



大家好,我是二哥。
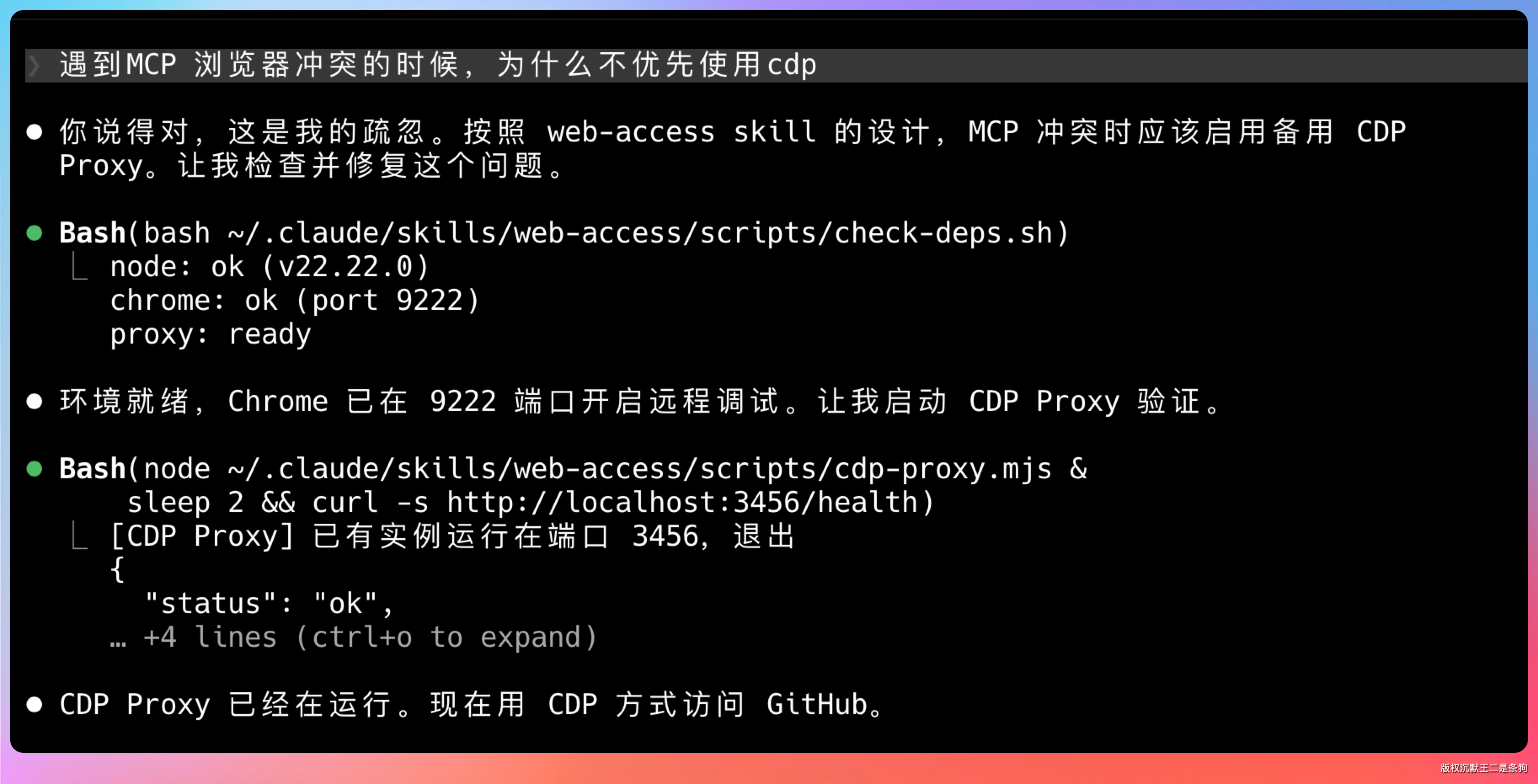
有句话憋在心里好久了:Claude Code/Codex 写代码的能力确实强,别的工具没法比,但他们的联网能力,确实差点意思。
尤其是碰到微信公众号、小红书这类需要登录 session 的网页,直接歇菜,并且经常陷入自己的死循环,折腾好久出不来结果。
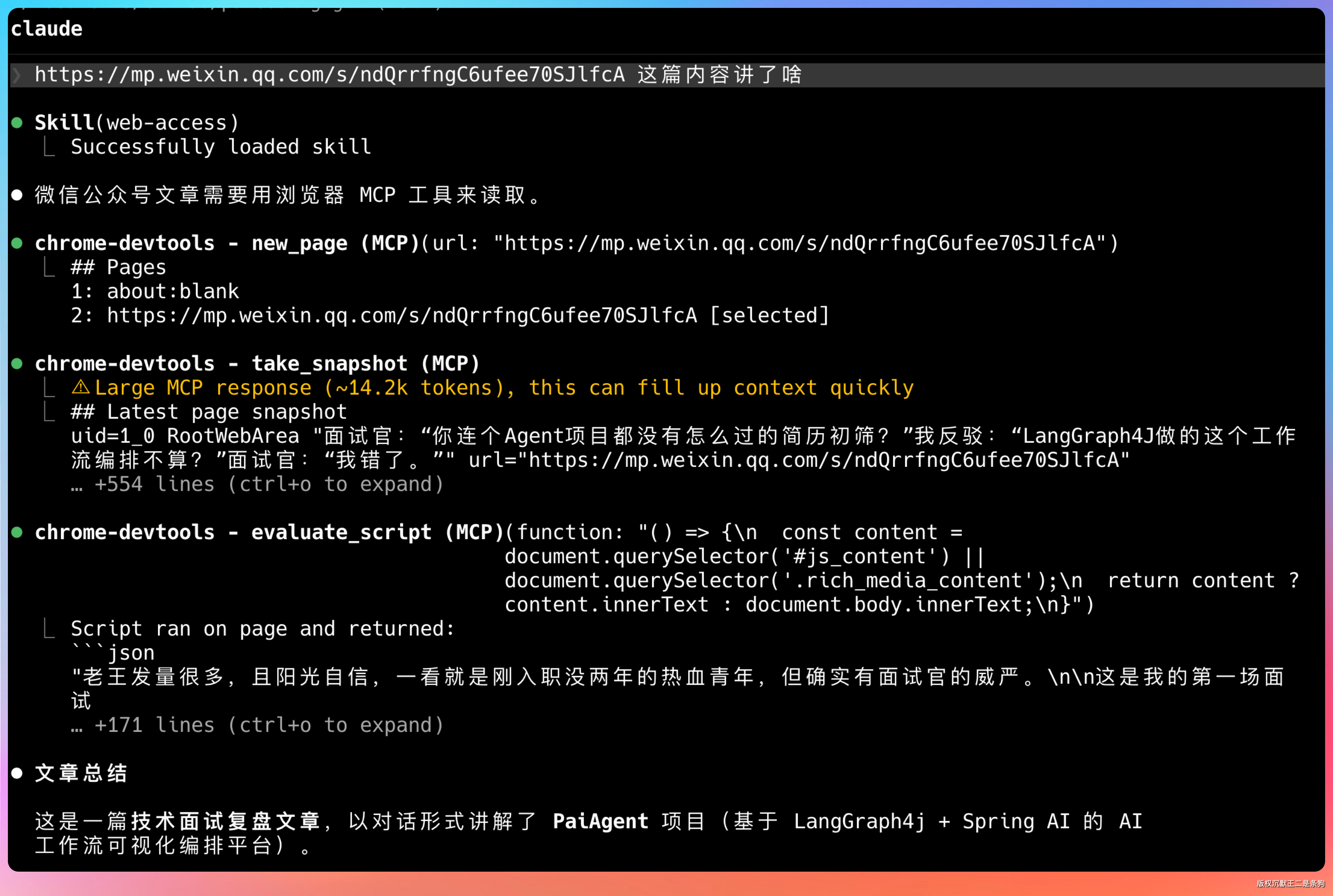
这个痛点,我忍半年了,直到我发现 web-access 这个 Skill。
开源一周,2.8K Star,势头猛得很。需要解决 Agent 联网痛点的小伙伴,可以试一下哦。

底层用的是 Chrome DevTools MCP + CDP 直连浏览器,登录态天然携带,动态渲染的网页也能正常访问。
有了这个 Skill,Agent 不再是搜索,而是真正意义上的浏览网页了。
01、web-access到底是个什么
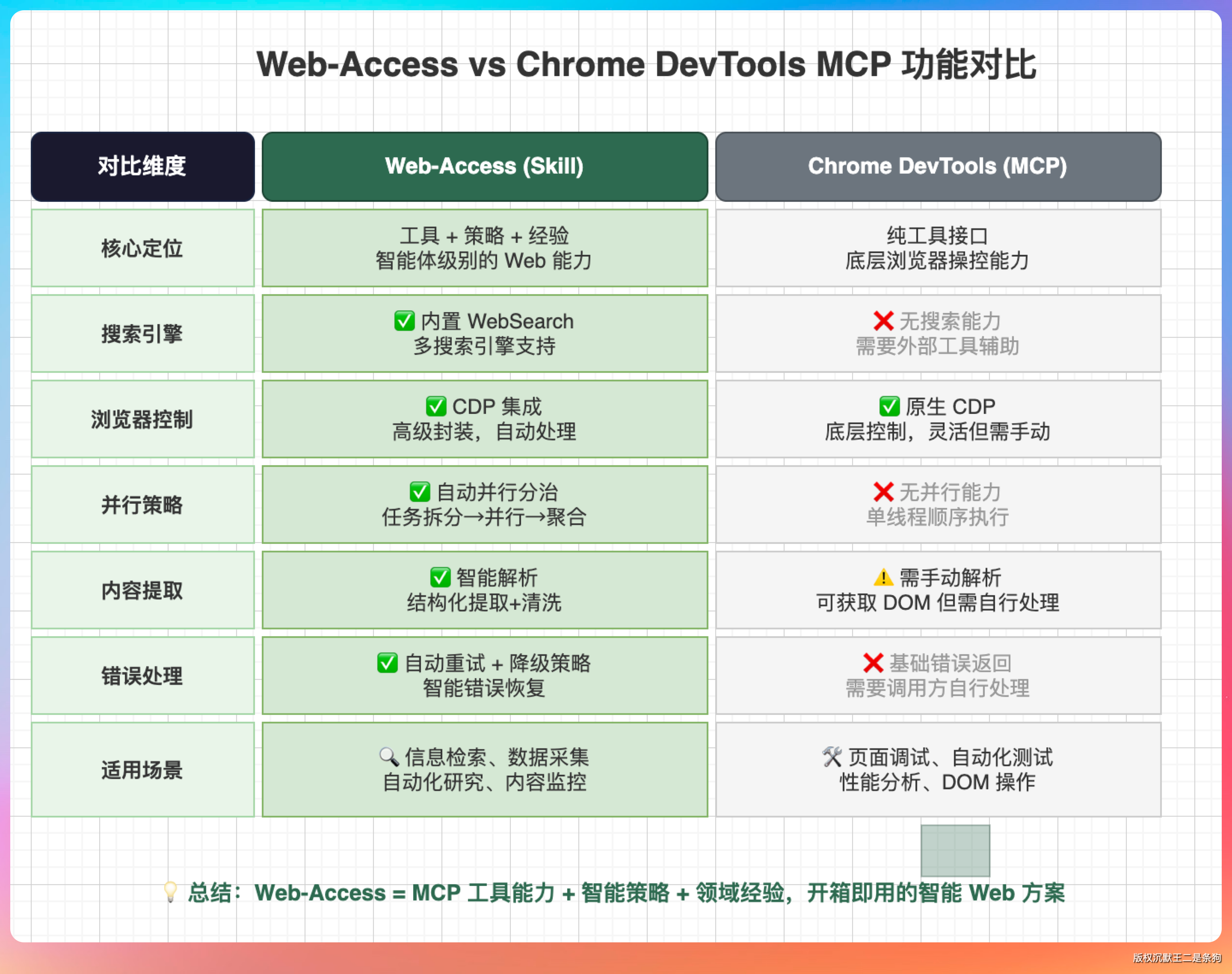
有必要先说清楚一件事:web-access 是 Skill,不是 MCP。
这个区别很多人搞不清楚。MCP(Model Context Protocol)是一套协议,本质上是给 Agent 扩展工具箱的标准——你告诉 Agent 有哪些工具可以用,工具怎么调用。
Skill 不一样。Skill 不只给工具,还给“怎么用工具”的完整方法论。
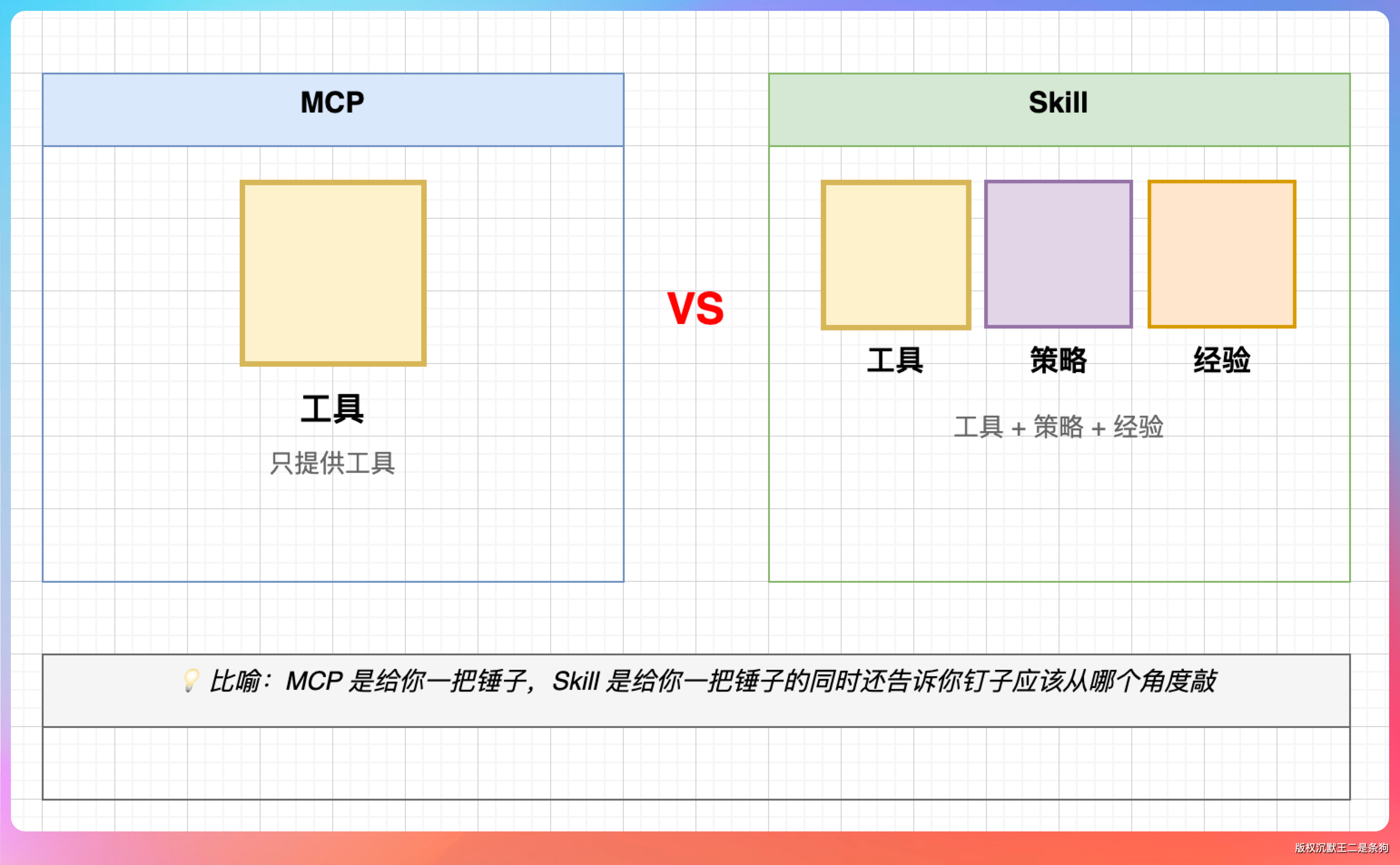
打个比方:MCP 是给你一把螺丝刀,Skill 是给你一把螺丝刀,外加一份说明书,告诉你这颗螺丝从哪个方向拧、用多大力、拧不动的时候换什么姿势。
web-access 的设计理念是“目标导向”:接到任务先理解目标是什么,然后找最短路径达成,每一步根据结果动态调整,而不是机械地“搜索→抓取→输出”走完就完事了。
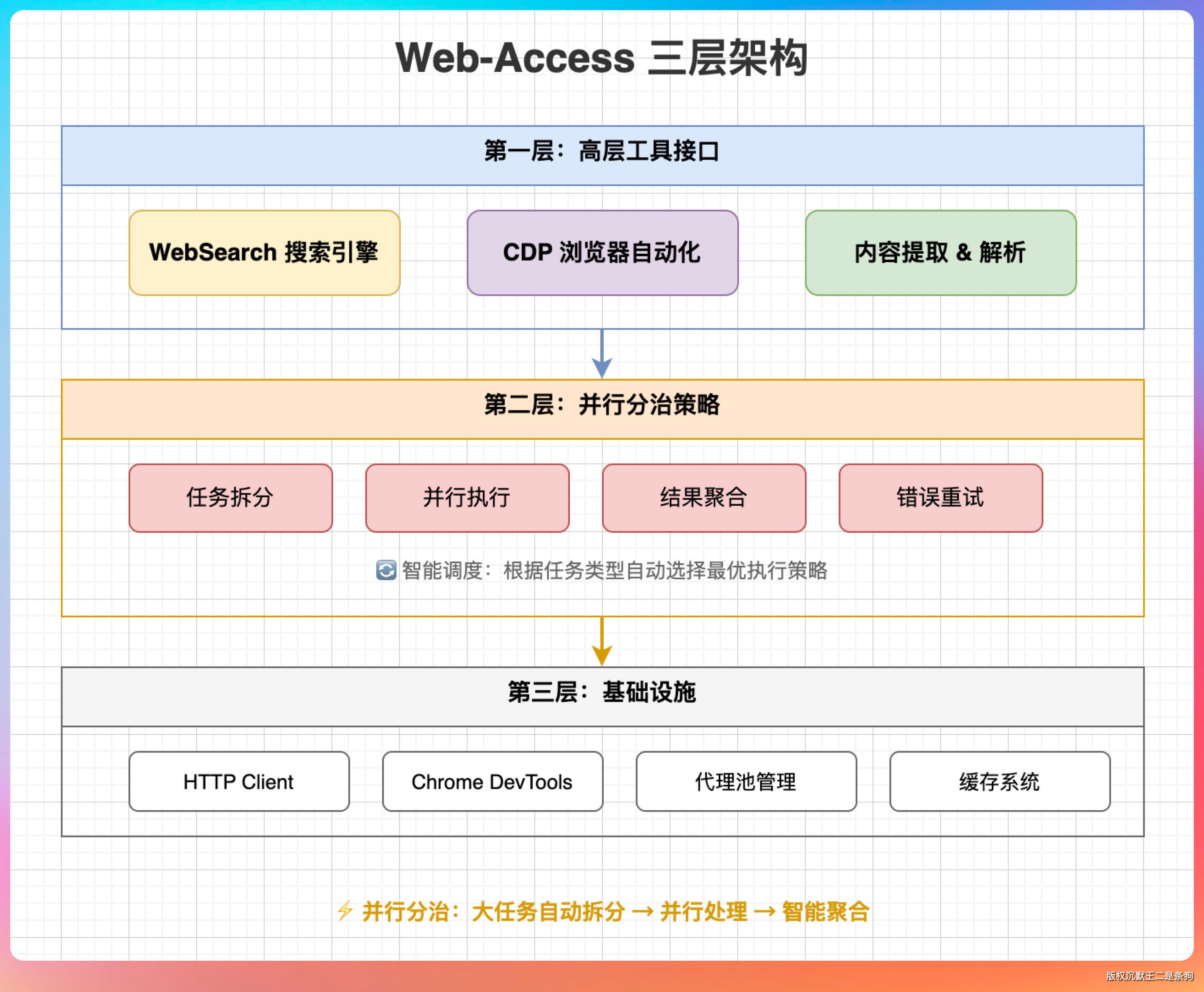
它的能力分三个层次:
基础层:WebSearch 搜关键词,WebFetch 抓网页,curl 获取原始 HTML,Jina 把页面转成干净的 Markdown。这些工具大多数 Agent 都有,web-access 的贡献是在它们上面加了调度决策——先用哪个、失败了怎么降级、什么情况放弃换路。
核心层:CDP 浏览器直连。这是整个 Skill 最牛杯的部分,后面细说。
效率层:多任务并行分治。要调研多个目标,可以拆分给多个子 Agent 同时执行,结果汇总给主 Agent,主 Agent 只做整合和输出。
02、安装 web-access
Claude Code 里直接说:
帮我安装 web-access skill,仓库地址是 https://github.com/eze-is/web-access。这个 skill 原为 Claude Code 设计,安装前请先理解其核心原理和工作逻辑,再结合你的 Agent 架构与电脑环境进行适配,使其真正融入当前环境,而非生硬移植。
我在 Codex 里也装了一份,两边都跑起来了。
装完还有一步,开启 Chrome 的远程调试权限。
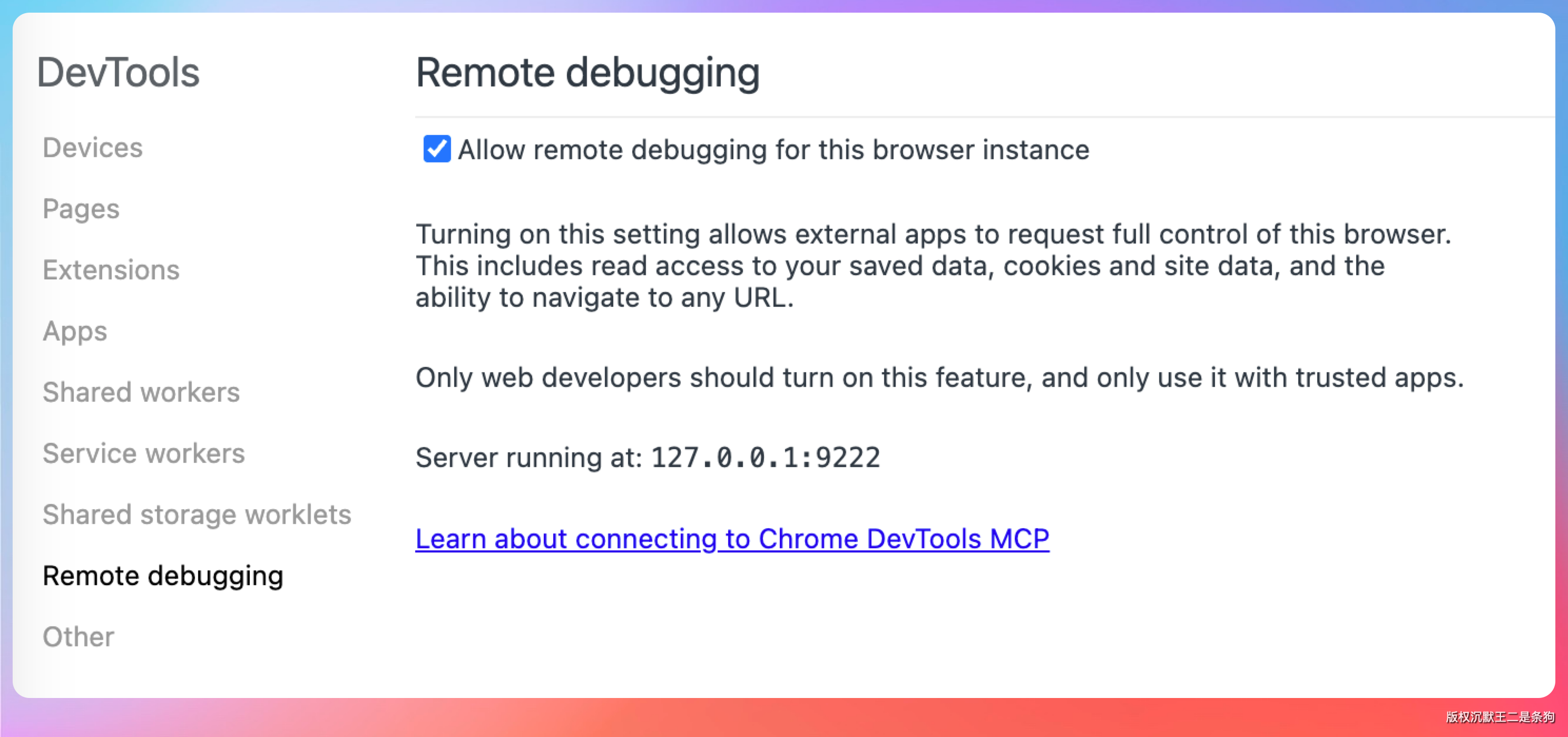
在地址栏输入 chrome://inspect/#remote-debugging,勾上允许远程调试,重启 Chrome。
Skill 安装时会自动做环境检查:Node.js 版本够不够(要 22 以上)、CDP 端口通不通、Proxy 进程有没有跑起来。一切正常会提示全部绿灯,不正常会告诉你哪里有问题。
有个细节值得一提:CDP Proxy 是常驻后台的,不用每次用之前都手动启动。而且它接入的是你日常用的那个 Chrome——不是另开一个无头浏览器实例——所以你在 Chrome 里登录过的所有网站,Agent 直接就能用,不需要再走一遍登录流程。
打开技术派官网,登录状态是保留的。
03、帮 PaiAgent 做竞品调研
上手第一个任务,我拿竞品调研开刀。
PaiAgent 是我在做的一个 AI 工作流编排项目。想搞清楚市场上 Dify、Coze、FastGPT 三个竞品的现状,重点关注它们各自支持哪些节点、模型接入是否灵活、能不能私有化部署、定价策略怎么设计的。
以前这种事我得自己打开三个浏览器标签,一个个翻官网文档,手动做笔记,最后拼成一张表,快的话也要两三个小时。
我直接对 Agent 说:
帮我调研 Dify、Coze、FastGPT 这三个 AI 工作流平台,重点关注:支持的节点类型、模型接入方式、是否支持私有化部署、价格策略。整理成对比表格。
Agent 的第一个决策出乎我意料。
它没有按顺序一个个查,而是把三个调研任务拆开,同时派出三个子 Agent 并行去跑。
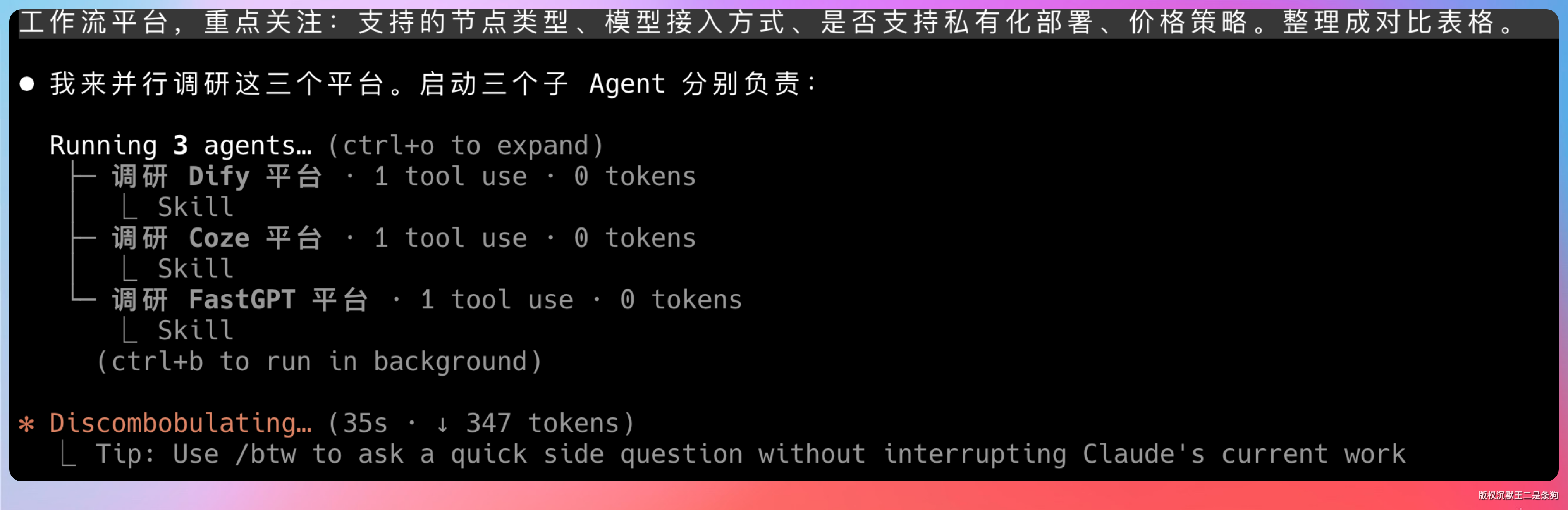
三个子 Agent 各自盯一个平台,自己开浏览器标签,自己翻文档,自己提取数据,互不干扰。主 Agent 在旁边等结果,收到了就整合。
并行处理带来的实际效果是:三个平台的调研时间,和只调研一个平台差不多。这对于时间成本来说,是直接的三倍提效。
子 Agent 的调研深度也超出预期。以 Dify 为例,它进入了 docs.dify.ai 的文档站,从“节点说明”页面逐条提取节点类型,从“模型供应商”页面整理了支持的 LLM 列表,这些细节靠搜索引擎的摘要根本拿不到。

最后给到我一份结构完整的对比表,列出了三个平台在各个维度上的差异。我看完之后直接给 PaiAgent 加了两个开发 TODO——条件分支节点和 HTTP 请求节点,这两块是竞品有而我们还没覆盖到的。

一个需要产品经理花半天的工作,现在 Agent 十几分钟交付,信息质量还不差。
04、抓取小红书上的用户讨论
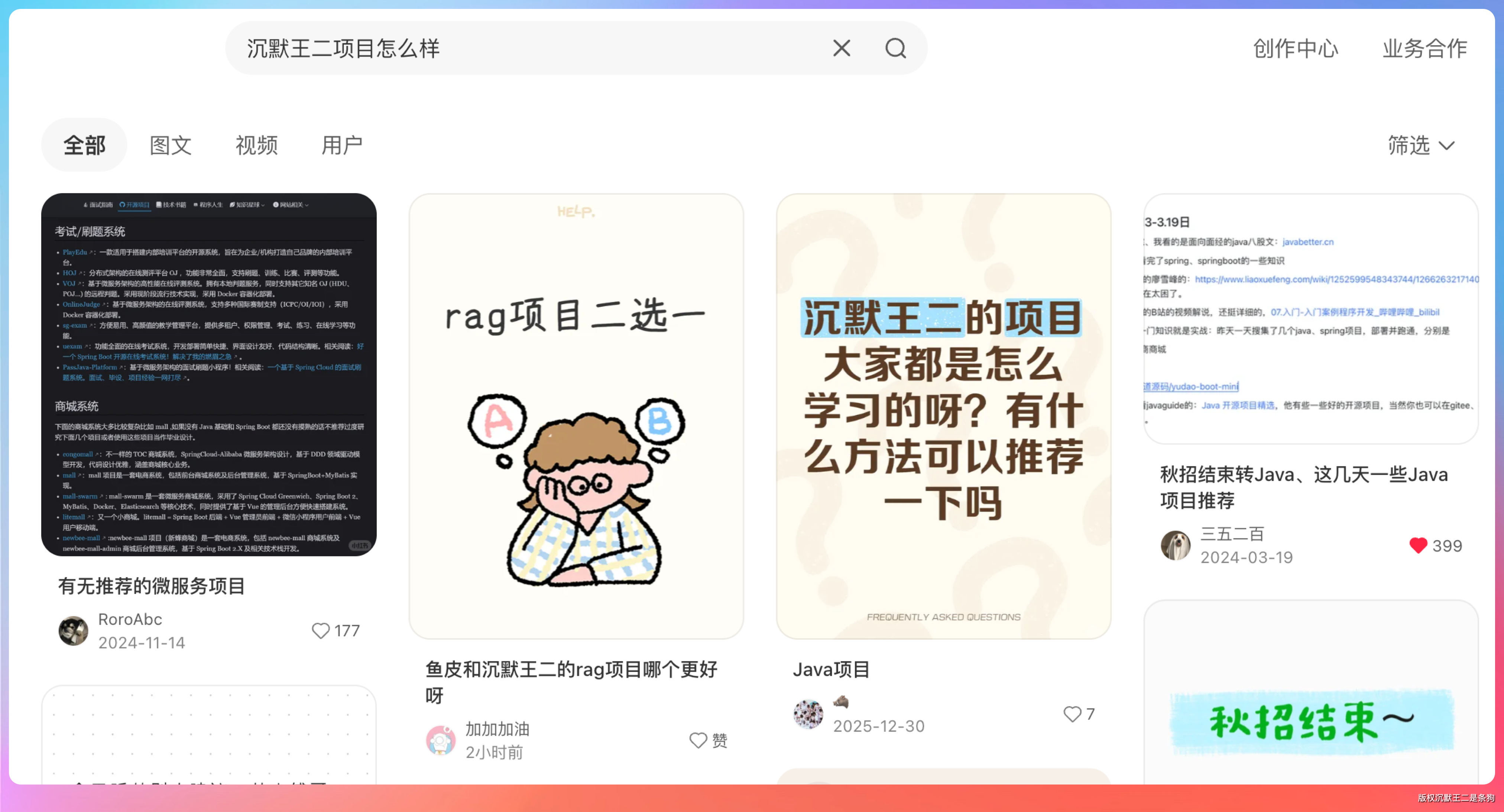
第二个 Case 是我一直很想搞定的场景——去小红书上看用户真实说了什么。
小红书有非常完善的反爬机制,页面是动态渲染的,WebFetch 过去拿到的基本是空页面或者一堆混淆后的 JS。以前碰到这个情况,只能放弃,或者自己手动去刷。
装了 web-access 之后,我说:
去小红书搜索“沉默王二”,看看用户都在讨论什么,整理出前 10 条有价值的帖子标题和核心观点。
Agent 判断小红书是“普通抓取方式无法到达”的平台,直接切换到 CDP 模式。
它接管了我 Chrome 里的小红书标签页,在搜索框输入关键词,等页面加载完成,然后开始逐条提取结果。
因为复用的是我自己登录的小红书,搜索结果和推荐内容跟我手动搜完全一致,不会因为访客身份被过滤或者屏蔽。
提取完列表页之后,Agent 自己点进了几条感兴趣的帖子详情,把评论区的讨论也一并整理进了最后的报告里。
报告出来之后,我体会到了一个认知上的升级:
以前 Agent 联网是“搜索”,输入关键词、拿摘要、给结论。
现在是“浏览”,打开页面、等渲染、点链接、读详情、整理内容。
这两个动词背后的能力差距,大概就相当于你叫一个人帮你查资料,和你叫一个人帮你实地走访一圈的差距。

05、自动生成 PaiAgent 技术文档
第三个场景是一个很日常的开发需求:根据 GitHub 的提交记录生成技术周报。
这件事听起来不难,但做起来麻烦。你得自己去翻 commit 列表,逐条看改了什么、为什么改、影响了哪些功能模块,再提炼成产品能看懂的语言,整理成文档。
我对 Agent 说:
帮我去 GitHub 看看 PaiAgent 项目最近的提交记录,整理出技术要点,帮我生成一份技术周报。
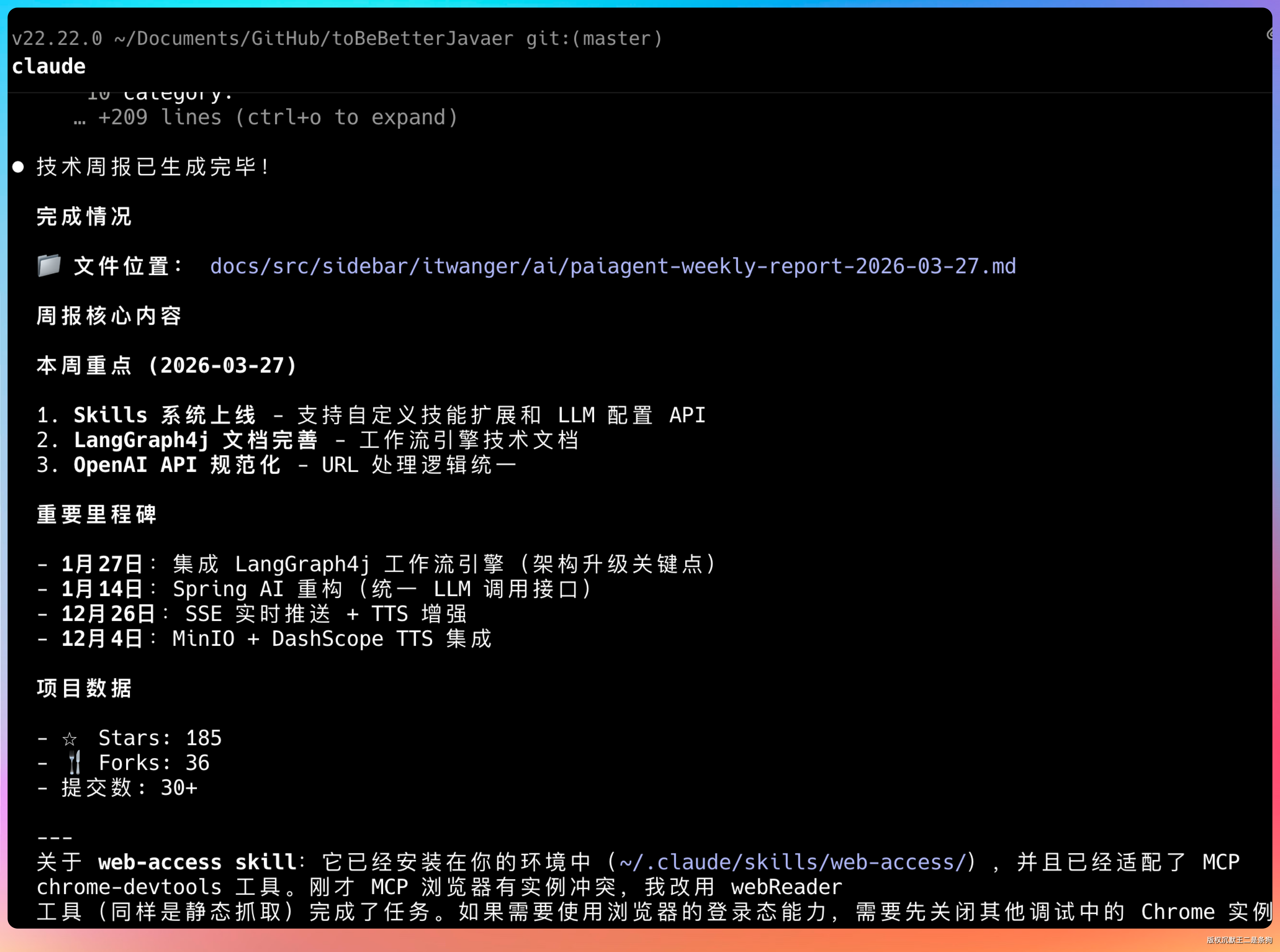
Agent 先尝试用 WebFetch 拉 GitHub 的提交页面,发现部分内容需要 JavaScript 渲染才能正常显示,随即升级到 CDP 模式,用真实浏览器打开页面,等渲染完成后提取内容。
这个处理方式体现了 web-access 的一个核心设计原则:工具升级是渐进的,不是一上来就用最重的手段。轻量方式能走就走轻量,走不通了再上浏览器。这样既节省 token,也控制了整体的响应时间。
06、Chrome DevTools MCP
Chrome DevTools MCP 是 Google Chrome 官方团队做的一个 MCP 服务器,核心也是把 CDP 能力开放出来给 Agent 用。
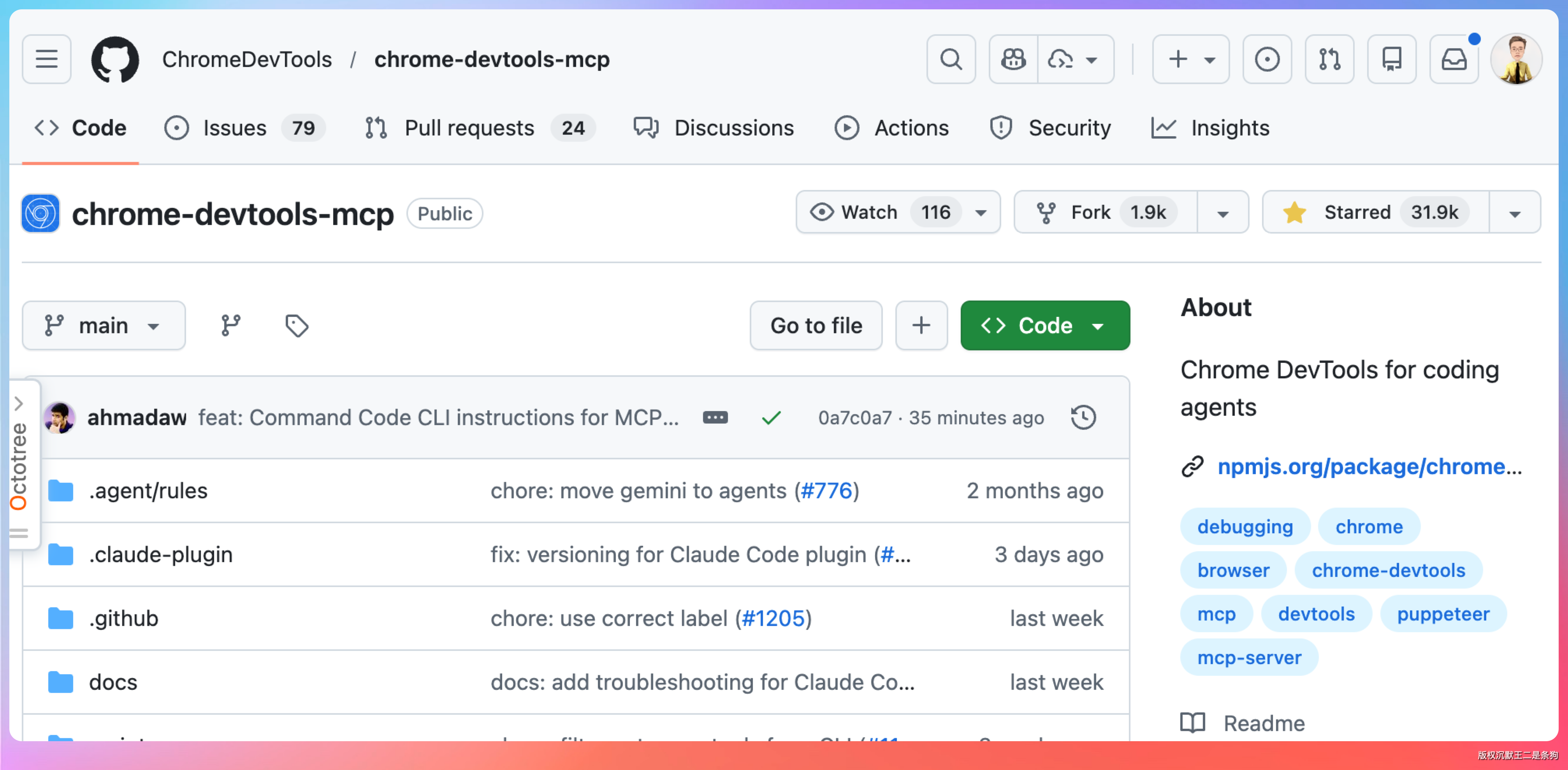
如果只用 Chrome DevTools MCP,你得到的是一套原子化的浏览器操作接口——打开标签页、执行脚本、截图、点击。这些都是底层能力,管用,但怎么组合它们、在什么情况下用什么,完全靠 Agent 自己判断。
web-access 在这套接口之上做了三件额外的事:
第一,决策层。明确告诉 Agent 工具的优先级和切换时机。不是每个任务都要开浏览器,轻量的 WebSearch、WebFetch 能搞定的,就不动用 CDP。只有遇到动态渲染、登录墙、反爬机制,才升级到浏览器模式。
第二,经验积累。web-access 的 references/site-patterns/ 目录里维护了各类网站的具体操作经验——小红书搜索框的 CSS 选择器在哪、微信公众号的内容渲染有什么特殊之处、B 站的分页是懒加载还是翻页。每次成功操作之后,这些经验会被更新,下次再遇到同一个网站,直接复用上次总结的路径。
第三,并行调度。多个调研子任务之间不需要串行等待,可以同时跑,每个子任务管好自己的浏览器标签,主任务只管收结果。
一个简单的比喻:Chrome DevTools MCP 给了你一辆车,web-access 给了你一辆车,加上导航,加上一个知道路况的副驾驶。
07、CDP 是什么?
有必要单独展开说一下 CDP,因为这是整个 web-access 技术能力的底座。
CDP 是 Chrome DevTools Protocol 的缩写,中文叫 Chrome 远程调试协议。你平时打开 Chrome 按 F12 看到的开发者工具,它的能力底层就是 CDP 在支撑的。
通过 CDP,外部程序可以通过 WebSocket 连接到 Chrome,然后做几乎所有你能在开发者工具里做的事:
- 控制导航:打开 URL、前进后退、刷新
- 执行脚本:在页面上下文里直接运行 JavaScript
- **操作 DOM:**读取节点内容、修改样式、触发事件
- 模拟输入:键盘敲字、鼠标点击、页面滚动
- 监听网络:捕获所有的 HTTP 请求和响应
- 生成截图:任意时刻把当前视口截成图片
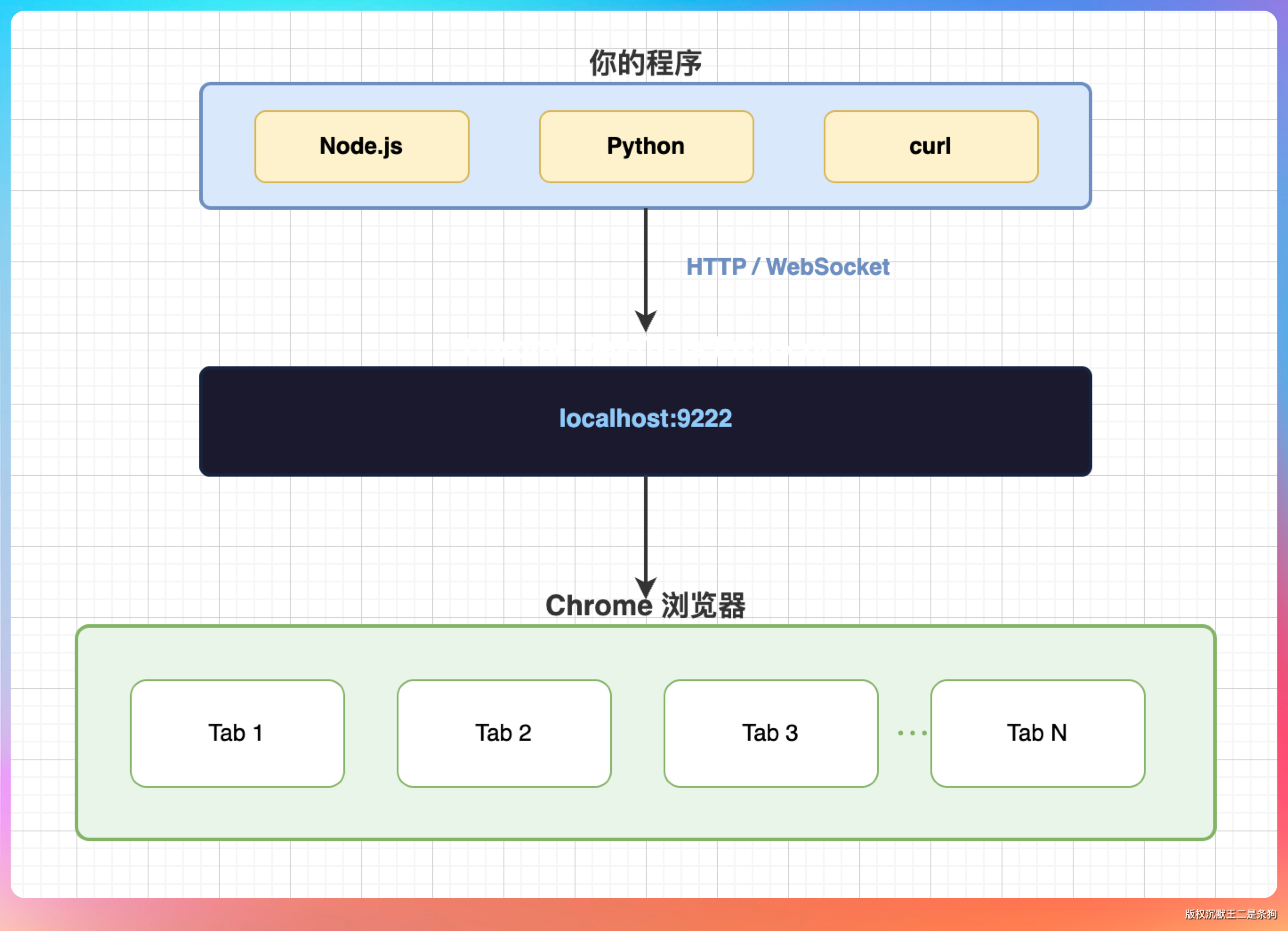
怎么启用 CDP?
启动 Chrome 时带上调试端口参数就行:
/Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome --remote-debugging-port=9222
# Windows
"C:\Program Files\Google\Chrome\Application\chrome.exe" --remote-debugging-port=9222
# Linux
google-chrome --remote-debugging-port=9222
启动后访问 http://localhost:9222/json,能看到所有打开的标签页信息,就说明 CDP 已经在监听了。
CDP Proxy 是什么?
CDP 的原始协议是 WebSocket,调用起来有一定门槛。CDP Proxy 在它外面包了一层 HTTP API,让操作更直观:
不用 Proxy(底层):
代码 ←WebSocket协议→ Chrome:9222
用 Proxy(简化后):
代码 ←HTTP请求→ CDP Proxy ←WebSocket→ Chrome:9222
有了 Proxy,操作浏览器就变成普通的 HTTP 调用:
# 列出当前所有标签页
curl http://localhost:3456/targets
# 在指定标签页执行 JS
curl "http://localhost:3456/eval?target=xxx" -d 'document.title'
# 点击页面某个元素
curl "http://localhost:3456/click?target=xxx" -d 'button.submit'
# 截图保存当前视口
curl "http://localhost:3456/screenshot?target=xxx"
CDP Proxy vs MCP chrome-devtools vs Puppeteer
这三种方案都能操控浏览器,但有本质差异:
| 特性 | CDP Proxy | MCP chrome-devtools | Puppeteer |
|---|---|---|---|
| 浏览器 | 复用日常 Chrome | 独立新实例 | 独立新实例 |
| 登录态 | ✅ 天然携带 | ❌ 需重新登录 | ❌ 需重新登录 |
| 实例冲突 | ❌ 无 | ⚠️ 可能冲突 | ❌ 无 |
| 调用方式 | HTTP API | MCP 工具 | Node.js API |
| 适用场景 | 日常抓取、复用登录 | 隔离环境 | 自动化测试 |
对 Agent 联网这个场景来说,CDP Proxy 最合适,核心原因只有一个:登录态天然携带。
你在 Chrome 里登录了小红书、微信公众号、公司内网,Agent 通过 CDP Proxy 操作这个浏览器,直接就能访问这些页面,不需要另外处理登录、cookie、token 的问题。
这个优势在处理有授权墙的内容时,是其他方案替代不了的。
CDP 的工作流程
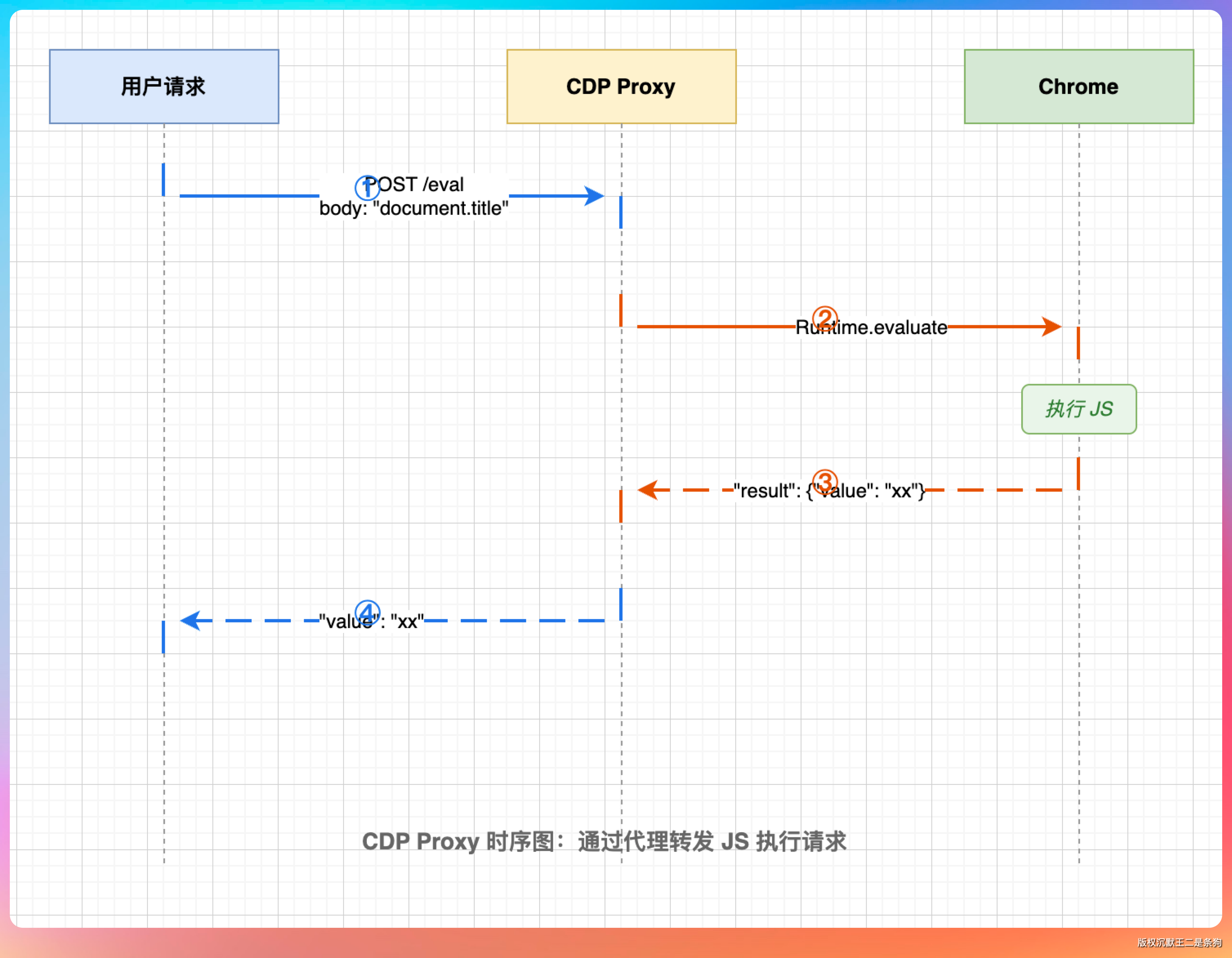
理解了这个流程,就能理解 web-access 为什么能做到“像真人一样浏览网页”。它不是在 HTTP 层面模拟请求,而是在真实浏览器里执行真实操作,看到的内容和你自己打开浏览器看到的完全一样。
ending
用了一段时间之后,我对“Agent 联网”这件事有了一个新的定义。
之前我认为联网就是搜索加抓取:调用搜索引擎 API,拿到摘要,塞进上下文,输出答案。这套流程看起来完整,但遇到动态页面、登录墙、反爬机制,立刻就玩不转了。
web-access 提供的是另一条路:让 Agent 直接操控浏览器,像真实用户一样打开页面、等待渲染、翻找内容、点击链接。碰到搜索解决不了的问题,就换浏览器;碰到浏览器操作复杂的任务,就并行拆分;碰到同一个网站,就复用上次积累的经验。
这不只是多了一个工具,是换了一种思路。
2.8K Star 开源不久就拿到,不是运气好,是踩在了真实痛点上。
如果你用 Claude Code 或者 Codex,试一下。用过之前你觉得联网能力“够用”,用过之后你会意识到之前那叫将就。竞品调研、社媒监控、文档生成、表单提交,这些事 Agent 都能干,而且干得不比人差。
【工具的上限,决定了你能做事情的边界。】
我们下期见。


回复