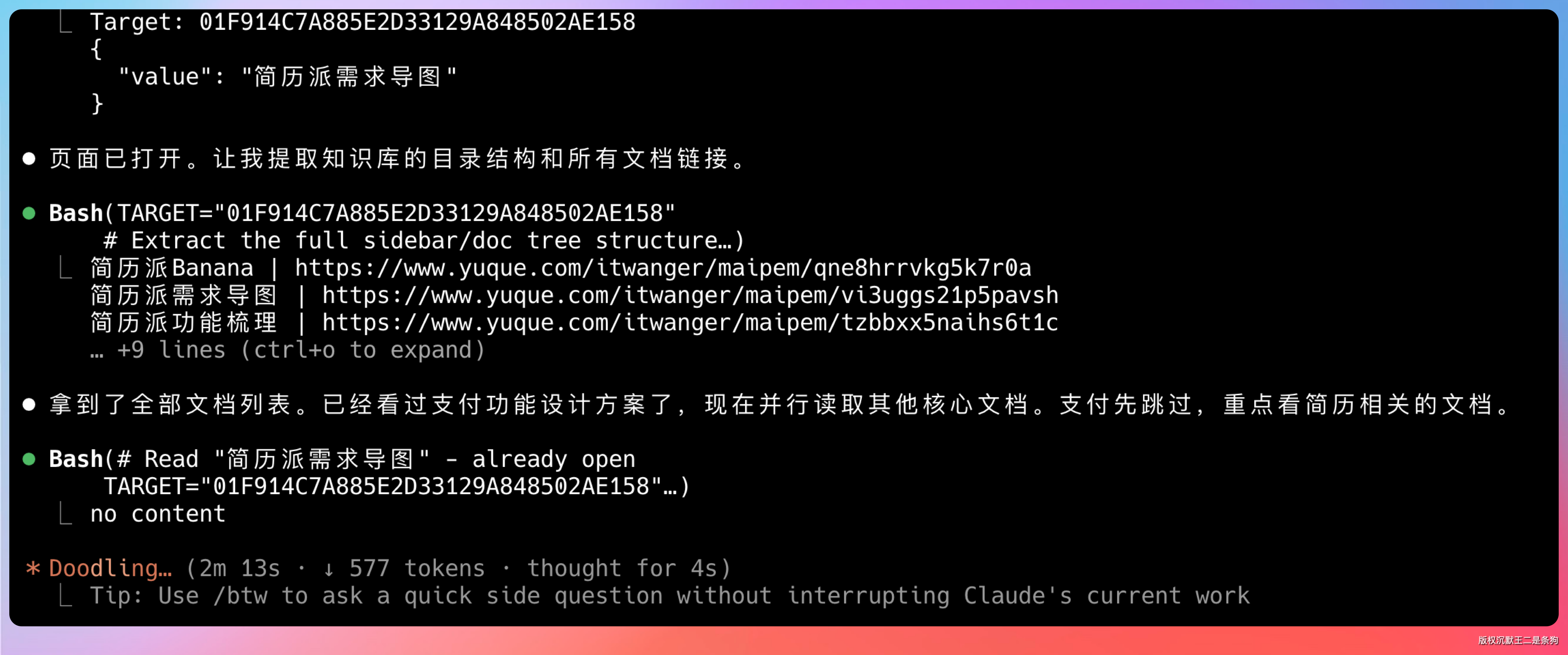
功能梳理文档、AI 优化简历、简历修改、通知功能等,CC 会按照 Skill 的安排直接开启多个子 Agent 去干活。
每个 Agent 都在独立的标签页里运行,有自己的上下文和状态。这种并行处理的能力,大大缩短了信息收集的时间。
多标签页同时进行,互不干扰,这时候考验的就是模型的并发能力。😄
就 GLM-5.1 的表现力来说,确实无可挑剔。
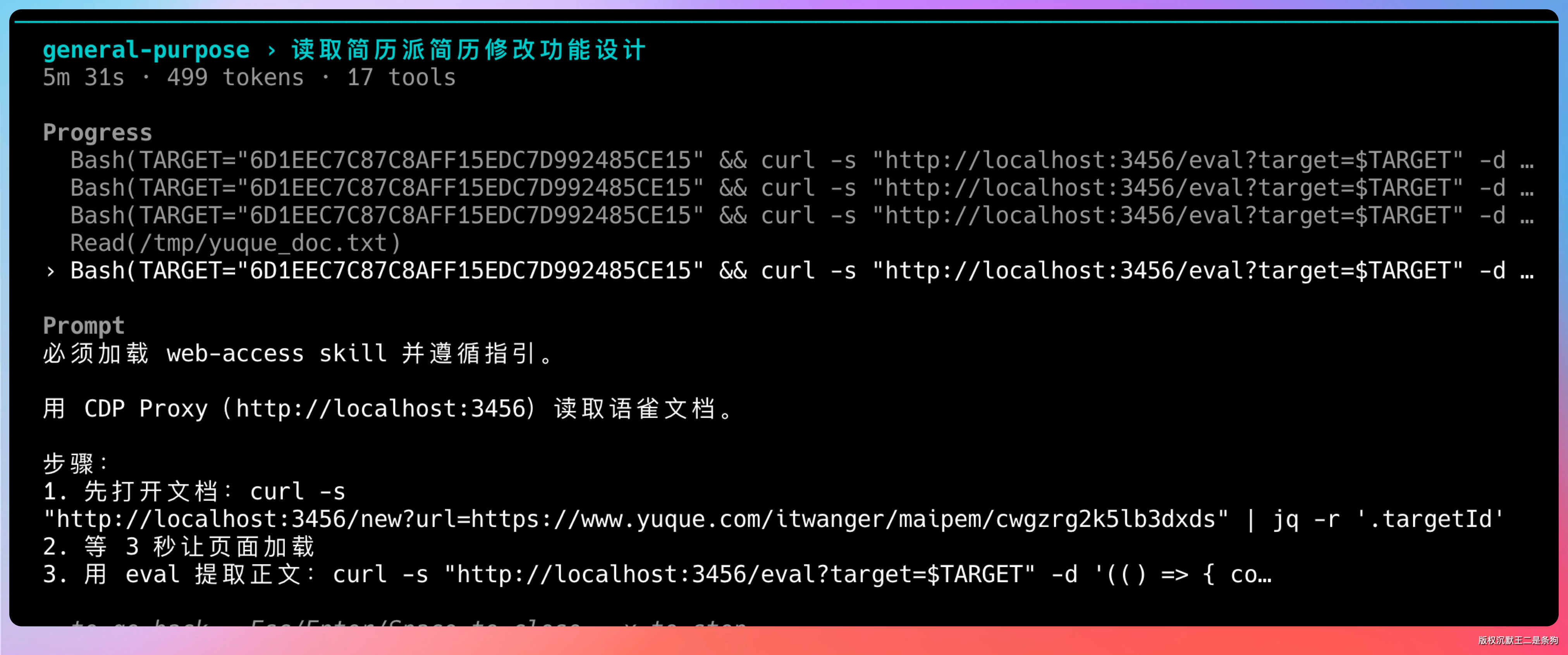
OK,已经搞定了功能梳理,然后等另外几个文档的子 Agent 返回结果。
tips:在 Claude Code 中还可以通过上下箭头查看其余 Agent 的干活情况。
这个交互设计很贴心,不用切换界面就能掌握全局进度。
如果你想了解某个 Agent 具体在做什么,按回车就能进入它的详细会话界面。这里可以看到它读取了哪些内容、提取了哪些关键信息、有没有遇到什么问题。
是不是感觉很爽?
多 Agent 并行 + 统一调度。
如果任务结束了,还会帮我们自动关闭标签页。这个细节很加分,不会留下一堆无用的浏览器标签页占资源。
好家伙,9 个文档全部都读完了,告诉我们他看到的结果。

- 全局思维导图:登录 → 首页 → 简历生成(模板+模块化编辑+AI 优化+排版)→ 我的简历(查看/新建/导出)→ 简历优化(付费,管理员后台处理)→ 通知
- 四大模块:简历模板(默认+模板中心)、我的简历(模块化编辑+AI 优化+导出 PDF)、简历优化、基础功能
- 邮箱注册+验证码、JWT(access_token+refresh_token)、Redis 缓存、管理员初始化
- Kafka 消息队列、同步持久化+异步分发、高/低优先级 Topic、DLQ 死信队列、站内+邮件通知
- 通用支付模块、支付宝 H5/PC、4 个接口(创建/查询/回调/日志)、pay_order+pay_log 表
- 模块化 JSON 存储、resume 主表+resume_module 模块表、8 个接口(CRUD+AI 优化)、前端渲染 PDF
- Deepseek 模型、STAR 法则 Prompt、用户触发 → 后端处理 → 对比展示 → 用户决策、输入校验+超时控制
- 用户发起修改任务 → 专家后台处理 → 自动保存草稿 → 完成通知、10 个接口、4 张表
太全面了呀。我滴乖乖。
04、GLM-5.1 梳理需求
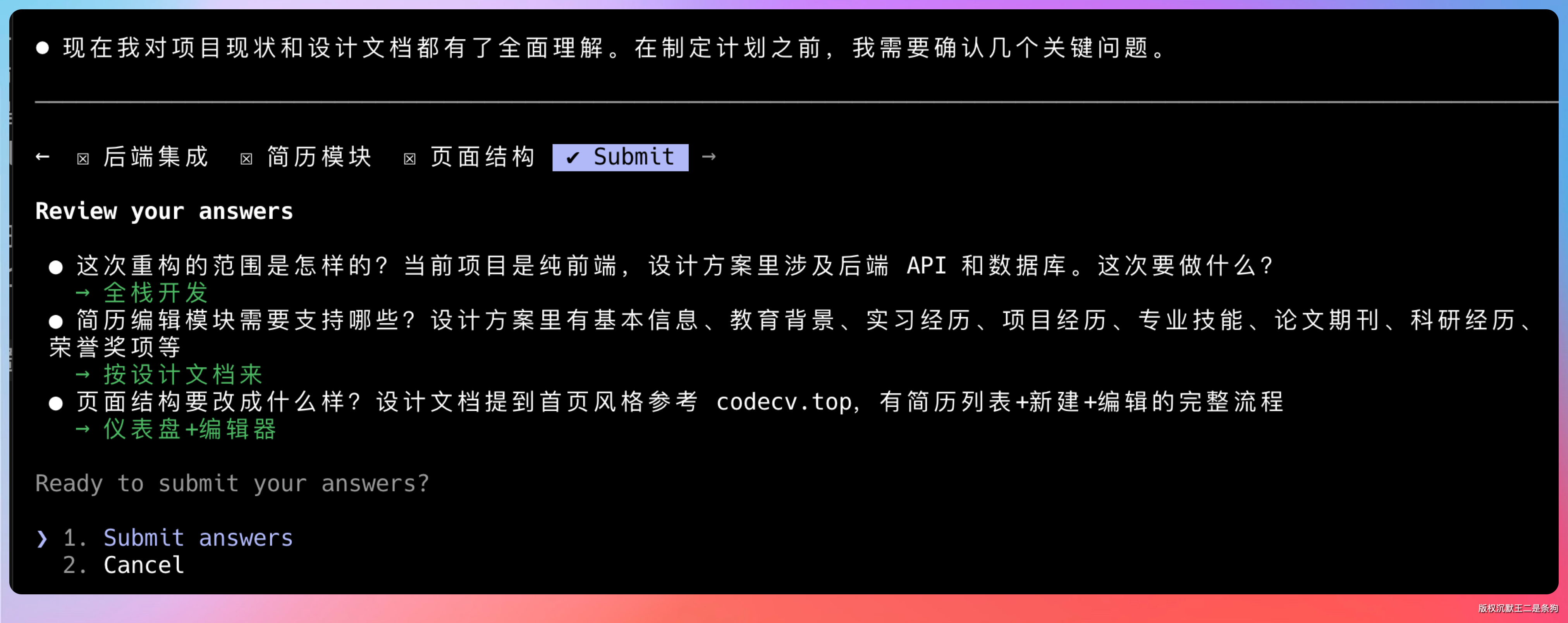
选好前后端的技术栈。
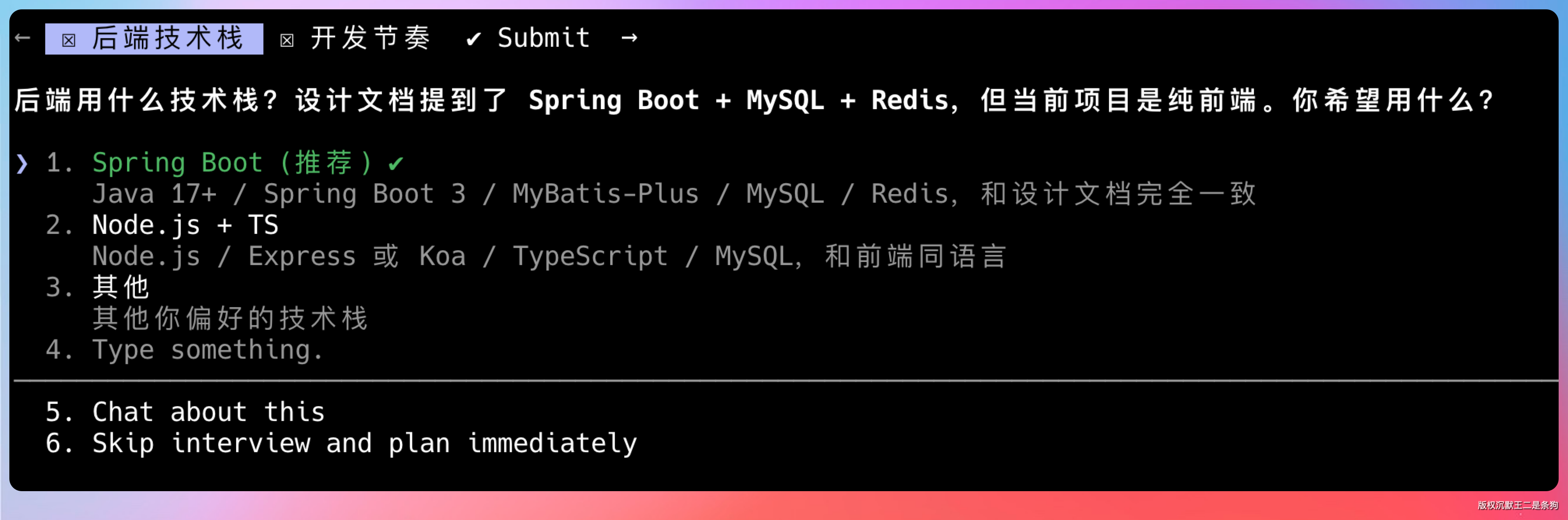
这时候 GLM-5.1 会进入 plan 模式,它会先输出一份完整的设计文档,包括技术选型、目录结构、依赖管理、数据库设计、接口定义等所有内容。
这个设计文档不是简单的罗列,而是有逻辑、有层次的完整方案。
可以 ctrl+o 看一下详细的设计过程。
我建议大家多看看,能学到很多工程化的思维方式。比如它是怎么拆解复杂需求的、怎么权衡技术选型的、怎么考虑边界情况的。
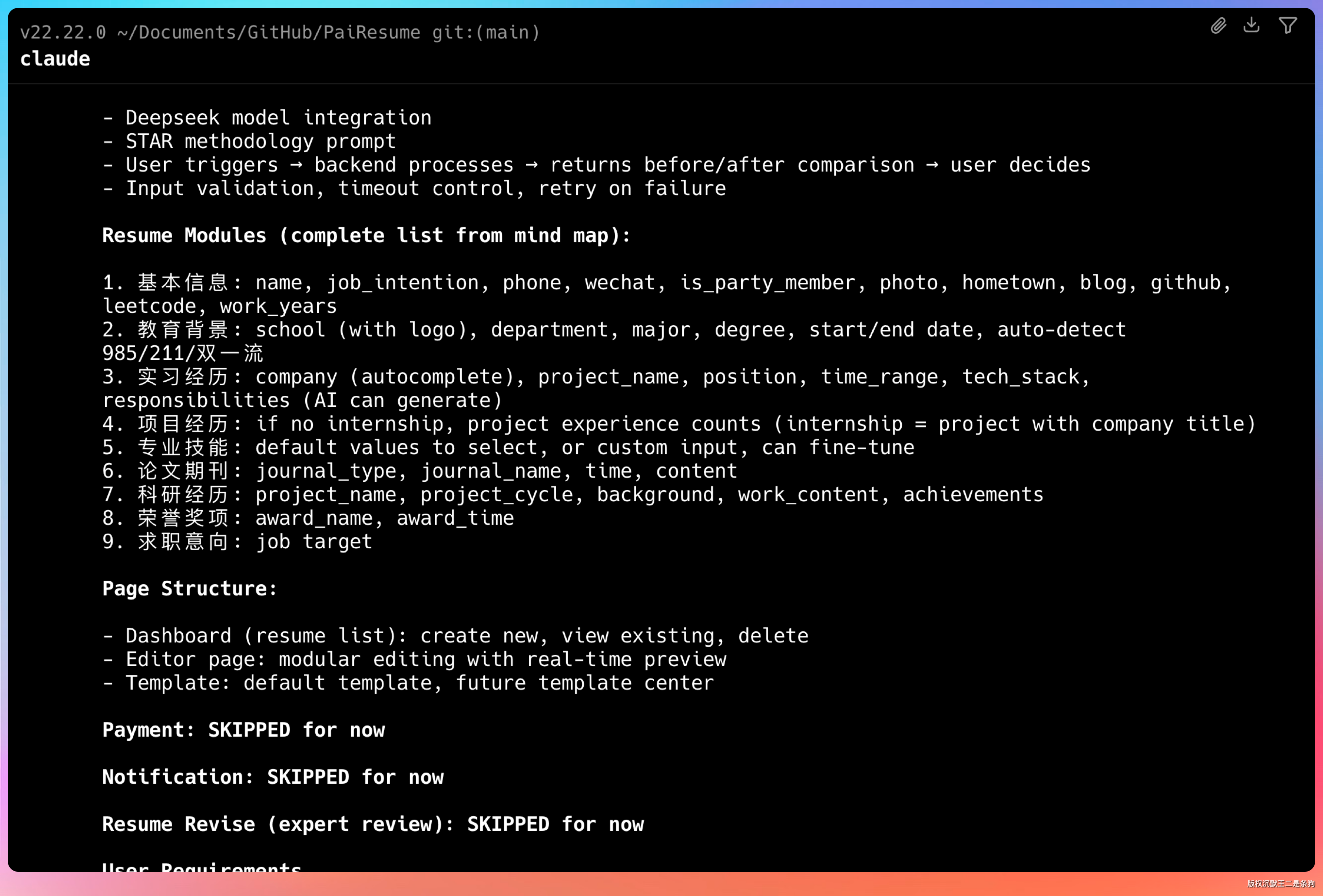
GLM-5.1 采用了经典的分层架构:controller 层处理请求、service 层处理业务逻辑、mapper 层处理数据访问、entity 层定义数据模型。
Spring Boot 3.x 作为基础框架,MyBatis Plus 作为 ORM 工具,JWT 做认证,Redis 做缓存,Kafka 做消息队列。
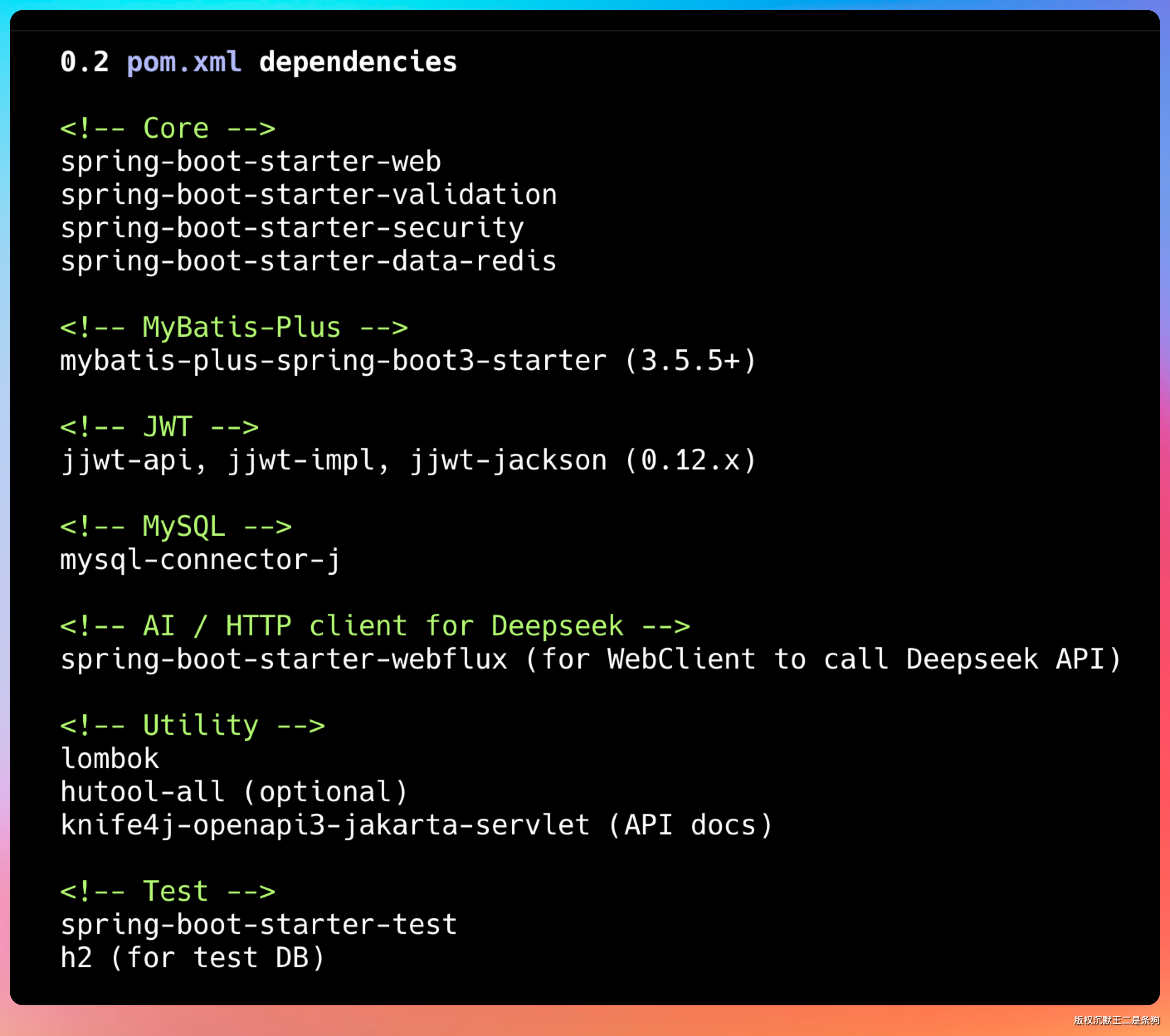
GLM-5.1 还贴心地考虑到了环境区分,开发环境、测试环境、生产环境的配置都做了隔离。这种细节处理,说明它真的有工程经验。
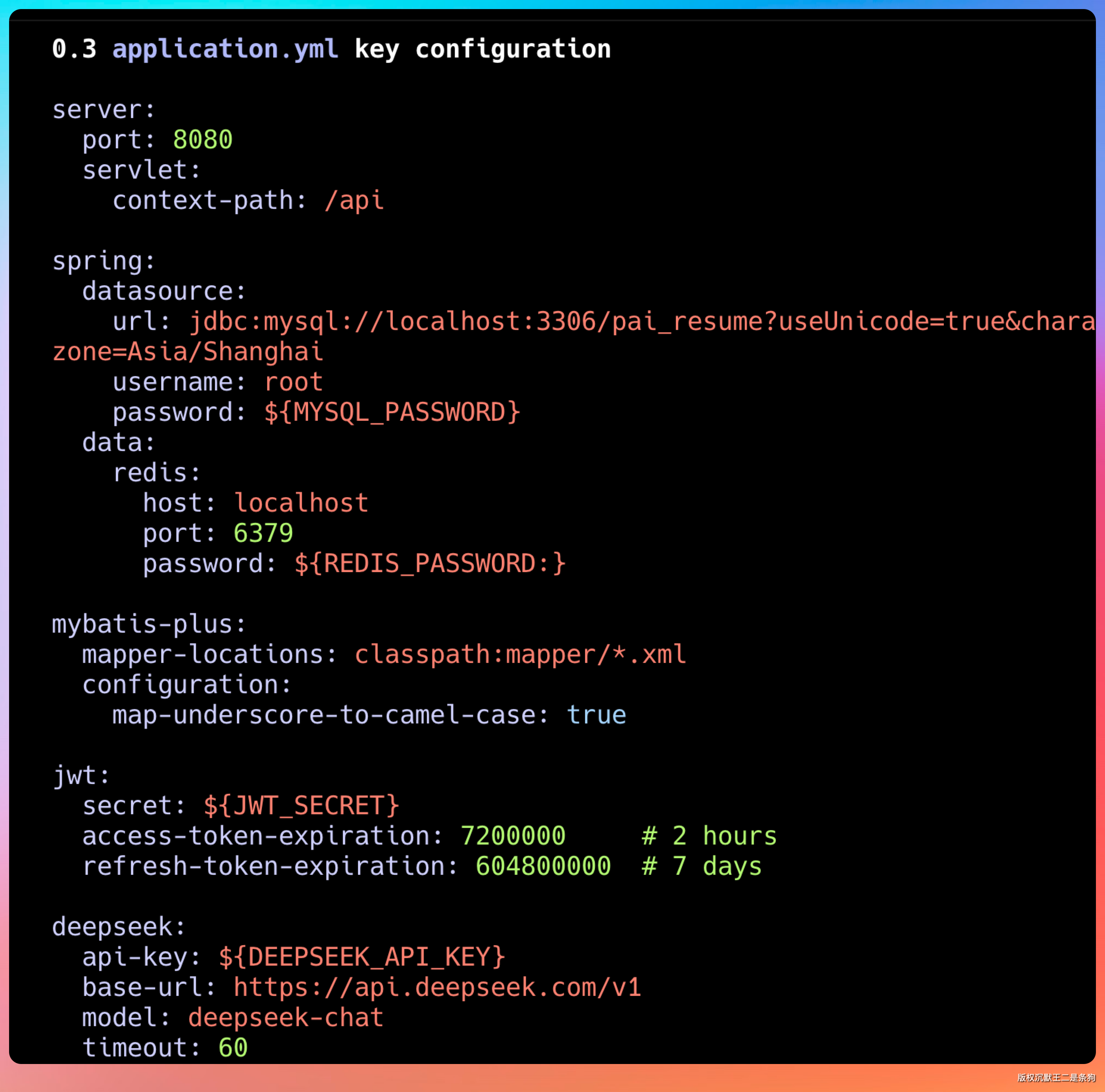
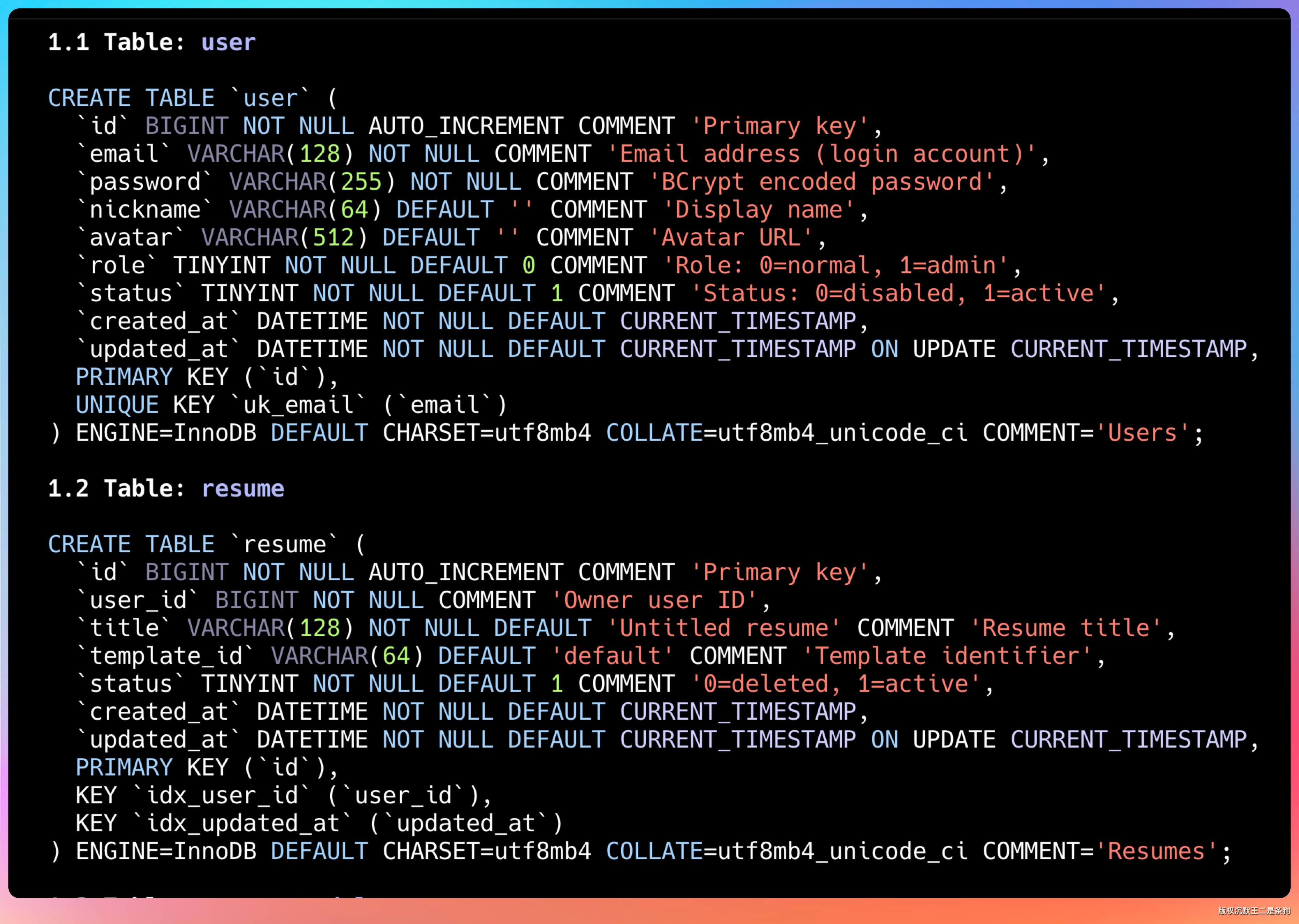
GLM-5.1 设计了完整的表结构:用户表、简历表、简历模块表、支付订单表、支付日志表、通知表等。
每个表的字段类型、约束条件、索引设计都很合理。
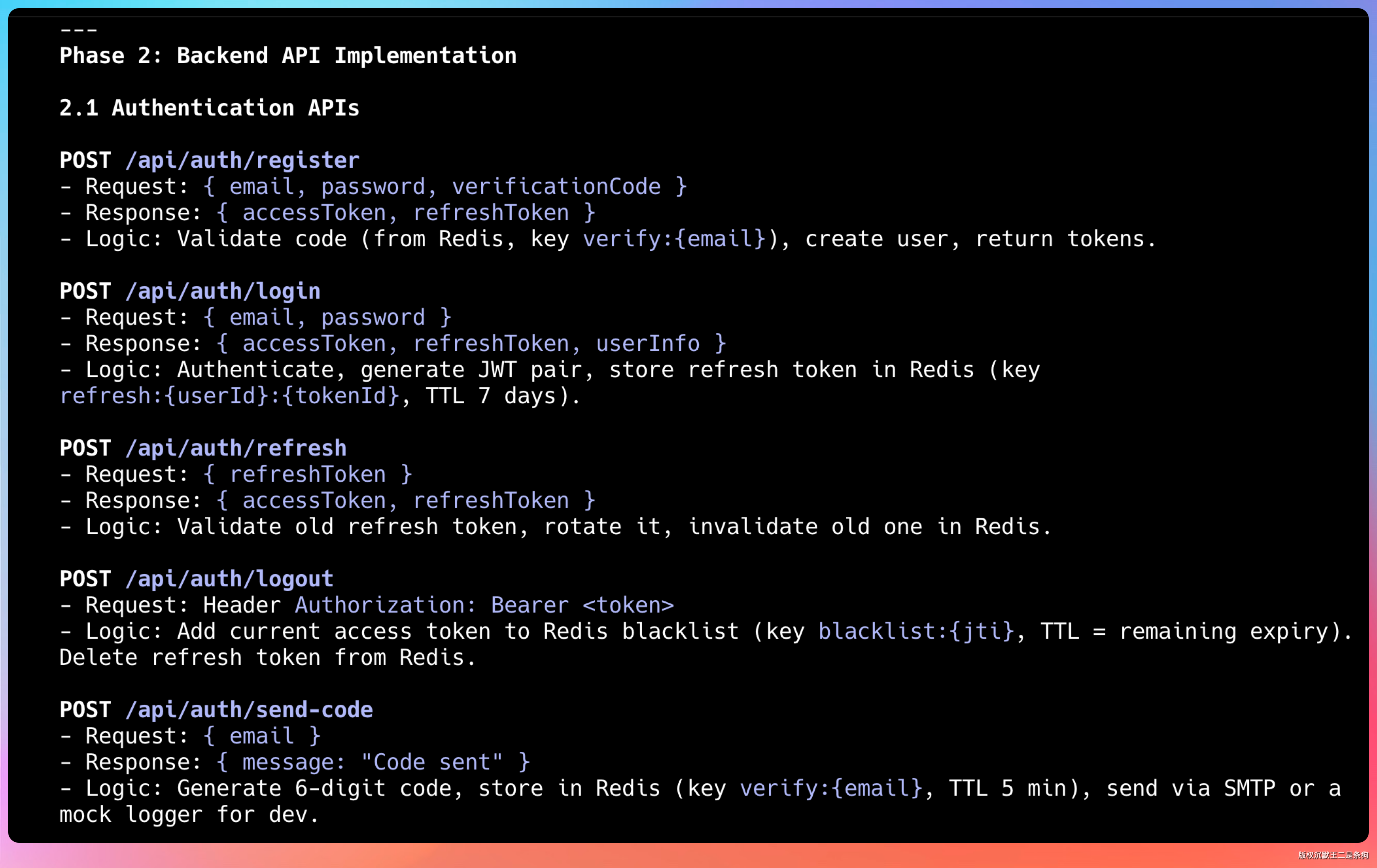
RESTful 风格的 API 设计,统一的响应格式,清晰的接口文档。包括用户认证接口、简历 CRUD 接口、支付接口、通知接口等。
每个接口都有详细的参数说明和返回值定义,前端同学可以直接照着用。
安全方面考虑了 JWT 认证、接口权限控制、敏感数据加密等。
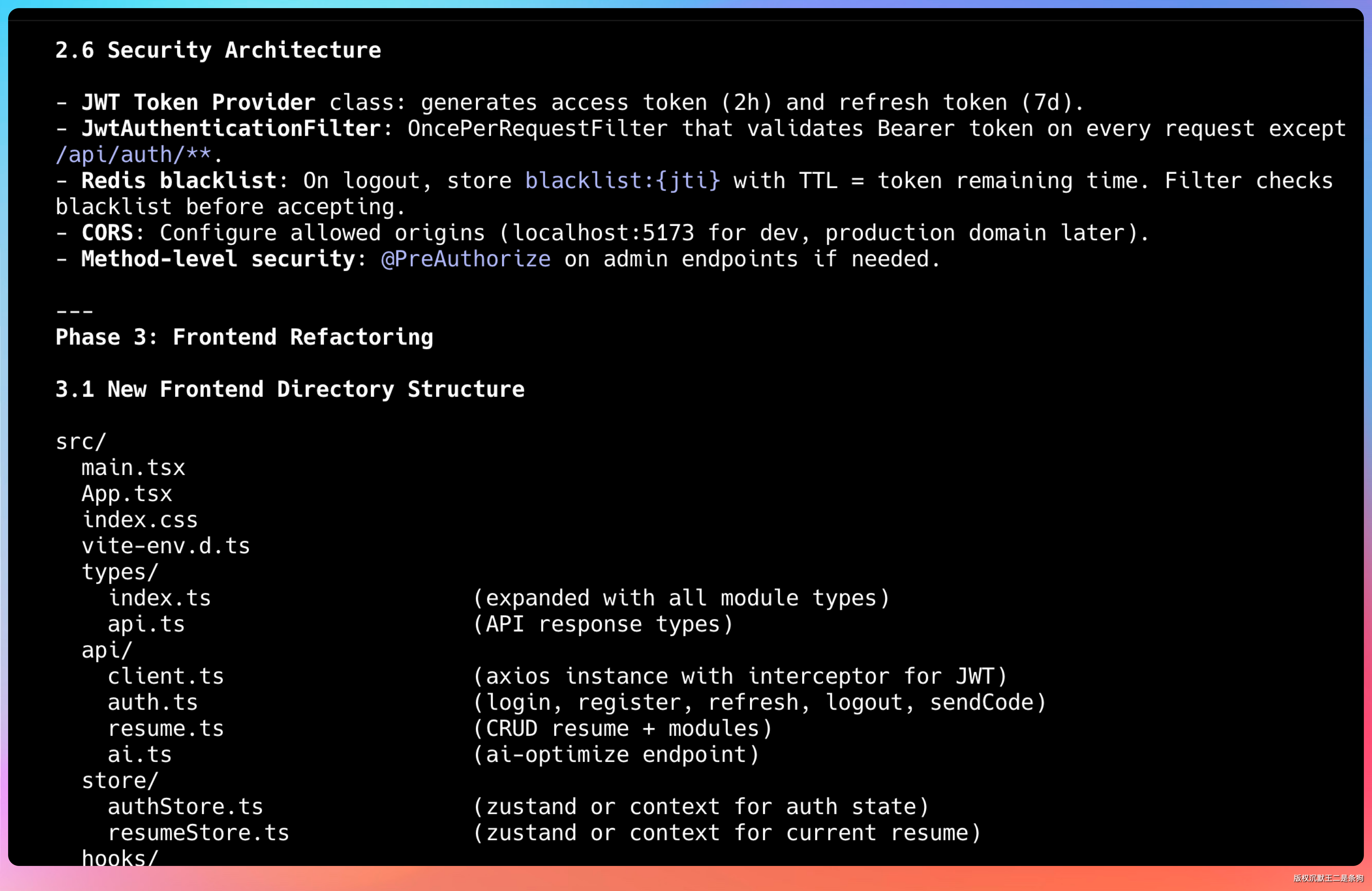
GLM-5.1 还画了业务流程图,从用户登录到简历生成,从支付到通知,整个业务一目了然。
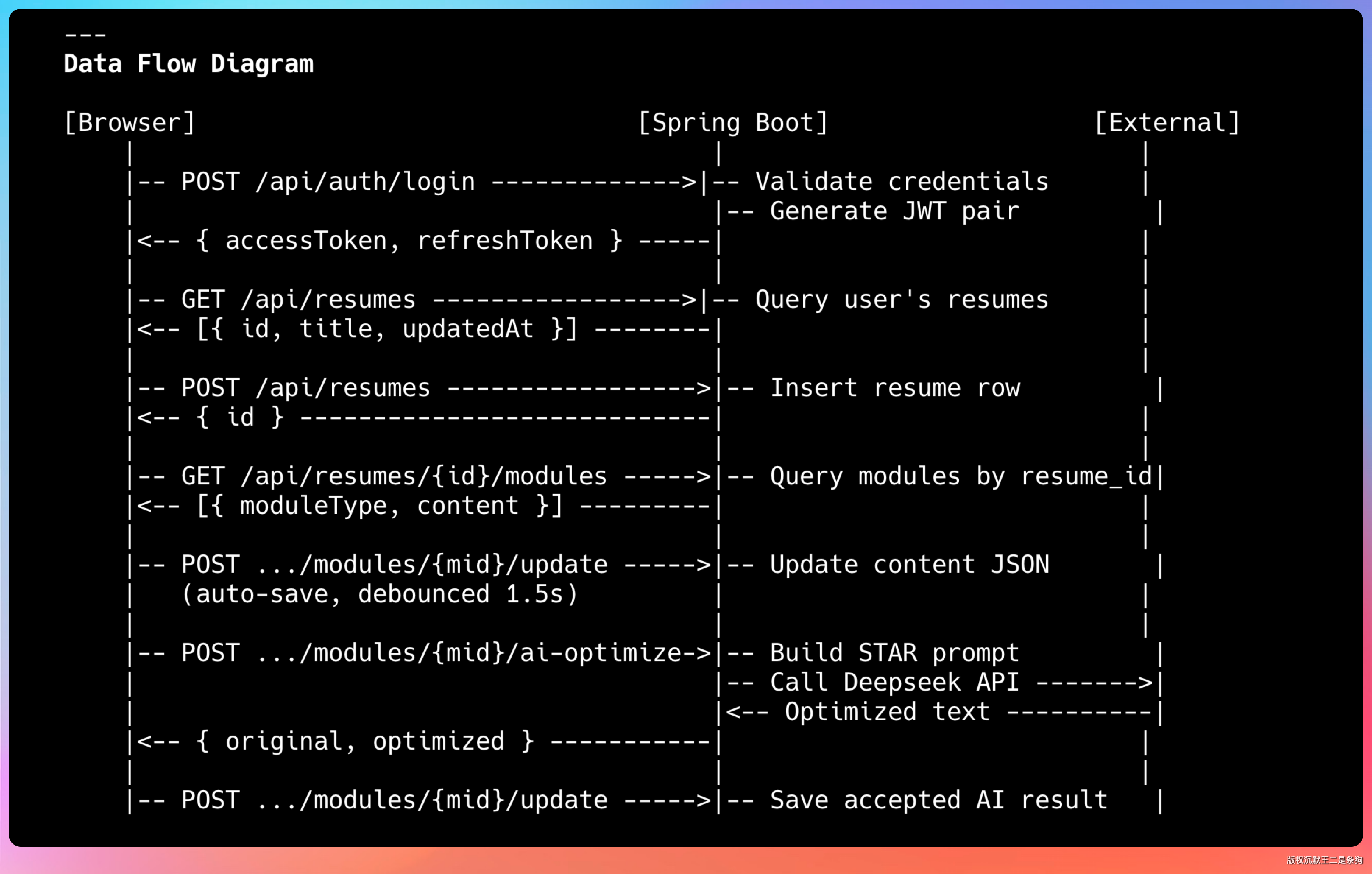
一共 12 个步骤,考虑的非常全面。
从环境搭建到代码实现,从数据库到前端页面,从单元测试到部署上线,每个环节都有明确的任务和验收标准。这种细粒度的任务拆解,是长程任务能够顺利完成的关键。

05、GLM-5.1 开始编码
好,开始让 GLM-5.1 进行编码吧。
截止到目前,已经运行 21 分钟了,没有出任何错,说明 GLM-5.1 的长程任务能力确实很强,能持续稳定地执行这么长时间的复杂任务。
对于 AI 模型来说,长时间保持上下文不丢失、逻辑不混乱是很有挑战的。很多模型在 10 分钟后就开始出现质量下降,但 GLM-5.1 依然稳定。
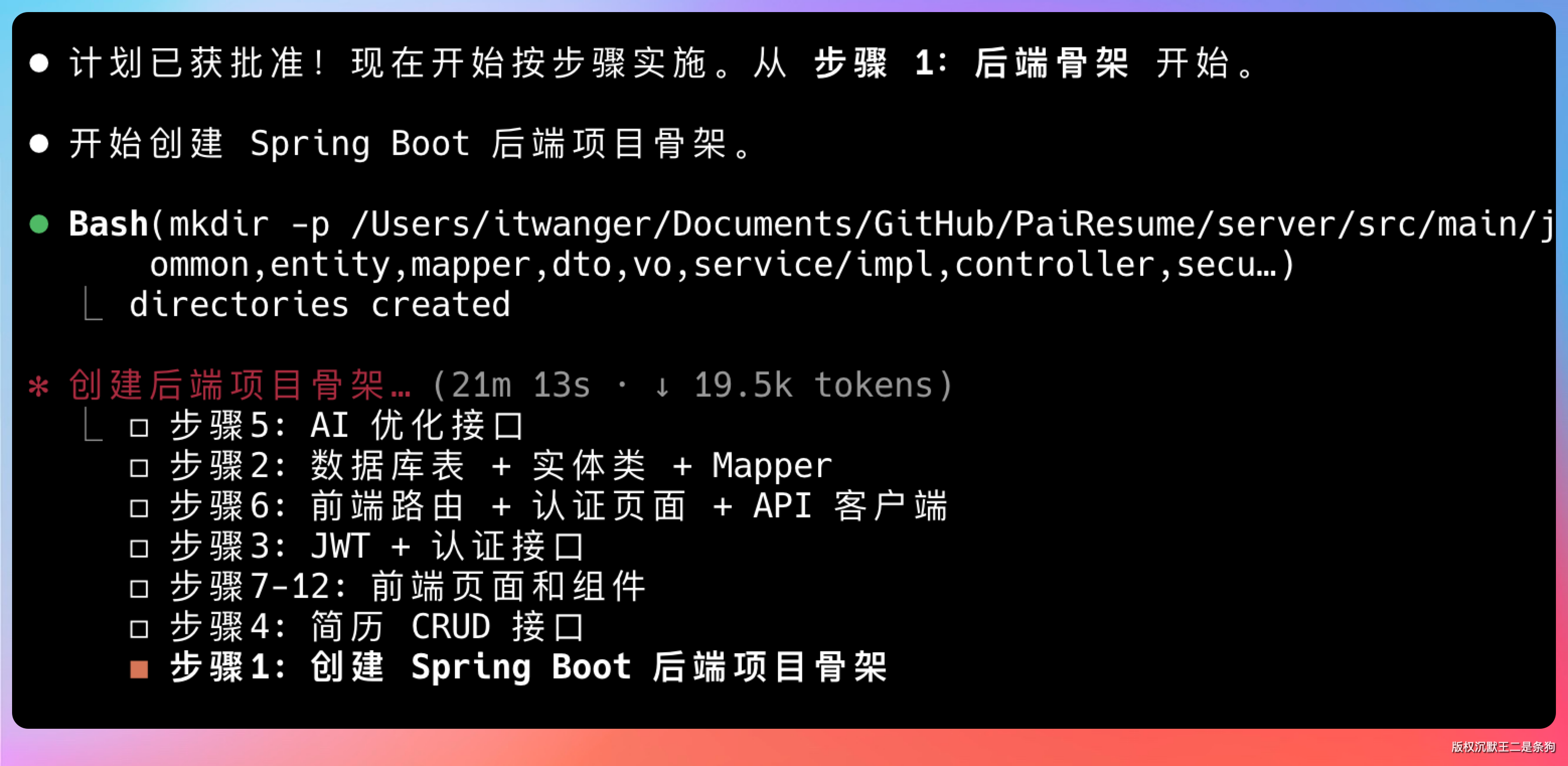
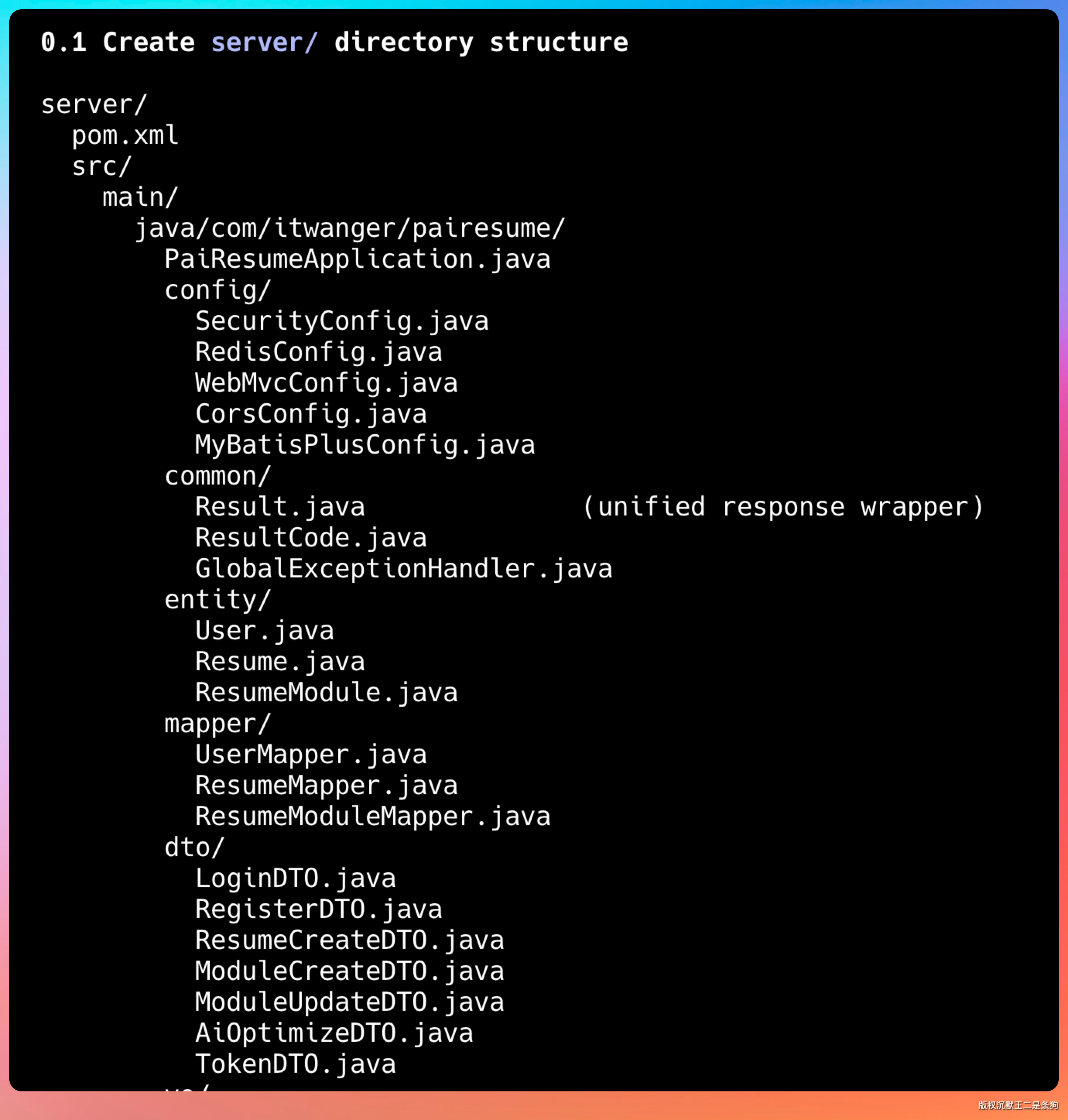
第一步是搭建后端的项目骨架。创建 Maven 项目结构,配置 pom.xml,建立分层目录。
第二步是数据库表 + 实体类 + Mapper。根据之前设计的表结构,创建对应的实体类和 MyBatis Mapper 接口。
第三步是 JWT + 认证接口。实现用户登录、注册、Token 刷新等功能。JWT 的密钥生成、过期时间设置、刷新机制都考虑到了。
第四步是 CRUD 接口的实现。包括简历的增删改查、模块的增删改查等。每个接口都有完整的参数校验、业务逻辑处理、异常处理。代码风格统一,注释清晰,符合 Java 开发规范。
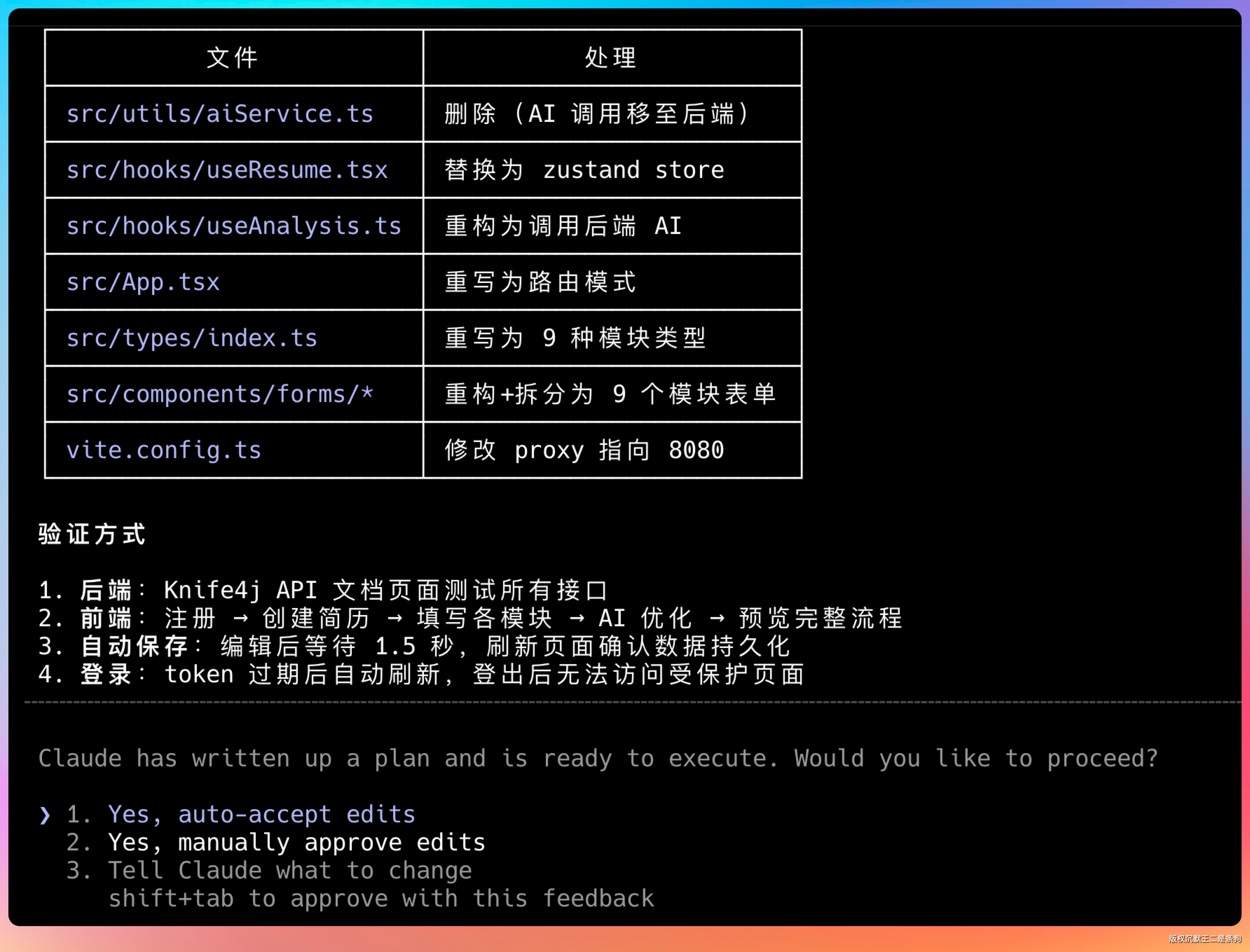
到此算是一个段落,后端已创建 30+ 个 Java 文件。剩下后端 AI 接口 + 整个前端重构。

后端编码完成后,CC 问我们要不要确认后端代码再继续干活,那必须是不要,继续干啊,GLM-5.1 你这个牛马,不要停。
这种连续执行的能力,正是长任务的核心价值。
接下来是步骤 6:前端重构 — 安装依赖、路由、认证页面、API 客户端。
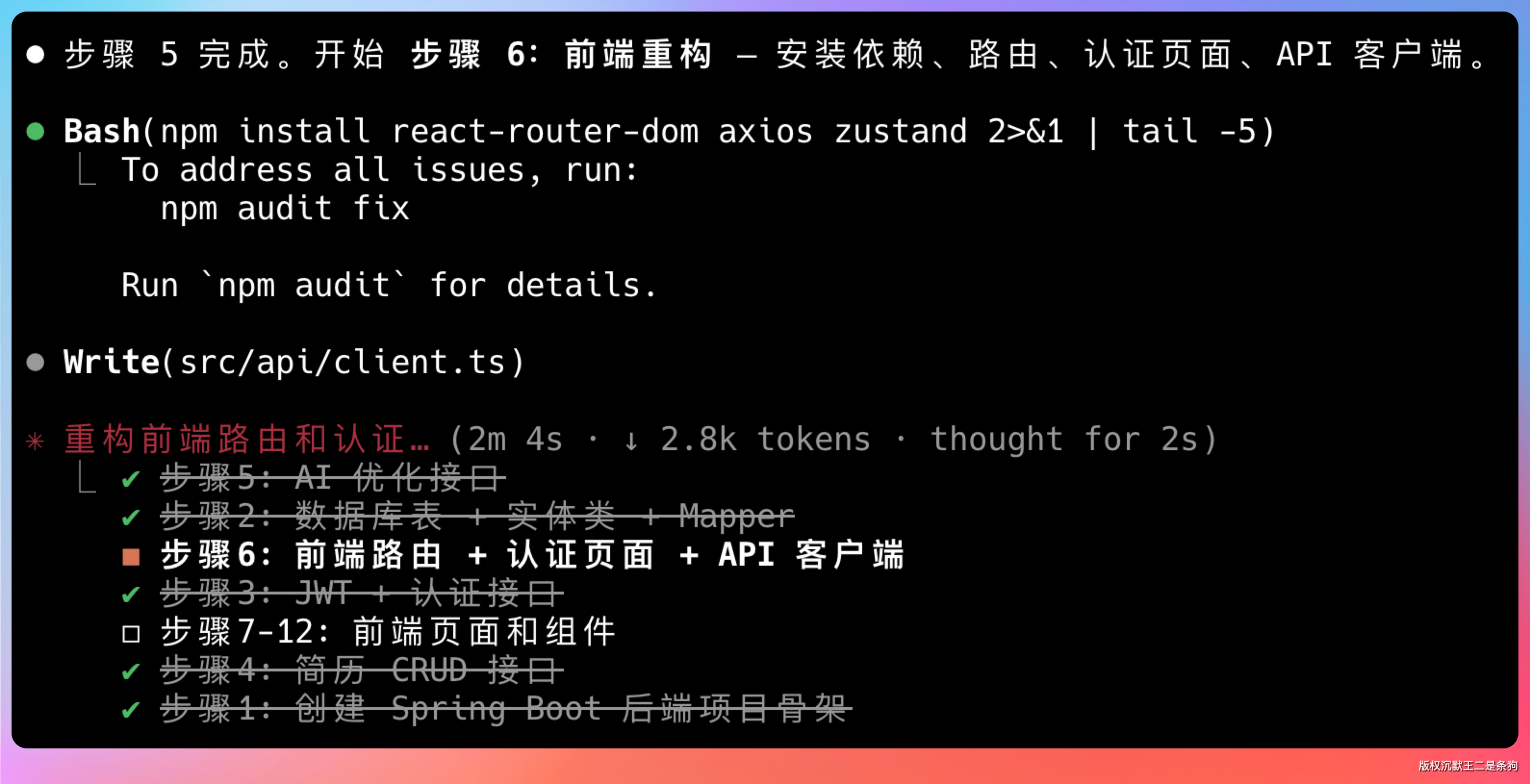
接下来是,前端页面和组件。包括登录页、注册页、首页、简历编辑页、简历列表页、支付页等。每个页面都有完整的 UI 结构和交互逻辑。
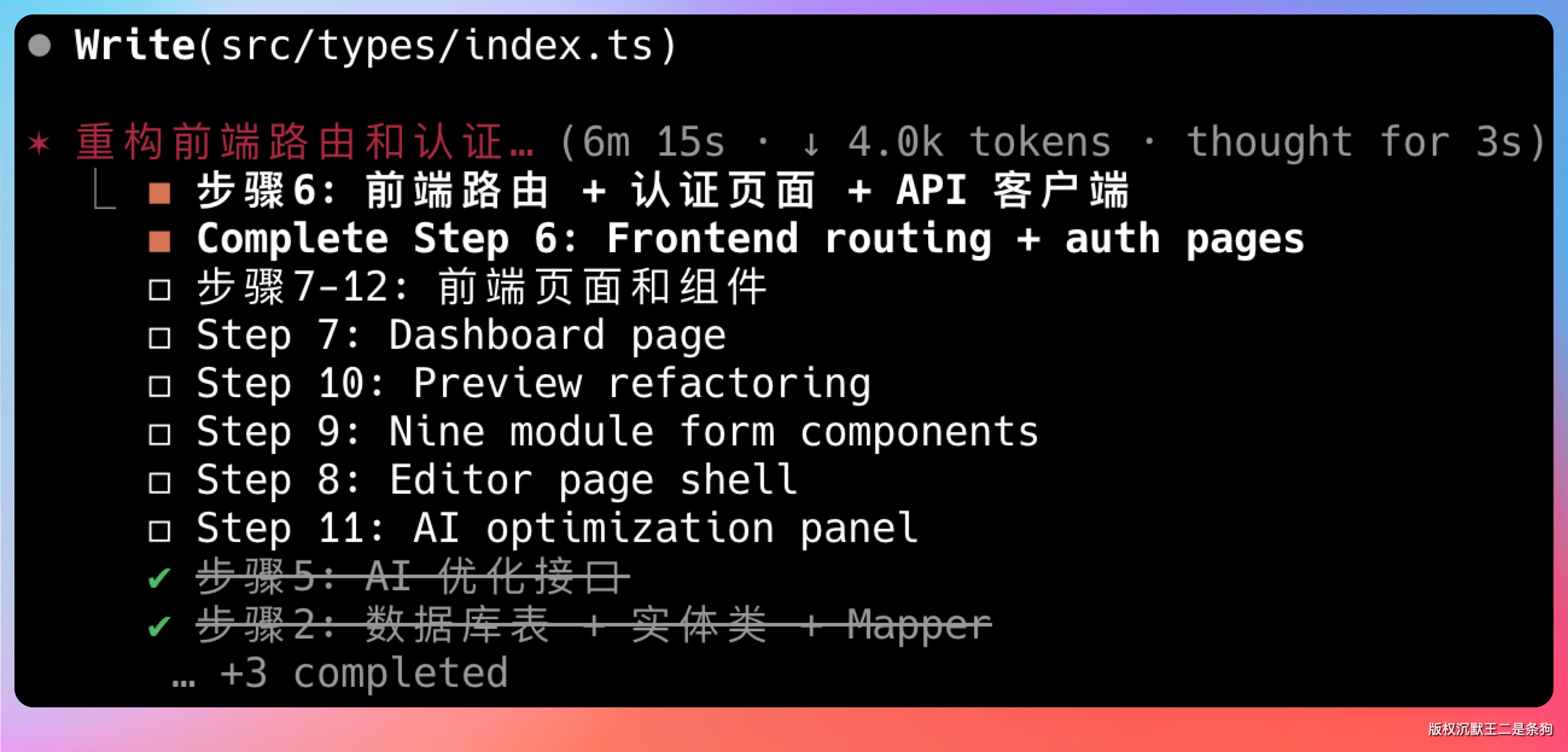
全部搞定。而且代码质量还不错,结构清晰,命名规范,有基本的错误处理。
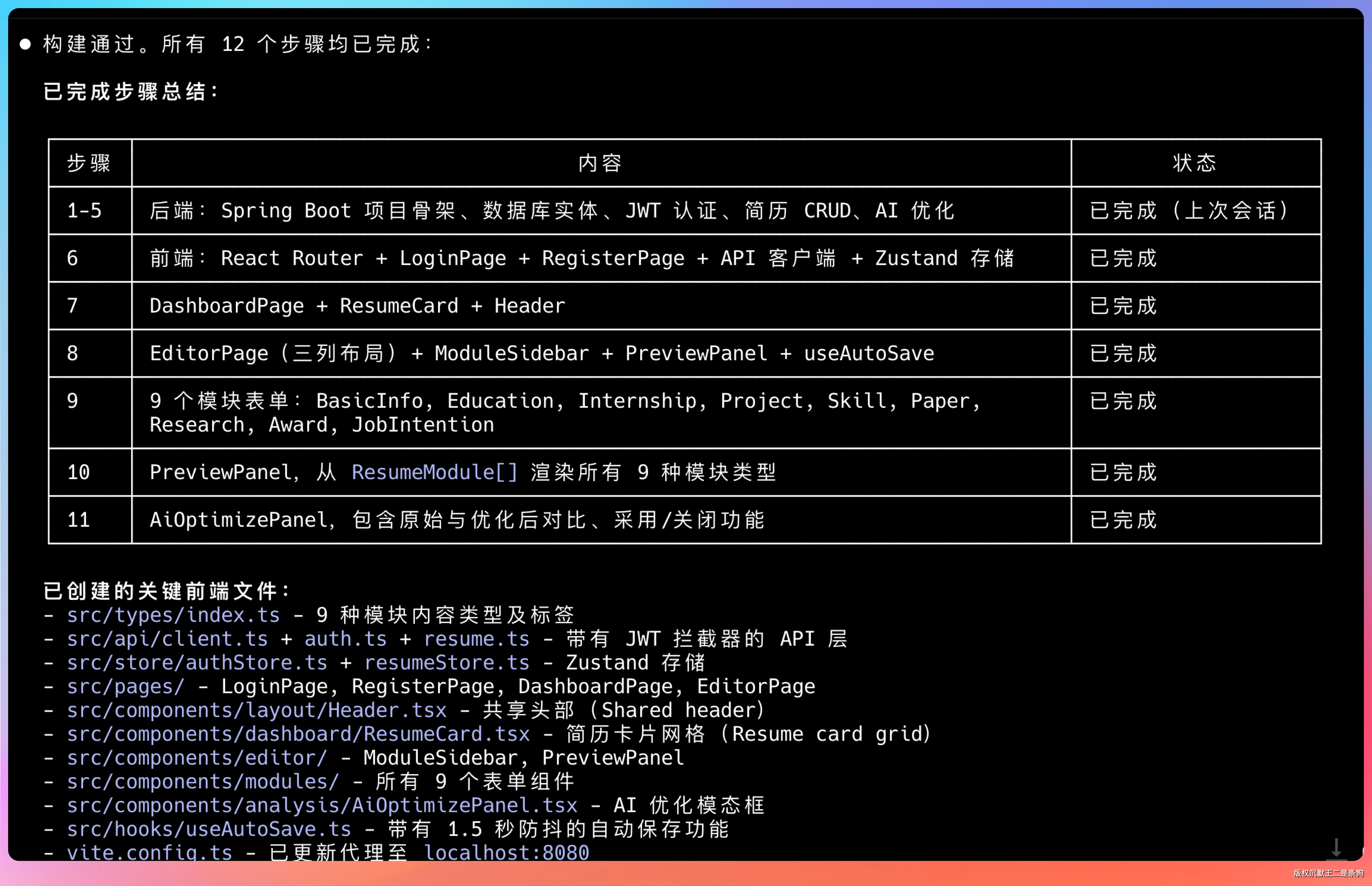
整体代码编写完了,我们问问接下来需要我们干什么。
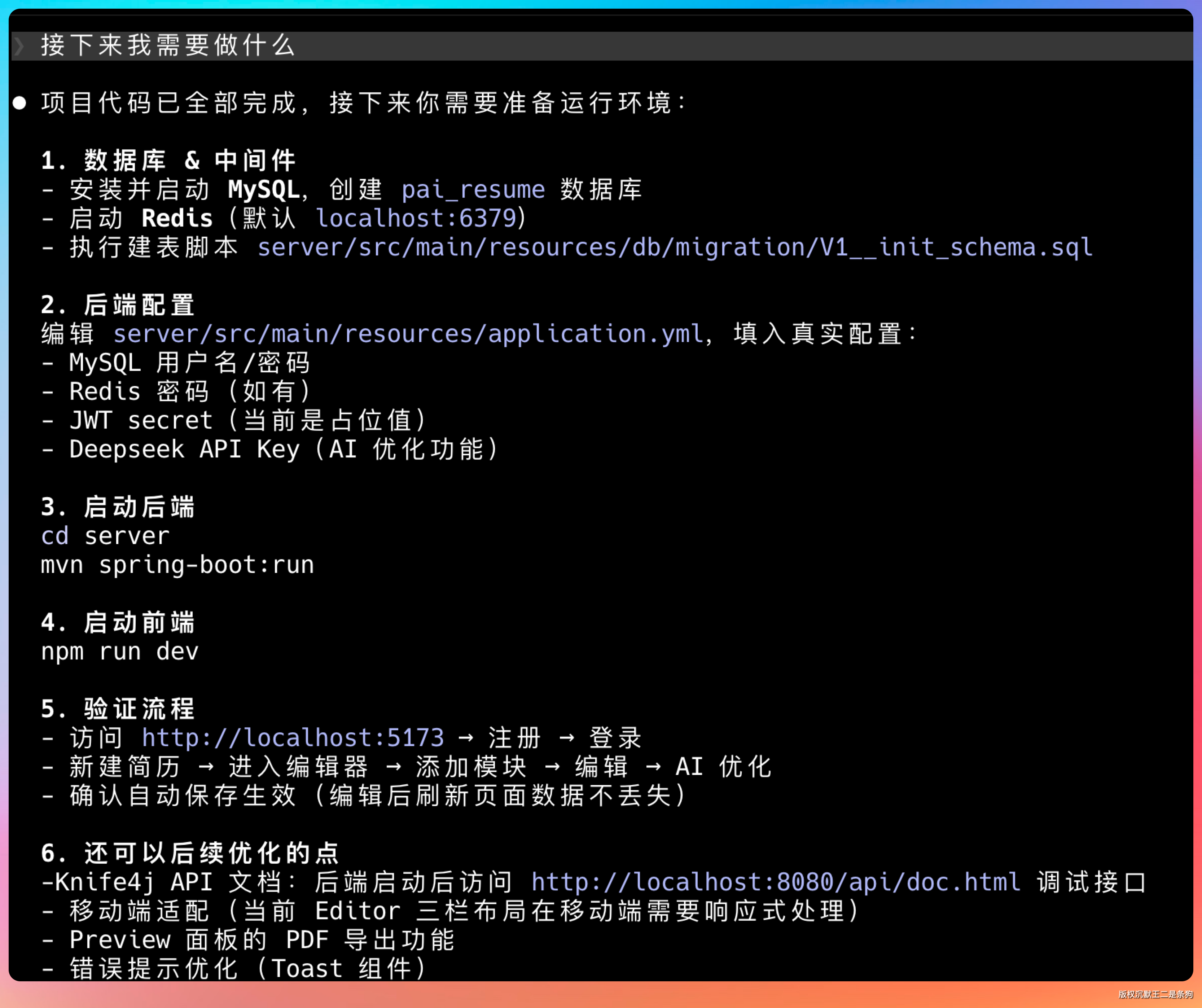
06、GLM-5.1 启动前后端
提示词:mysql 和 Redis 我已经启动了,你直接搞定。但是我希望直接启动 main 方法的时候把建表执行了,这样我就不用自己去执行了,是不是。后端的配置能不能放到 .env 文件中,如果我配置到 application.yml 我提交的时候还要防止误提交。
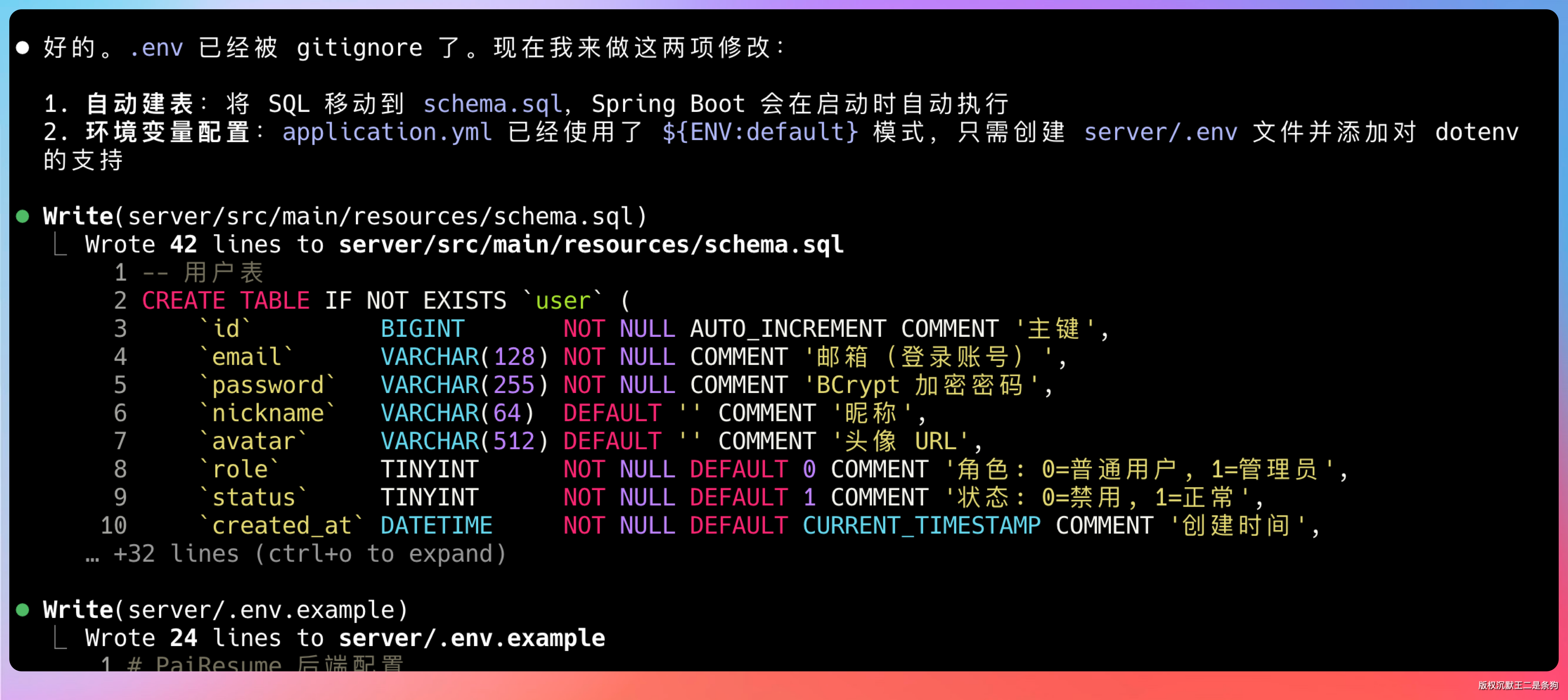
有任何错误,也会自己调整。
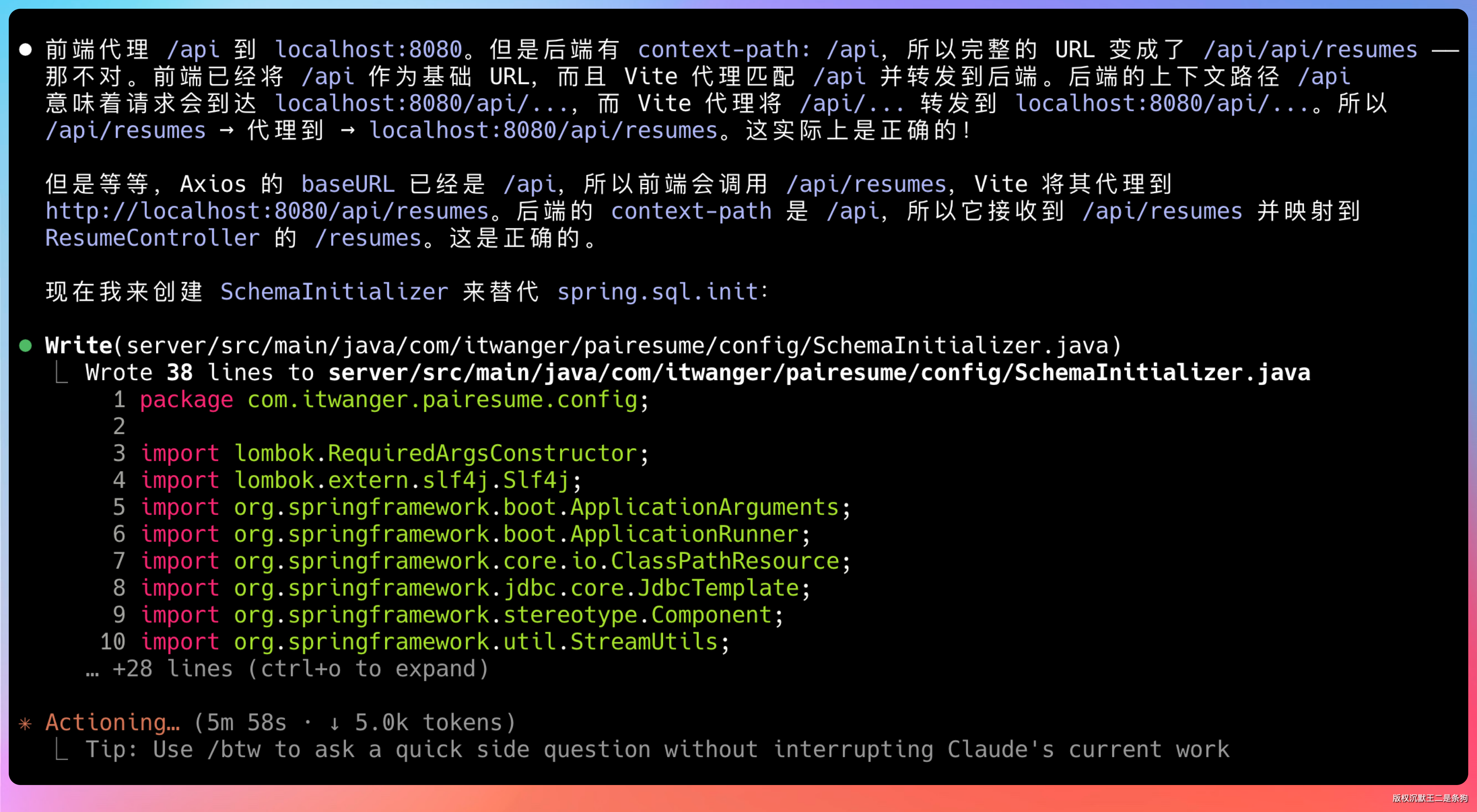
前后端的编译都通过了。
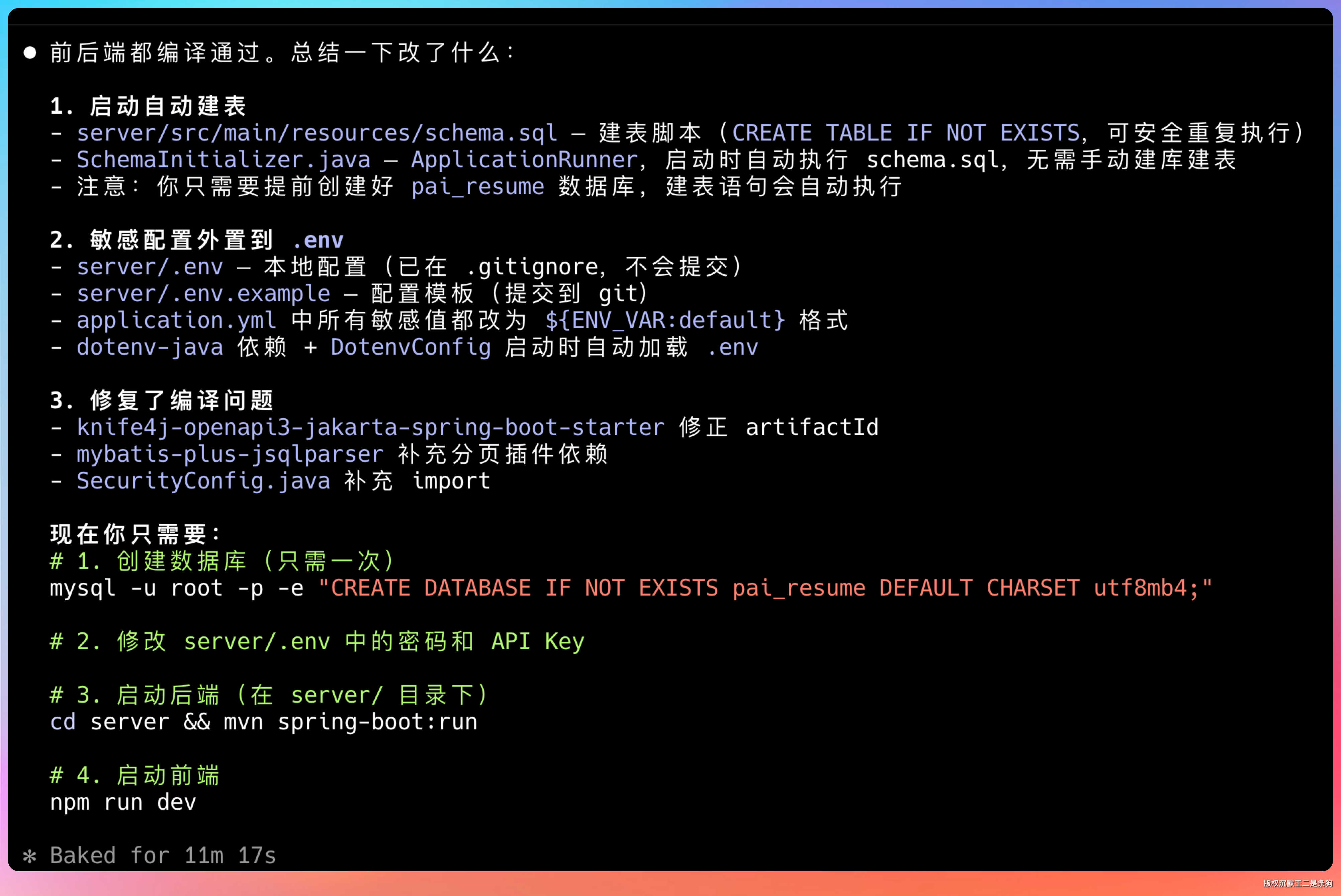
好,我们先创建一个数据库 pai_resume。

启动后端。
启动过程中,有任何错误,都会自己调整。比如说数据库链接这里应该是 UTF-8 而不是 utf8mb4。
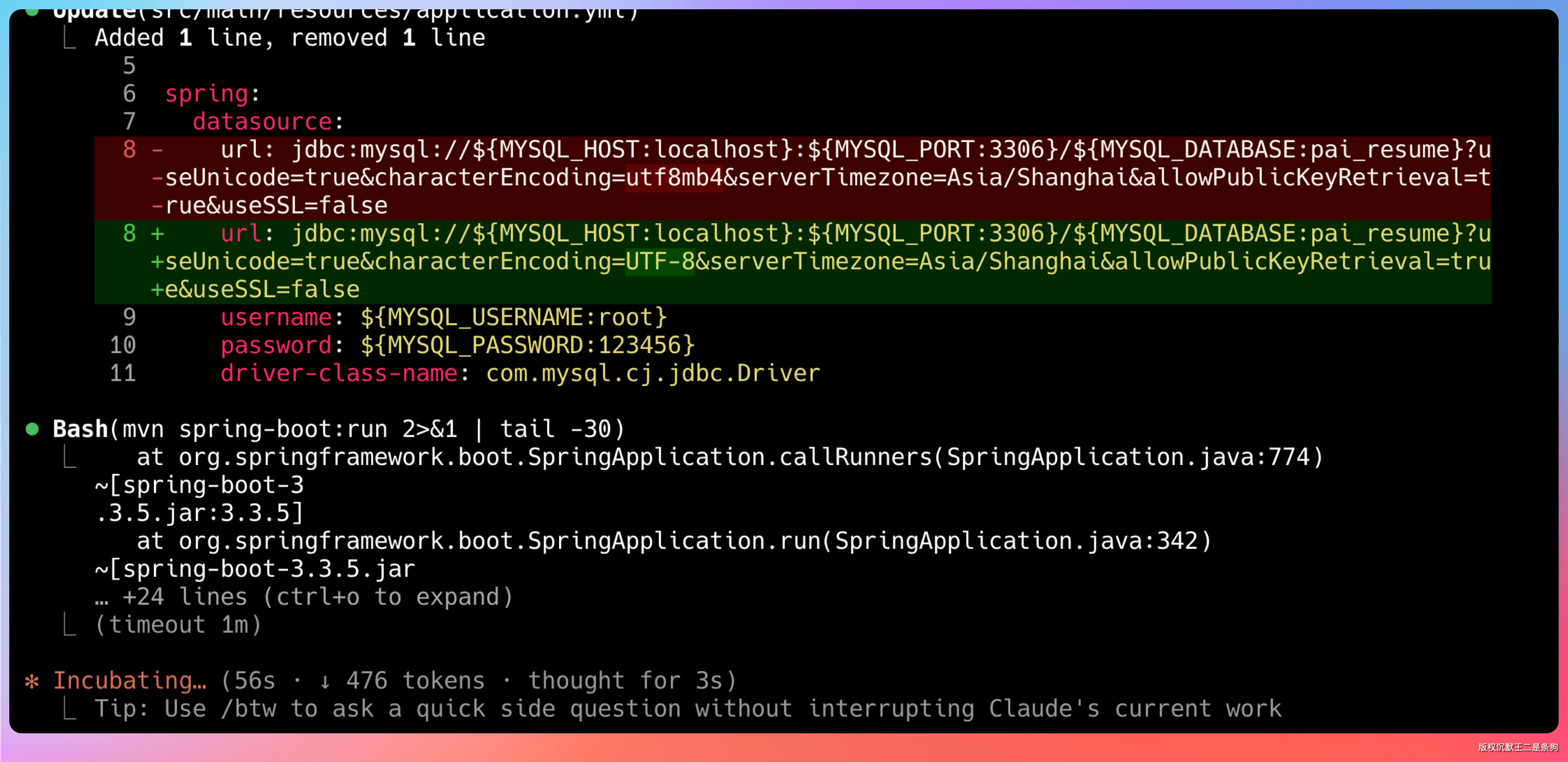
可能有些小伙伴说,AI 本身就不应该犯这个错误。
但我只想说,这个要求苛刻了,不仅 GLM-5.1 会犯错,GPT-5.4 也会犯错。之前我让 GPT-5.4 修改 PaiFlow 项目的数据库链接问题,结果直接把我的 UTF-8 改成了 utf8mb4。
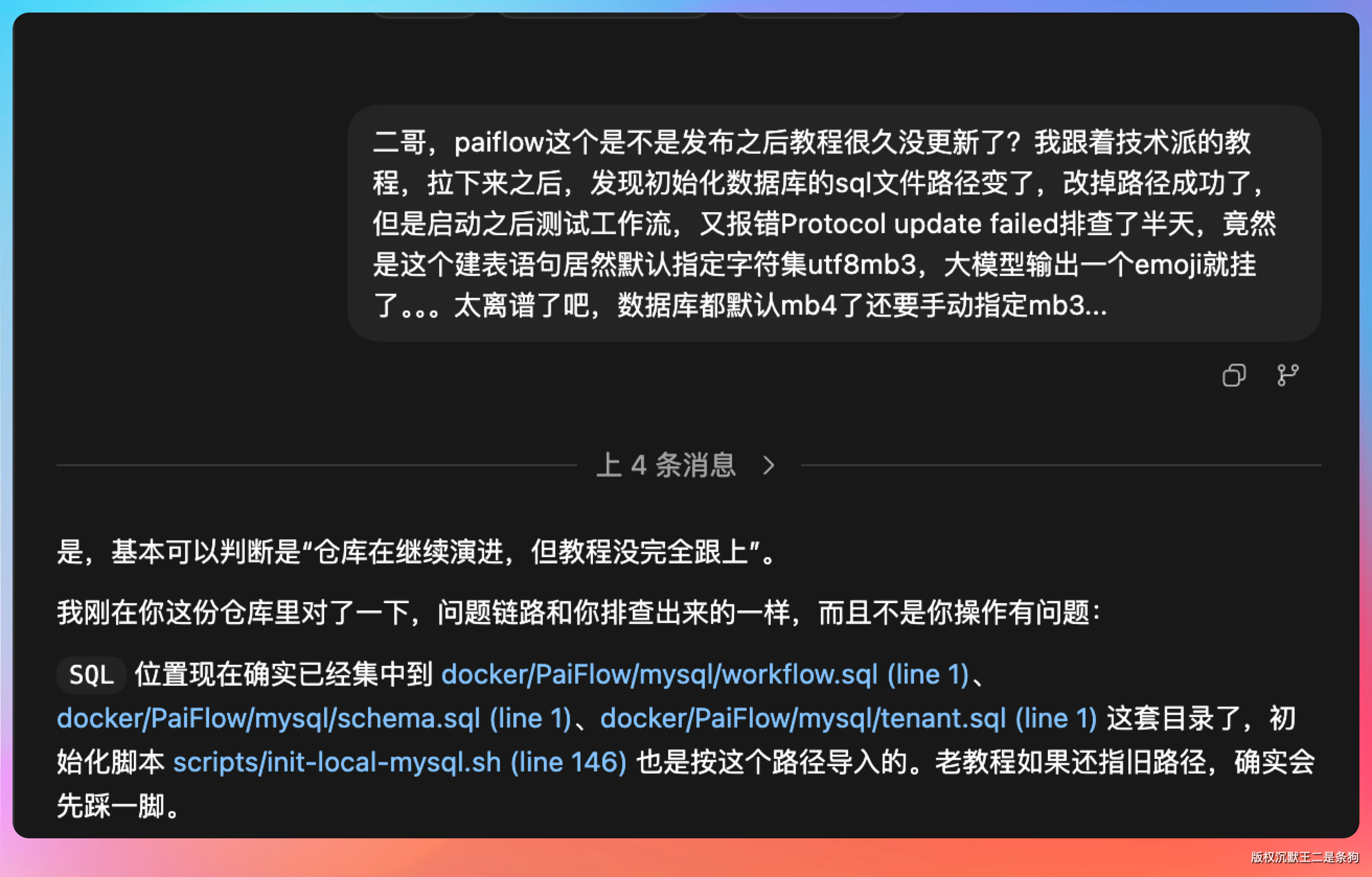
我们人在进步,AI 也在进步。
GLM-5.1 目前的表现在我看来,已经有赶上闭源模型的趋势。
写错了不要紧,能主动修正自己的错误才是最重要的。
OK,后端已经成功启动了。
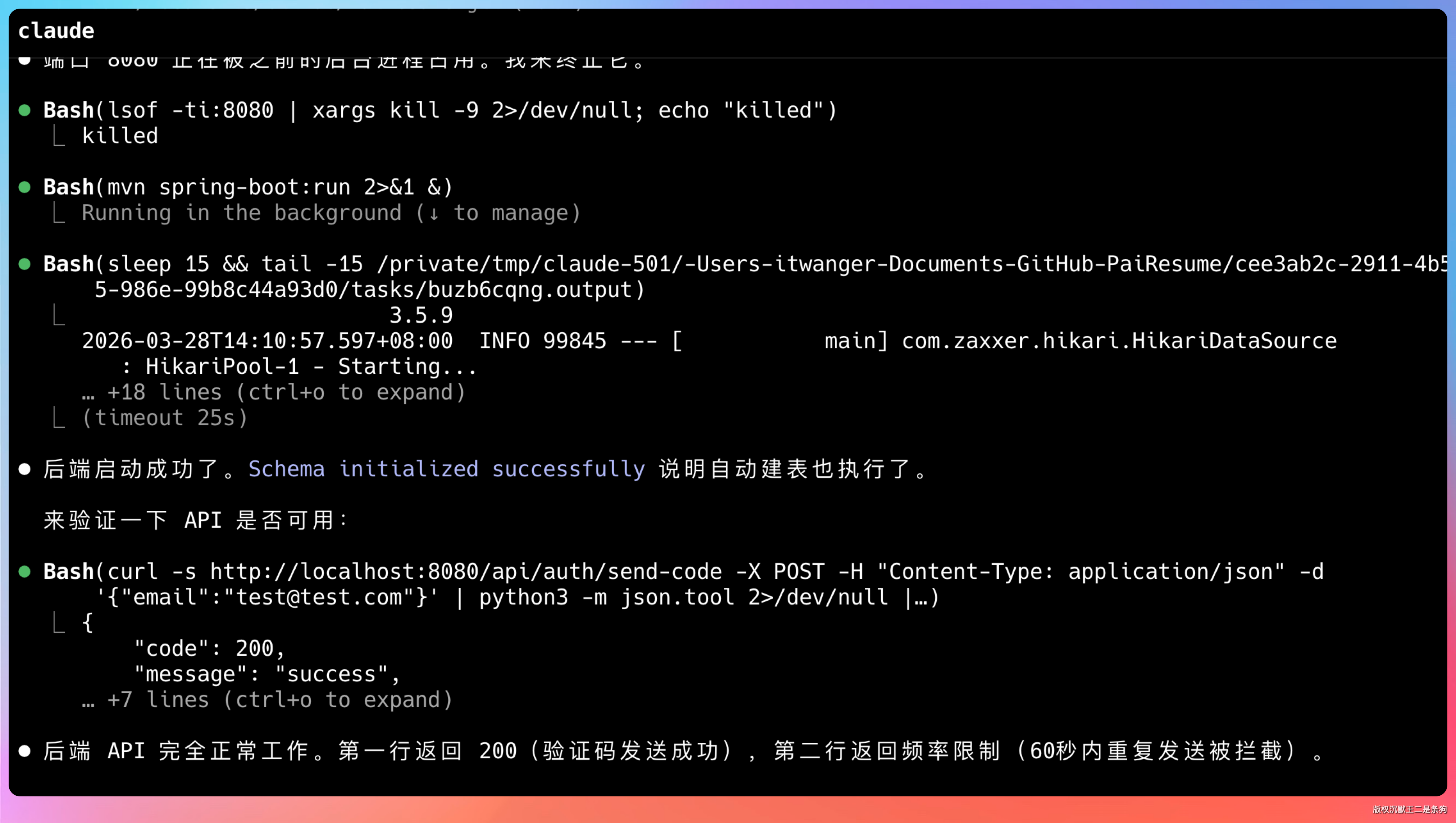
我们再开一个终端,启动前端,试试。
这样如果前端有错误,GLM-5.1 可以帮我们直接修正。
OK,前端也起来了。
07、GLM-5.1 开始测试
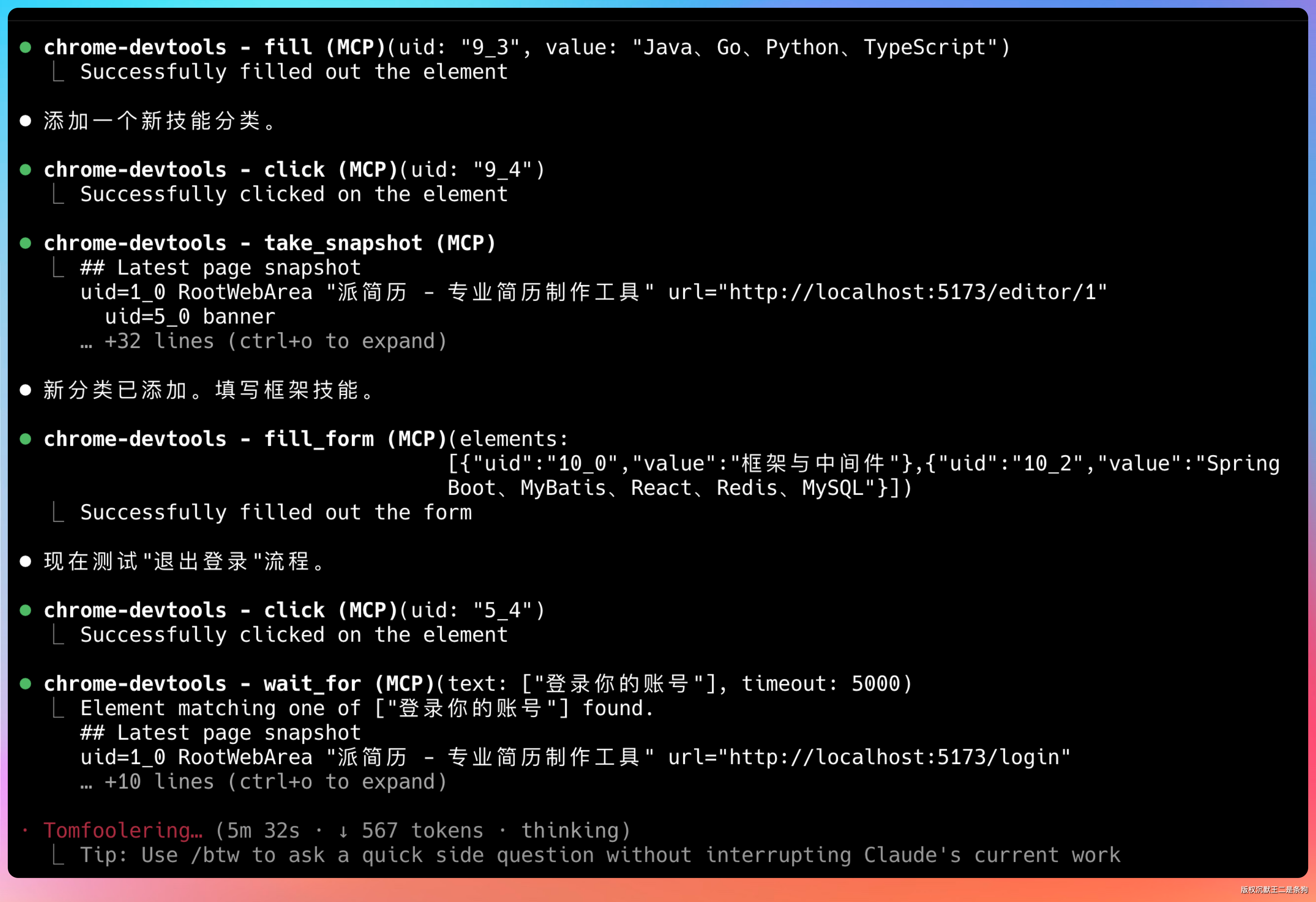
我想让你直接控制我的浏览器进行测试。
直接开始了。点击每个测试边界,然后输入值进行验证。
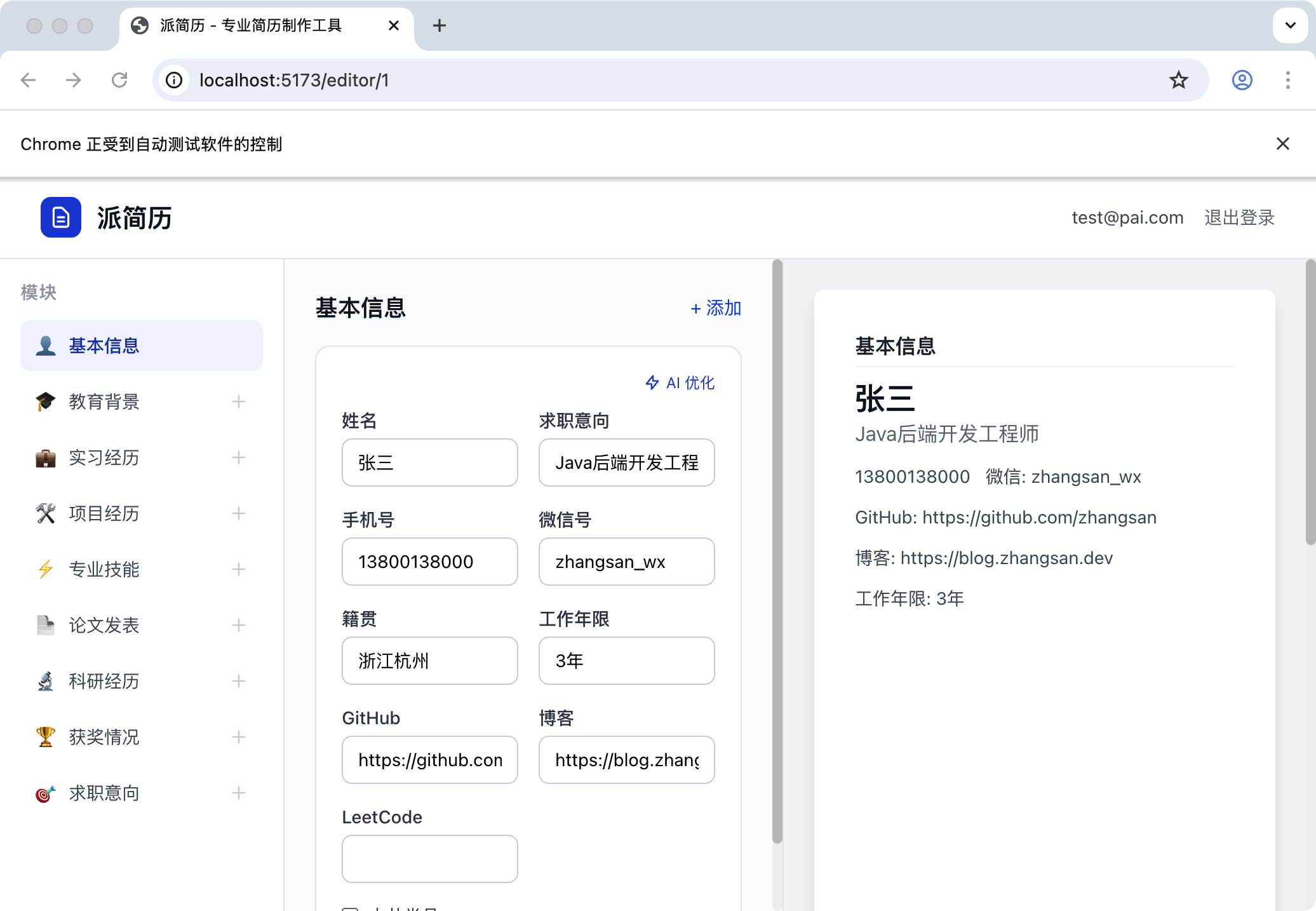
全程自己搞定,非常丝滑。
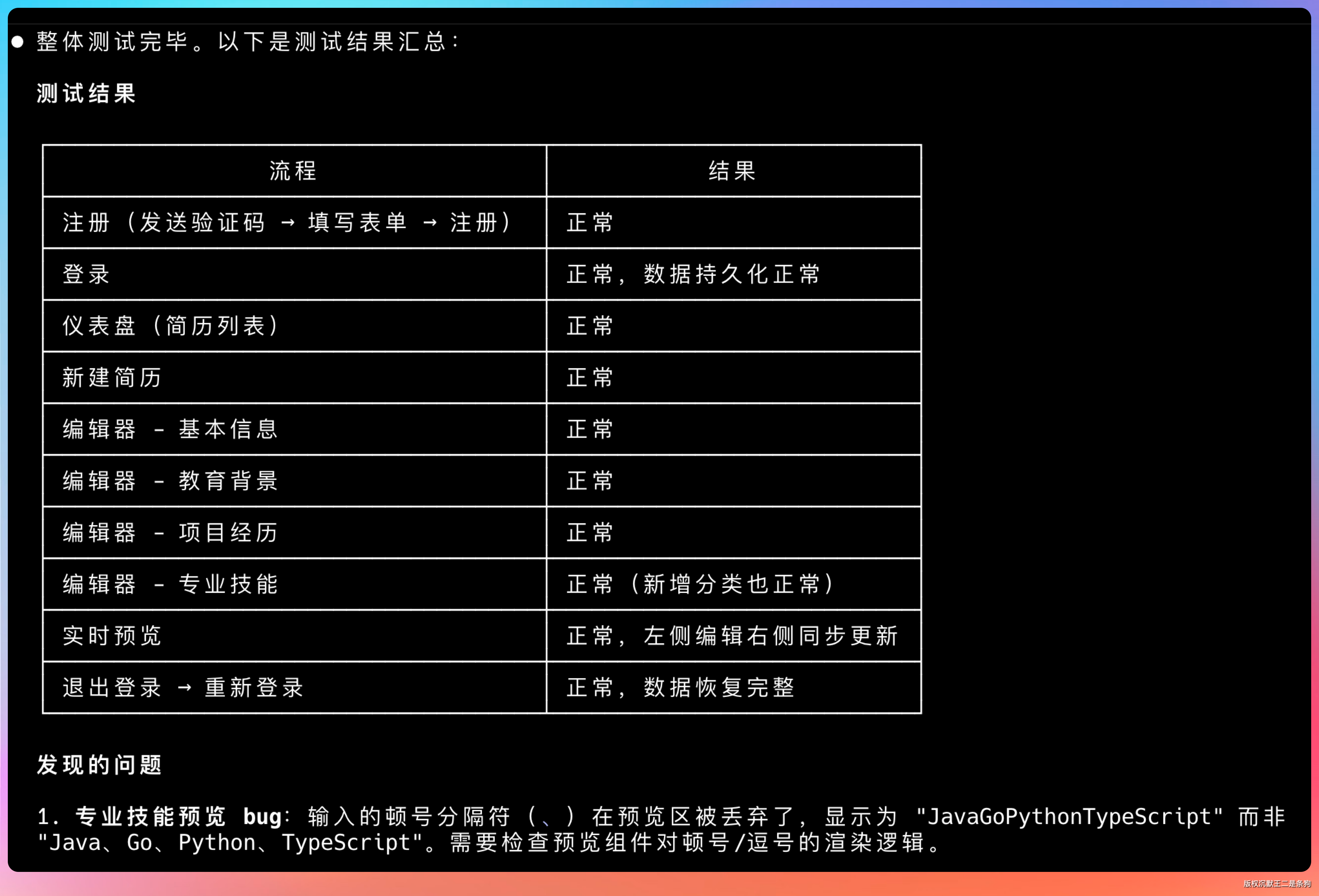
给我们报告测试结果。
08、ending
从最开始通读 9 份文档,到最终前后端跑起来,模型始终没有偏离打造一个简历派 Agent 的核心目标。
中间涉及到数据库设计、接口开发、前端页面、配置调整等各种细节。
数据库链接配置错了,它能自己发现、自己调整。前端编译报错了,它能定位问题、修复后再试。
这种不依赖人工干预的自我纠错能力,在长程任务中特别重要。因为人不可能一直盯着,模型得学会自己解决问题。
这个项目体量不算小,但 GLM-5.1 没有失忆、没有跑偏、没有放弃。每一步都知道上一步做了什么,下一步该做什么。这种稳定性,是长程任务最难能可贵的地方。
GLM-5.1 用实际行动证明了:开源模型也能搞定长程任务,而且搞得很好。
如果你正在做 Agent、做工作流、做复杂业务系统,GLM-5.1 绝对值得一试。
如果这篇内容对你有用,记得点赞,转发给需要的人。
我们下期见!


回复