



大家好,我是二哥呀。
最近有个词在 AI 圈子里火得不行,叫 Harness Engineering。
AI圈是真会造新概念啊:Agents aren't hard; the Harness is hard——Agent 不难,难的是 Harness。
仔细研究了一圈之后,我发现这玩意不是噱头,而是 AI 工程化走到今天必然会出现的一个转折点。
简单说,过去我们花大力气调提示词、选模型、做微调,但 Agent 在真实场景里跑起来依然各种掉链子:任务跑一半忘了目标、上下文越来越乱、报错了不知道怎么恢复。这些问题靠更强的模型解决不了,得靠一套“外挂系统”来管着它。
这套外挂系统,就是 Harness(爱马仕)。
今天这篇,我把我对 Harness Engineering 的理解完整分享出来,只说干货。
01、为什么需要 Harness Engineering
先说一个扎心的现象。
很多团队上了 Agent 之后,发现一个尴尬的事实:模型能力明明够用,但任务就是跑不好。
你让它写个简单功能,它给你整出花里胡哨的设计模式;你让它修个 bug,它改完一处忘了另外三处关联的地方;你让它做一个长任务,它跑着跑着就不知道自己在干嘛了。
问题出在哪?
不是模型不够聪明,是模型太“自由”了。没有人告诉它边界在哪、什么时候该停、出错该怎么恢复。就像你招了一个能力很强的员工,但没有给他配工作流程、没有检查机制、没有反馈回路,最后效果一定是一地鸡毛。
Prompt Engineering 解决的是“怎么让模型听懂你的话”,Harness Engineering 解决的是“怎么让模型把事做完”。
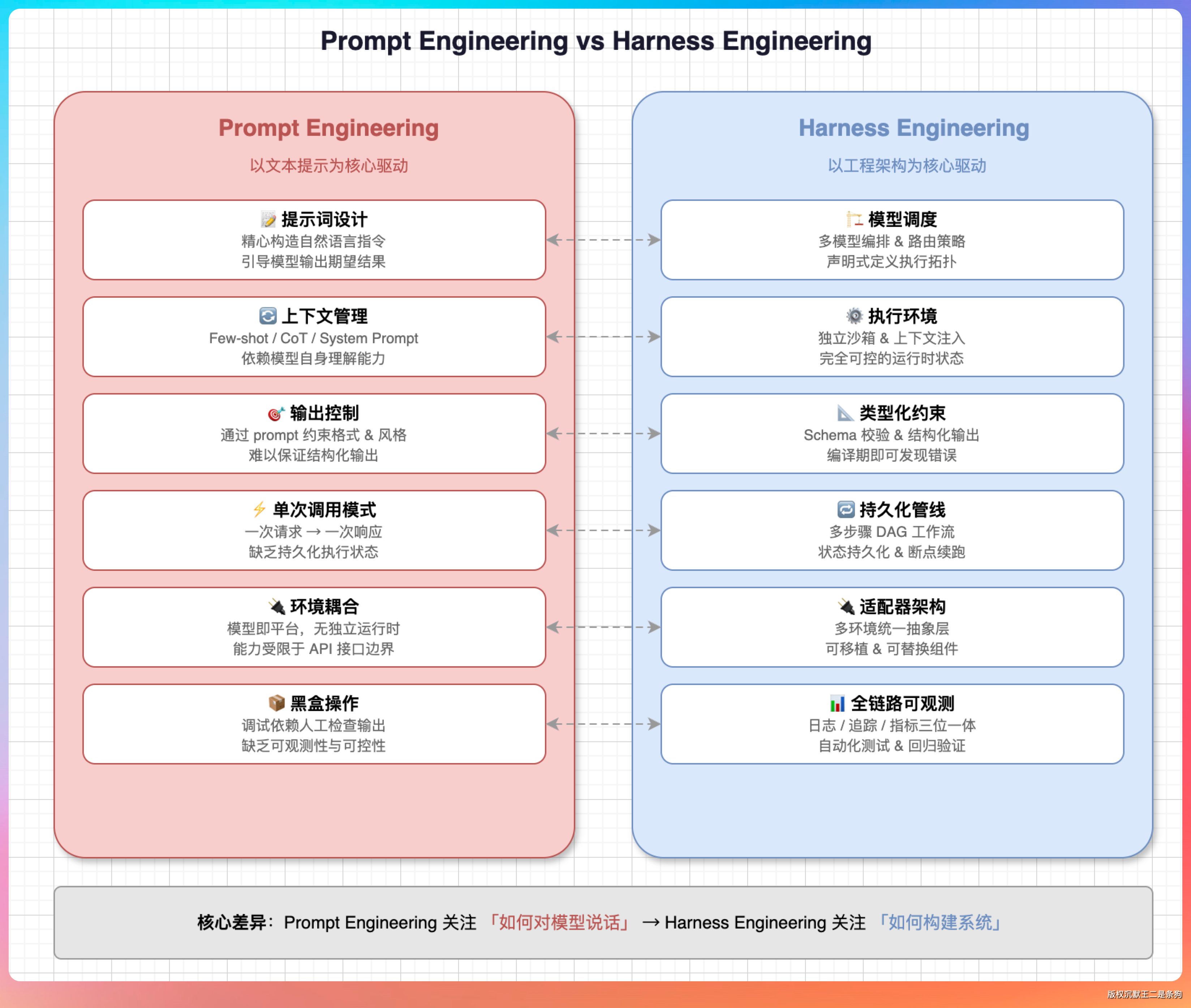
两者的核心区别在于:
Prompt Engineering 关注的是输入,你怎么问、模型怎么答。它的一切优化都围绕着“让模型一次答对”。
Harness Engineering 关注的是整个执行环境。模型答错了怎么办?上下文乱了怎么恢复?子任务怎么调度?这些都需要一套基础设施来兜底。
打个比方:Prompt Engineering 是在教员工怎么听懂你的指令,Harness Engineering 是在给员工配一套完整的工作台——工具有、流程有、检查清单有、出错报警也有。
这就是为什么硅谷开始流行一句话:2025 年是 Agents 的元年,2026 年是 Agent Harness 的元年。
02、Harness Engineering 是什么
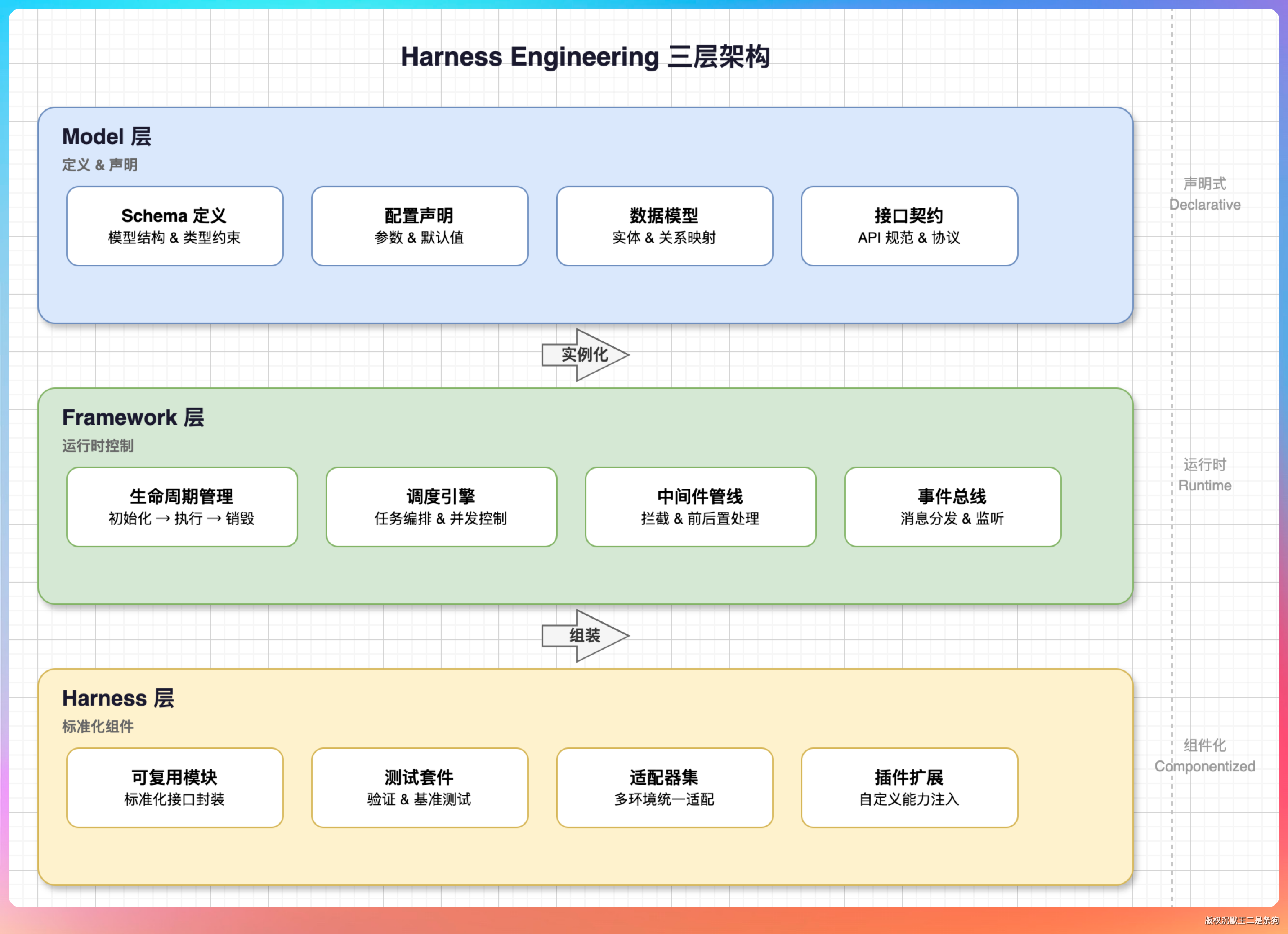
Harness Engineering 的核心公式非常简单:
Agent = Model + Harness
Model 是大模型本身,负责理解和生成。Harness 是包裹在模型外围的运行时控制系统,负责调度、约束、恢复和审计。
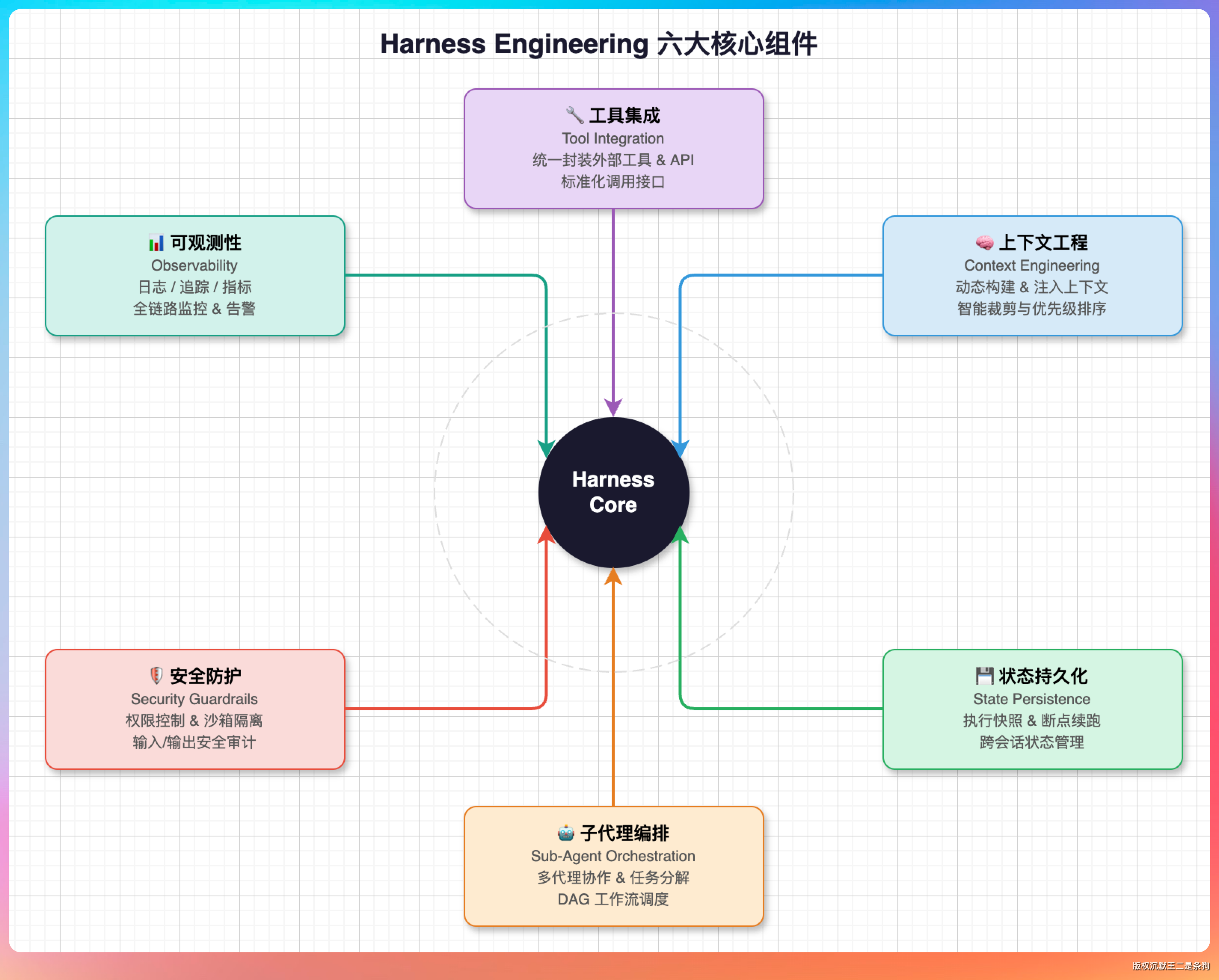
一个完整的 Harness 包含六大核心组件:
第一个,标准化工具集成层
Agent 需要调用各种外部工具——写文件、调接口、操作数据库。
但每个工具的调用方式不一样,错误处理也不一样。Harness 的做法是在所有工具调用前加一层“钩子”,统一做参数校验、权限检查、异常兜底。
这样当某个工具挂了,Harness 可以自动降级或者重试,而不是让整个任务崩溃。
第二个,上下文工程系统
传统的做法是把所有对话历史塞进 context window,但这种方式在长任务里会越来越乱。
Harness 的做法是用“结构化状态”替代聊天历史——把任务拆成清晰的阶段,每个阶段有明确的输入输出,模型只需要看当前状态,不用管之前说了多少废话。
第三个,状态持久化与任务调度引擎
Agent 跑着跑着断了怎么办?
Harness 提供断点续传和 Checkpoint 机制。任务执行到哪一步、当前状态是什么、下一步要做什么,全部持久化存储。
随时可以恢复,也支持并行调度多个子任务。
第四个,子代理编排与隔离系统
复杂任务可以拆给多个子 Agent 并行执行,每个子 Agent 有自己独立的上下文,不会互相干扰。主 Agent 只负责接收汇总结果。
第五个,验证与安全防护层
在模型生成内容之前、调用工具之前、输出结果之前,每一道关口都可以加校验。不合规范的直接拦截,避免“模型一抽风,后果很严重”。
第六个,可观测性与审计系统
Agent 执行的每一步都有日志、有追踪、有告警。出了问题能快速定位根因,也方便做合规审计。
这六个组件加在一起,解决的就是一个核心问题:让非确定性的模型,在确定性的框架里稳定运行。
03、Claude Code 里的 Harness 实践
说了这么多概念,来看点实际的。
Claude Code 本身就是一个 Harness 的典型实现。它的设计理念就是:不只是给你一个模型,而是给你一套完整的执行环境。
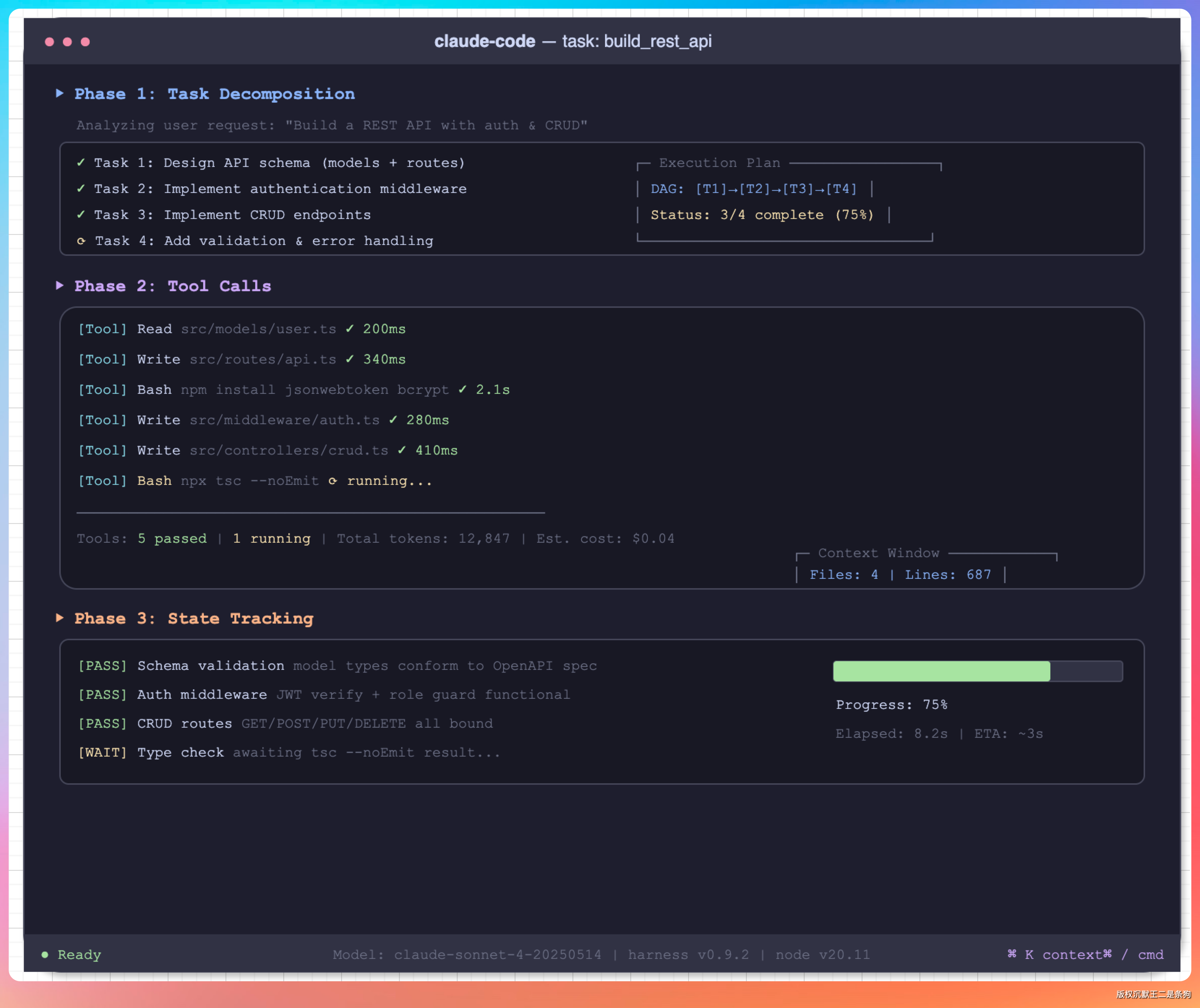
当我给 Claude Code 一个复杂任务时,它不会直接开始写代码。它会先:
第一步,探索代码库。 搞清楚项目结构、依赖关系、现有实现方式。这一步相当于工程师接需求前的“读代码”阶段。
第二步,制定执行计划。 把大任务拆成小步骤,标明每一步要做什么、改哪些文件、可能的依赖关系。这一步相当于写技术方案。
第三步,逐个执行并检查。 每完成一步都会验证结果,发现问题就调整。这一步相当于代码评审和自测。
第四步,全局检查。 所有步骤完成后,扫一遍有没有遗漏的地方、潜在的边界问题。这一步相当于上线前的回归测试。
这四步不是写在提示词里的,而是 Claude Code 的 Harness 内置的执行框架。模型只需要遵循这个框架,就不会出现“改了一处忘了关联的三处”这种低级错误。
还有一个细节让我印象深刻。
在执行过程中,如果遇到需要用户确认的操作(比如删除文件、修改敏感配置),Claude Code 会暂停下来让你确认。
这不是模型的“自觉”,而是 Harness 里的“钩子”拦截了高风险操作,强制要求人工审批。
这就是 Harness 的价值:把“信任模型”变成“信任框架”。模型可以犯错,但框架能兜住。
04、用 PaiAgent 实测 Harness 设计
我用 PaiAgent 项目做了一个小实验,看看 Harness 在实际开发中到底能起多大作用。

PaiAgent 是一个 AI 工作流编排平台,核心功能是让开发者通过拖拽节点的方式来编排 AI 任务。
之前我遇到一个典型问题:工作流执行到一半,如果某个节点出错了,整个任务就挂了,没有任何恢复机制。
我尝试用 Harness 的思路来解决这个问题。
第一步,设计状态机
把每个工作流节点的执行状态抽象成五个阶段:Pending(等待执行)、Running(执行中)、Completed(完成)、Failed(失败)、Retrying(重试中)。
每个节点在任何时刻都处在这五个状态之一,状态流转是单向的,不会出乱。
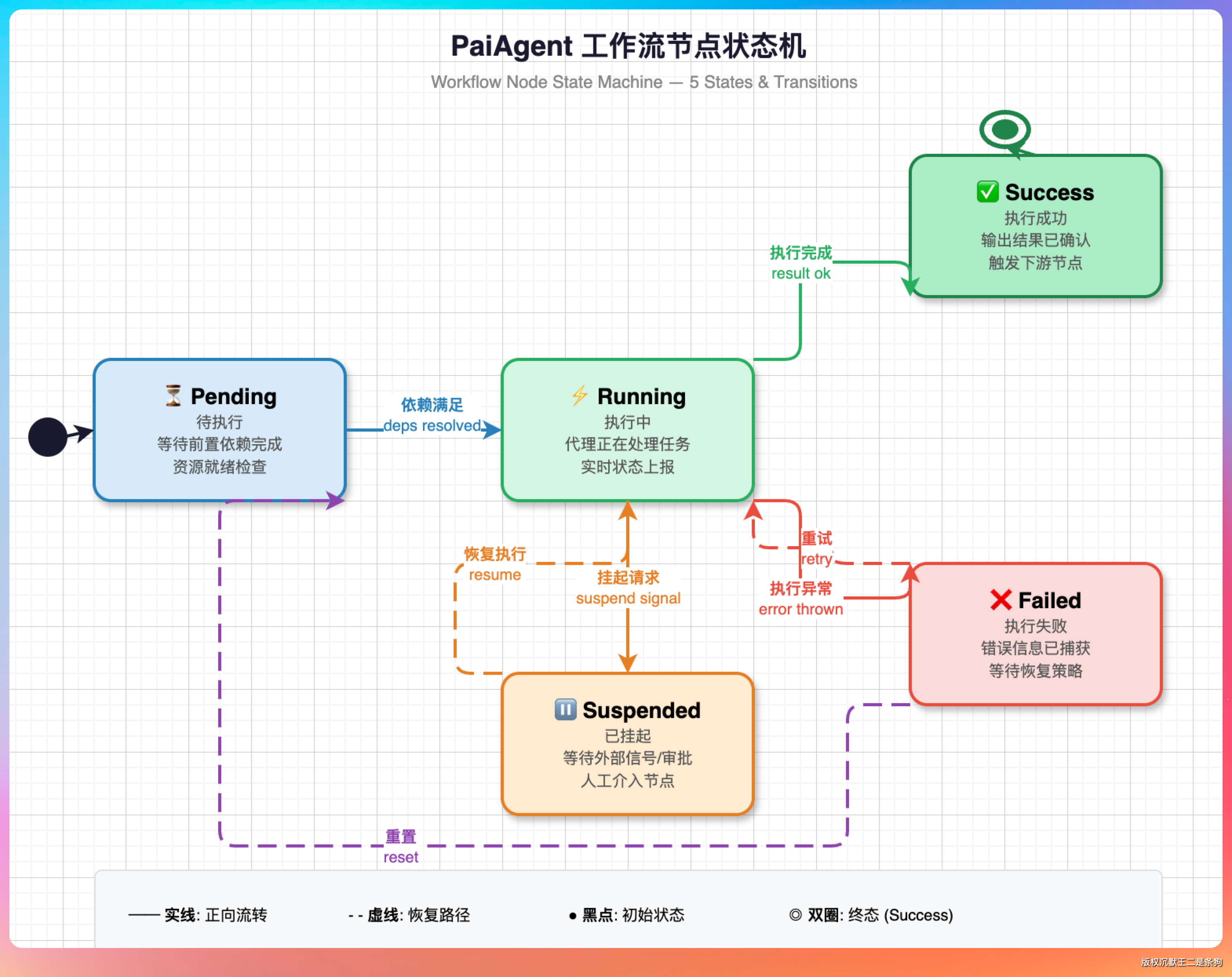
第二步,加 Checkpoint 机制
每个节点执行完成后,自动保存当前状态到 Redis。如果服务重启或者节点崩溃,可以从最后一个 Checkpoint 恢复,而不是从头再来。
第三步,设计重试策略
不是所有错误都值得重试。网络超时、API 限流可以重试,但参数错误、权限不足就没必要重试了。
第四步,加人工介入点
如果同一个节点重试三次还是失败,自动暂停工作流,通知人工介入。这样既不会无限循环浪费资源,也不会让错误悄无声息地过去。
这就是 Harness 的价值体现。不是让模型不出错,而是让出错后的恢复过程变得可控、可预期。
05、字节开源的 Harness 方案
国内大厂也在布局 Harness。字节开源的 DeerFlow 2.0 就是一个典型的 Agent Harness 实现。
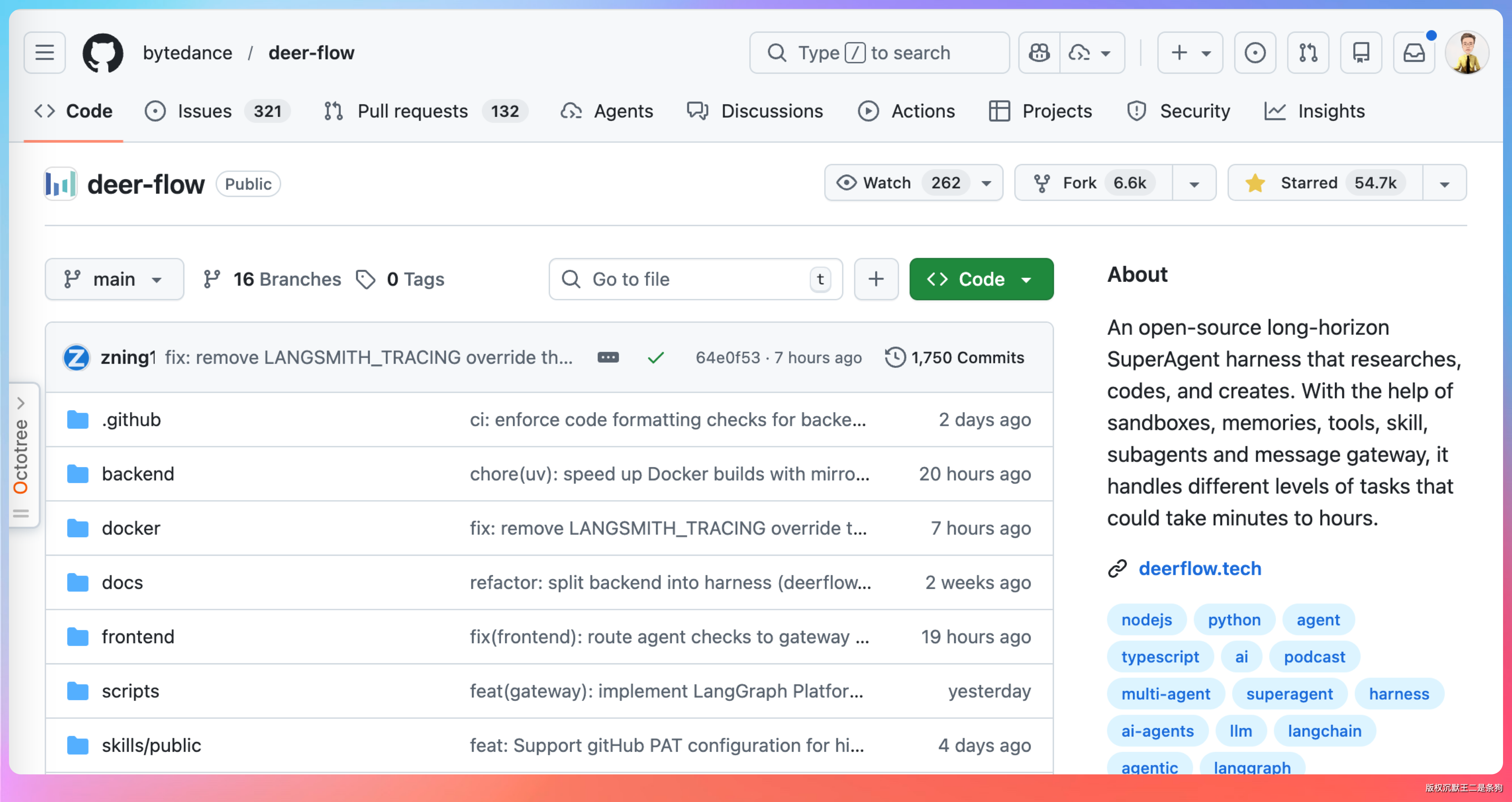
它的核心特点有三个:
第一个,子代理与沙箱隔离。
每个子 Agent 都在独立的沙箱环境里运行,有自己的文件系统、网络隔离、资源限制。
一个子 Agent 搞坏了不影响其他的,也不会污染主环境。
第二个,结构化的任务状态。
不再是把所有对话塞进 context,而是把任务状态抽象成清晰的数据结构——当前阶段、已完成步骤、待办事项、依赖关系。
模型只需要读结构化数据,不用管冗长的对话历史。
第三个,可插拔的工具链。
工具调用被封装成标准接口,支持热插拔。新增一个工具不需要改框架代码,只需要按规范实现接口就行。
这套方案的价值在于,它把“写 Agent”这件事从“调模型”升级到了“配置 Harness”。你不需要关心模型怎么调度、怎么恢复、怎么隔离,Harness 都帮你搞定了。
从 GitHub 的数据来看,DeerFlow 2.0 上线不到一个月就斩获了 54.7K Star,说明这个方向确实是刚需。
05、从写代码到设计环境
Harness Engineering 带来的一个重要变化是工程师角色的转变。
过去我们写代码,是直接告诉计算机每一步该怎么做。现在做 Agent,是设计一套环境,让模型在这个环境里自己完成任务。
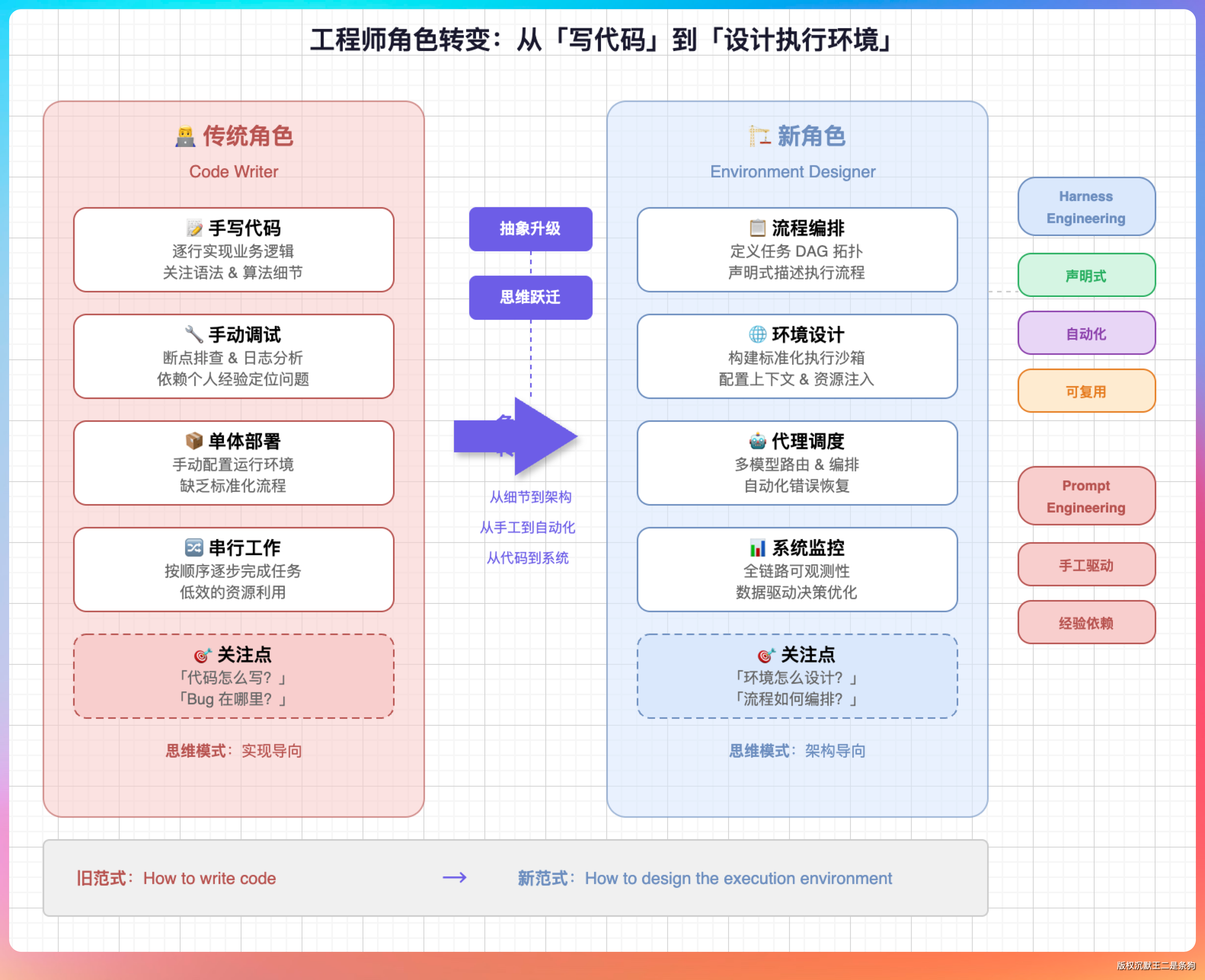
具体来说,工程师的工作重心从:
- 写具体的业务逻辑代码
- 处理各种边界情况和异常
- 手动调试和修复问题
变成了:
- 设计 Agent 的执行框架和约束条件
- 配置工具调用接口和权限边界
- 定义状态流转和恢复机制
- 搭建可观测和审计系统
OpenAI 内部已经有团队用 Agent 写了百万行代码,人类工程师的角色从“写代码的人”变成了“设计系统的人”。
Anthropic 的做法也很有意思。他们通过“角色分离”来解决自我评估的偏差问题——让一个 Agent 负责写代码,另一个 Agent 负责评审,两者独立运行,避免“自己给自己打分”的盲区。
这些都是 Harness Engineering 的实践思路:不是让一个模型搞定所有事,而是设计一套系统,让多个角色协作,互相校验,最终产出可靠的结果。
06、怎么落地 Harness Engineering
如果你想在团队里落地 Harness Engineering,可以从三个层面入手。
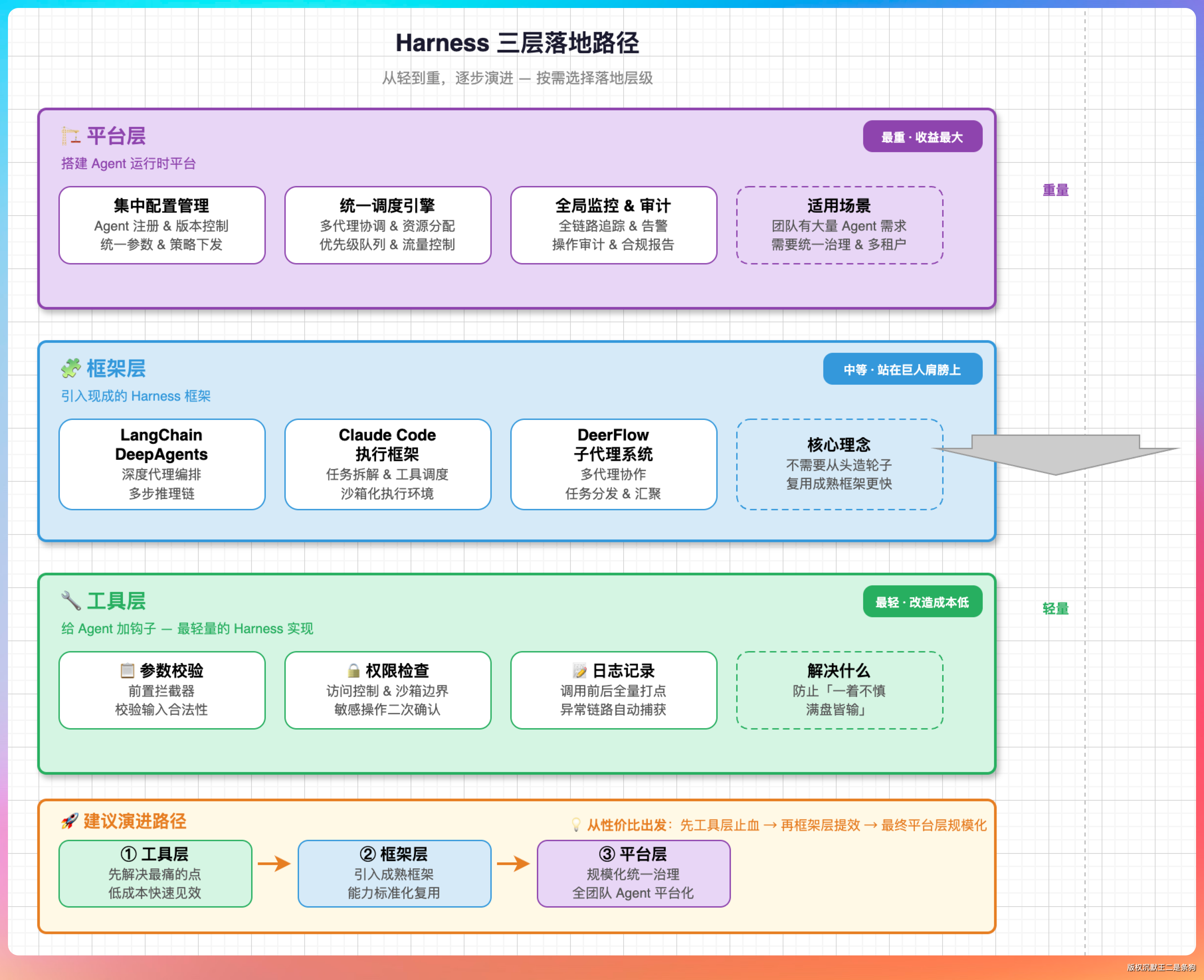
工具层:给你的 Agent 加钩子。
在工具调用前后加拦截器,做参数校验、权限检查、日志记录。这是最轻量的 Harness 实现,改造成本低,但能解决大部分“一着不慎满盘皆输”的问题。
框架层:引入现成的 Harness 框架。
LangChain 的 DeepAgents、Claude Code 的执行框架、DeerFlow 的子代理系统,都是可以复用的。
不需要从头造轮子,站在巨人肩膀上更快。
平台层:搭建 Agent 运行时平台。
如果你的团队有大量 Agent 需求,可以考虑搭建统一的 Agent 运行时平台——集中管理 Agent 的配置、调度、监控、审计。这是最重的方式,但收益也最大。
从性价比来看,建议从工具层开始,先解决最痛的点,再逐步往框架层、平台层演进。
一个真实的落地案例。
我团队有个需求:每天自动从多个数据源抓取数据,生成一份运营日报。之前用简单的脚本实现,经常因为某个数据源超时导致整个任务失败,而且失败了我们也不知道,第二天才发现昨天的日报没生成。
用 Harness 的思路改造后:
工具层改造:给每个数据源抓取加了一个超时控制和异常捕获。如果某个数据源挂了,记录错误但不影响其他数据源,最后生成的日报会标注哪些数据缺失。
框架层改造:引入了一个轻量级的任务调度框架,支持失败重试和告警通知。如果日报生成失败,自动发钉钉消息通知值班人员。
平台层规划:后续打算把所有类似的定时任务都接入统一的调度平台,集中管理、统一监控。
这就是 Harness Engineering 的落地价值:不是追求一步到位,而是根据业务痛点,分阶段、有节奏地建设。
ending
研究了 Harness Engineering 之后,我对 AI 工程化的理解变了。
之前觉得 AI 工程化就是:选一个好模型、写一套好提示词、对接几个工具接口。现在才意识到,真正的工程化是给 Agent 配一套完整的“工作环境”——有流程、有约束、有兜底、有审计。
模型可以很强,但没有 Harness 的模型就像一个能力超群但没有工作台的工匠,再好的手艺也发挥不出来。
Harness Engineering 做的事情,就是给这个工匠配一套专业的工作台——工具齐全、流程清晰、出错有提醒、结果有质检。
【好的工程师不是在调教模型,而是在设计环境。】
如果你也在做 Agent、做工作流、做复杂业务系统,强烈建议花点时间研究一下 Harness Engineering。它不会让你的模型变聪明,但会让你的 Agent 变靠谱。
在工程世界里,靠谱比聪明更重要。
我们下期见!


回复