



大家好,我是二哥呀。
这几天,大家应该都在忙着走亲访友,我昨天也是一口气串了6家亲戚,到家都已经晚上11点半了(离的都不远,在一个县城)。
主打一个串亲戚也要卷。😄
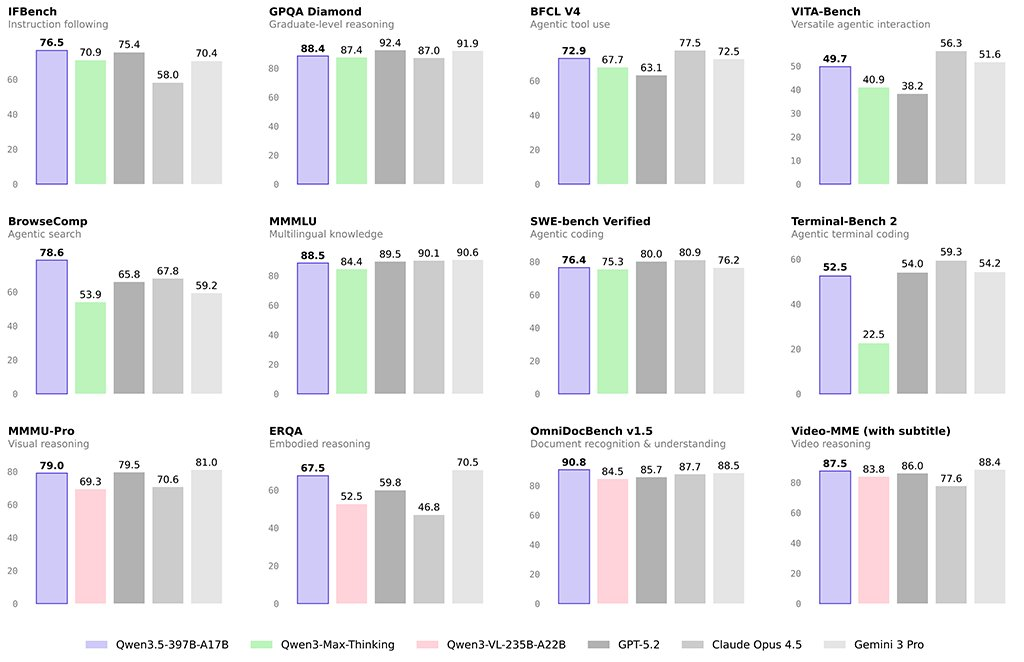
说到卷,各大AI厂商在春节假期也是狠狠卷了一把。比如千问就在除夕夜发布了千问 Qwen3.5,整体表现又大幅提升。

我今天也是抽出来时间测了一遍,得出的结论是:大厂是真的能卷,同时,国产大模型确实也在进步。
这篇测评,我会用三个春节主题的Case,带大家感受下 Qwen3.5-Plus 的真正能力。读完你就知道,为什么我敢说真香了。
先上个知识点:Qwen 系列相对其他模型有一个非常稀缺的标签——全尺寸开源。
真正自己部署过模型的小伙伴都知道,这个标签很难得。很多开源的模型,放出的都是参数量阉割过的版本,真正能打的都藏在闭源版本里。
千问不一样,从 0.5B 到 397B,全尺寸开源。
怎么证明它强?
一个很直观的看点就是 HuggingFace 的下载量。
这比什么注册个账号就能点赞的数据靠谱得多。
技术层面,千问团队也不是闷头干活的那种。
他们自研的门控技术(Gating 机制)相关成果,拿下了 2025 年 NeurIPS Best Paper。

NeurIPS 的含金量,不用多解释——这是全球 AI 顶级会议里的顶级奖项。能拿 Best Paper,说明千问团队在模型架构上的创新,已经得到了学术界的认可。
这个 Gating 机制的核心价值是:让模型在推理时更聪明地选择用哪些参数,而不是一股脑全上。
结果就是:推理成本下降 60%。
成本下降 60% 是什么概念?
假设一家公司部署一个模型,A100 机器 + 机房 + 电力 + 运维,一年成本在 150万 ~ 180万。
现在推理成本下降 60%,一年直接省下 90万 ~ 108万。
这个数字,对大厂来说可能不算什么。但对创业公司、中小企业来说,可能就是活下来和活不下来的区别。
另外,这里纠正一个容易混淆的点:Qwen3.5-Plus 是阿里巴巴的闭源版本,我们可以在通义千问官网直接体验;而 qwen3.5-397b-a17b 是开源版本,可以在 HuggingFace 下载部署。
两个模型能力接近,但定位不同。
闭源版适合直接用,开源版适合自己部署、二次开发。
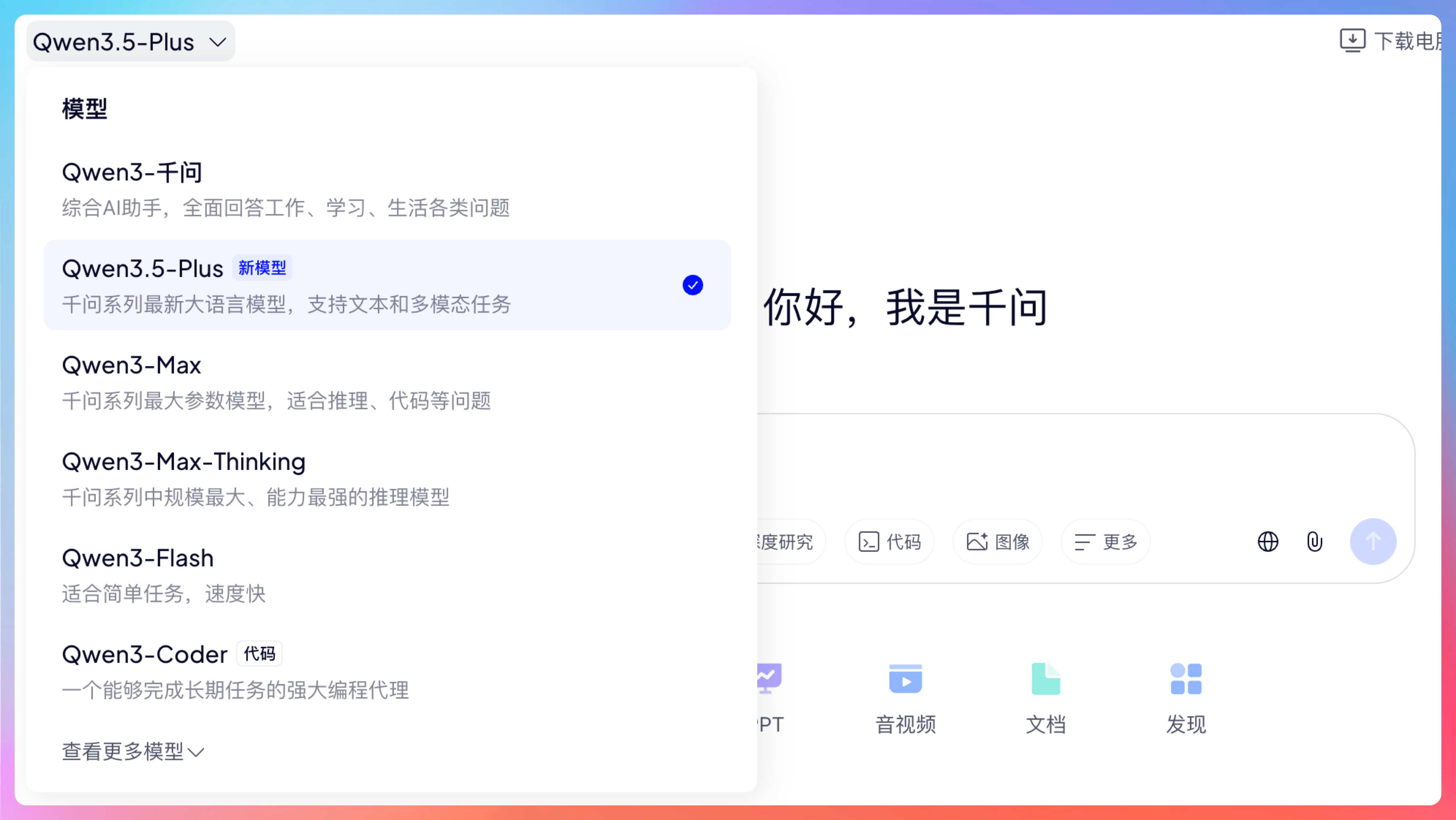
今天我们测评的是 Qwen3.5-Plus,也就是通义千问官网的版本。
好,背景介绍完了,直接上实战。
第一个 Case,我让 Qwen3.5-Plus 帮我生成一个派简历网站——一个可以在线生成简历、上传PDF检测不足的工具。
Prompt 如下:
帮我生成一个派简历网站,要求:
- 可以填写基本信息、教育背景、专业技能、项目经历
- 支持上传PDF简历,自动解析内容
- 分析简历内容,检测出有哪些不足,给出优化建议
- 界面简洁专业,适合求职场景
- 移动端适配
这个需求,既考验前端开发能力,也考验AI的理解和规划能力。
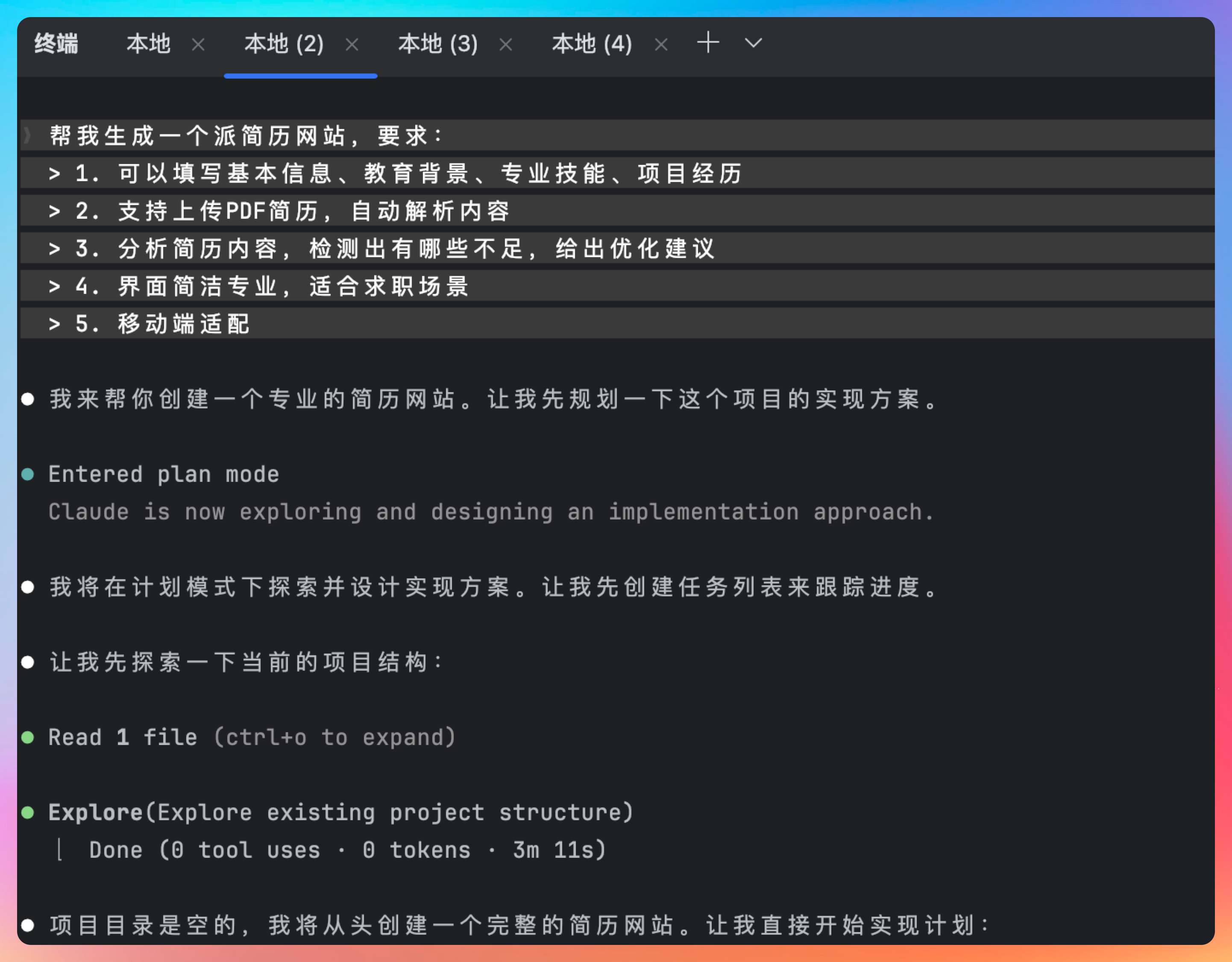
注意,我是直接在Claude Code中接入Qwen3.5-Plus来完成的。
这比在官网直接访问,代码的质量更高,完成度也更高。底层模型的切换工具我仍然用的PaiSwitch,我自己Vibe Coding的一款工具。
代码已开源在GitHub:https://github.com/itwanger/PaiSwitch。
Qwen3.5-Plus 给出的方案,让我挺惊喜的。
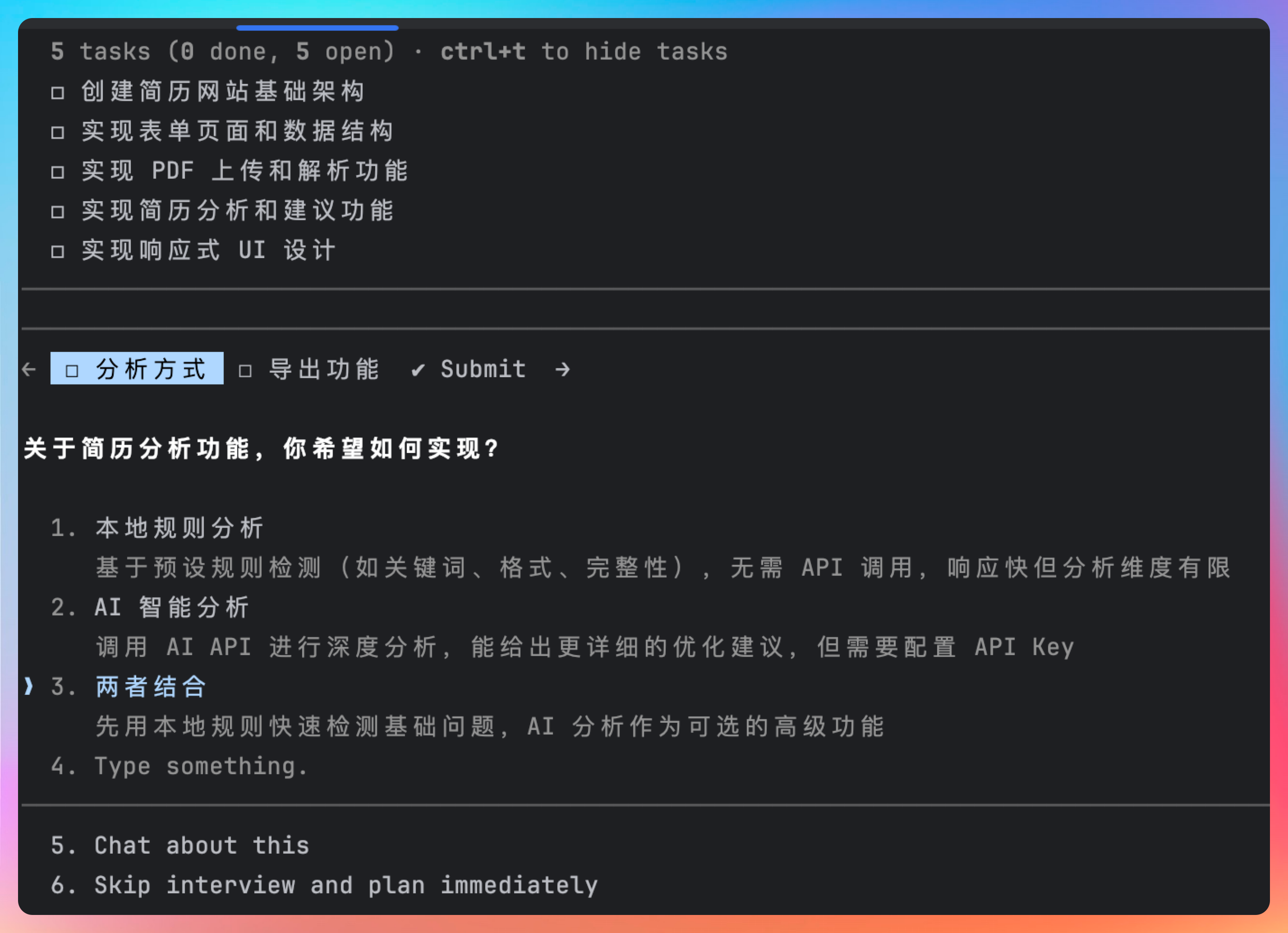
它没有一上来就写代码,而是先启用plan模式调研需求。比如说简历分析功能是基于本地规则还是AI智能分析?需不需要简历导出功能,是导出PDF还是markdown?
代码的结构是这样的:
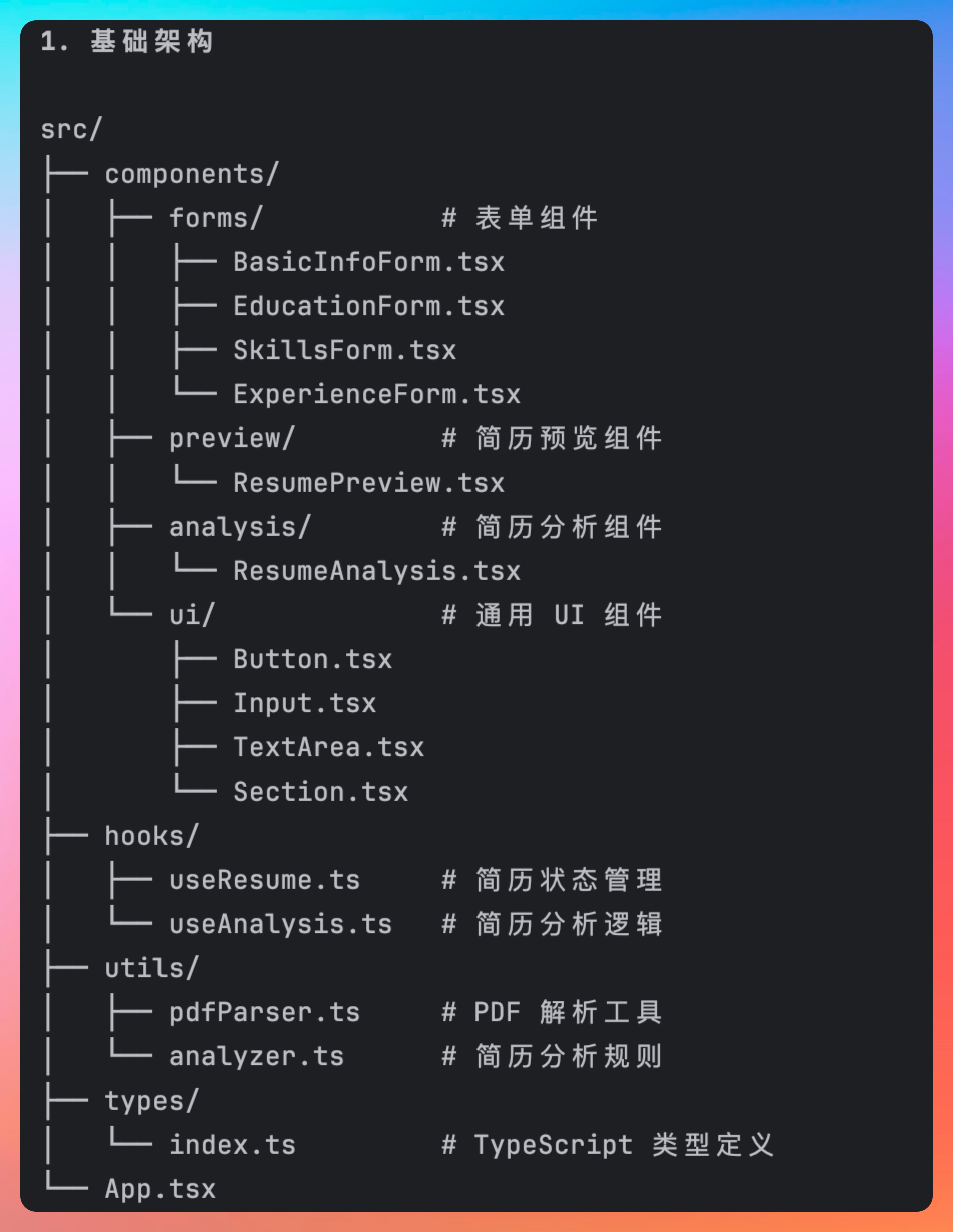
每一个功能的分析都是很完善的,比如说PDF解析会使用pdfjs读取,然后用正则表达式+NLP提取关键信息等。

确认没问题,我们就让Qwen3.5-Plus开始编码工作。
技术选型目前是纯前端实现,我认为没问题,第一版我们暂时也不需要后端交互。梳理一下我们想要Qwen3.5-Plus实现的核心功能:
- 表单联动预览:填写的内容实时渲染到右侧简历模板,改一处、看一处
- PDF上传解析:利用 FileReader API 读取文件,配合 PDF.js 提取文本内容
- AI诊断分析:把解析出的内容发送给大模型,让它从HR视角给出优化建议
等会看看它编码工作完成后,是否能够满足我们的预期。目前已经工作了7分钟了,消耗了18.2k token,还剩下两个任务没有完成。
吃口西瓜再耐心等待会。
不得不感慨,Claude Code这个名字确实没起好,它不仅仅是个coding的终端窗口,更是一个高智商的Agent,配上任何大模型的 LLM 就能工作,install、build、纠错、重新build,只要授权到位。
这些原本需要多个编码工程师才能完成的工作,Claude Code都搞定了。
虽然最终的编码工作还没有结束,但浏览器端已经可以看到雏形了。
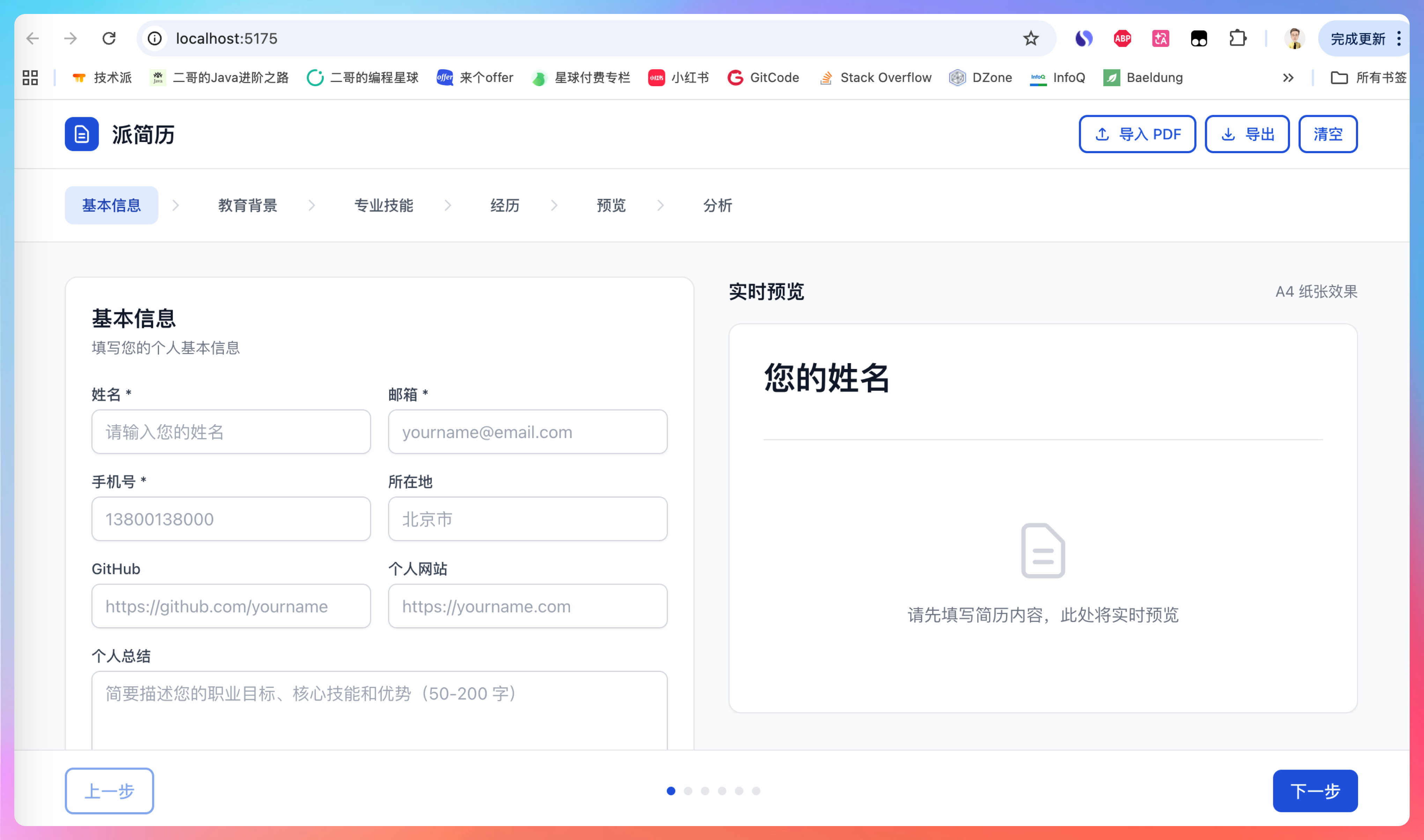
风格我认为真的很不错。蓝灰色调,很简洁,历时 21 分钟,来看看完成度。
①、填写简历 - 在左侧表单中填写基本信息、教育背景、技能和经历
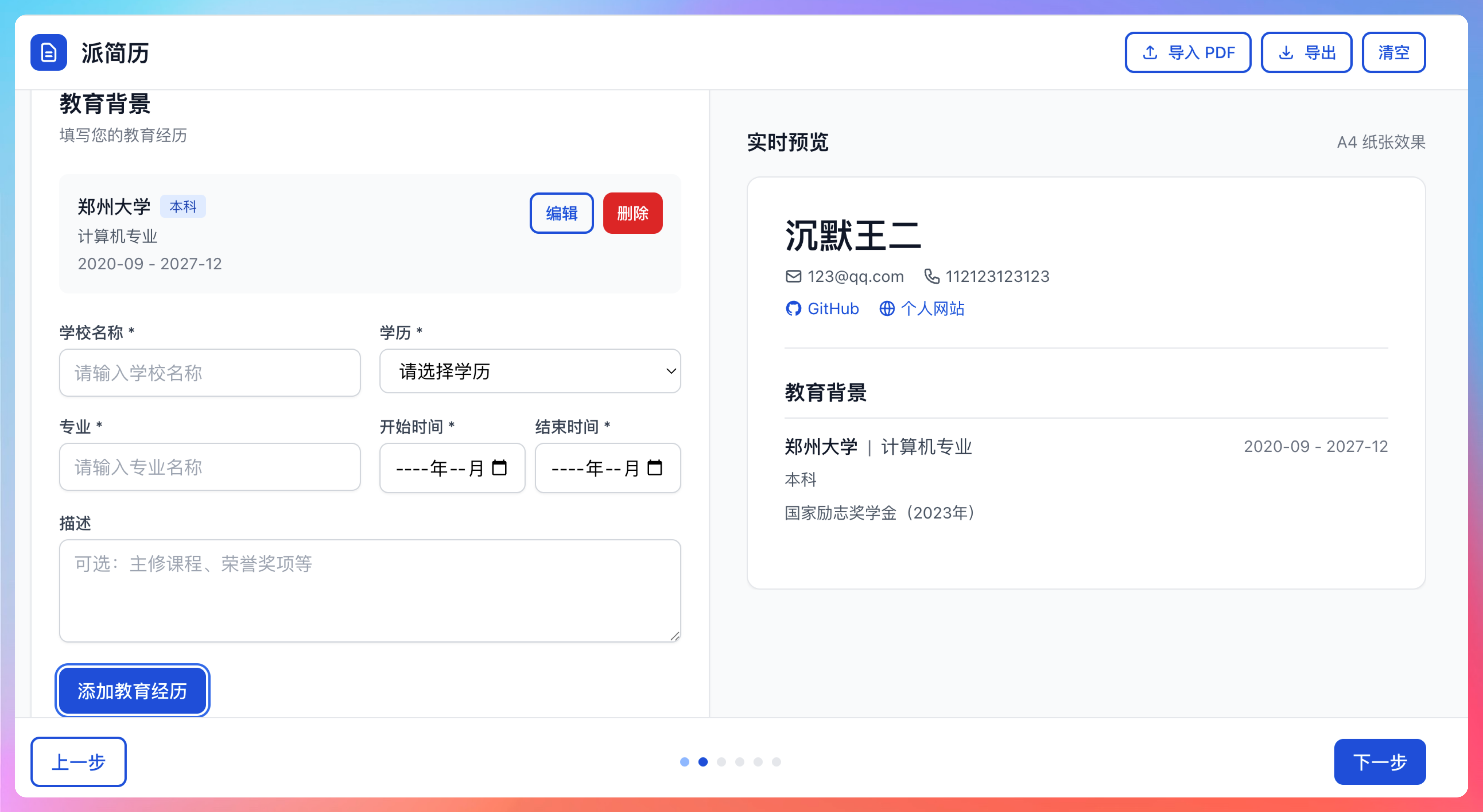
基本信息、教育背景的排版都是我认为OK的类型。
项目经历/实习经历/工作经历的填写我认为也是非常丝滑的,非常贴心的是,描述这里还有 star 法则。
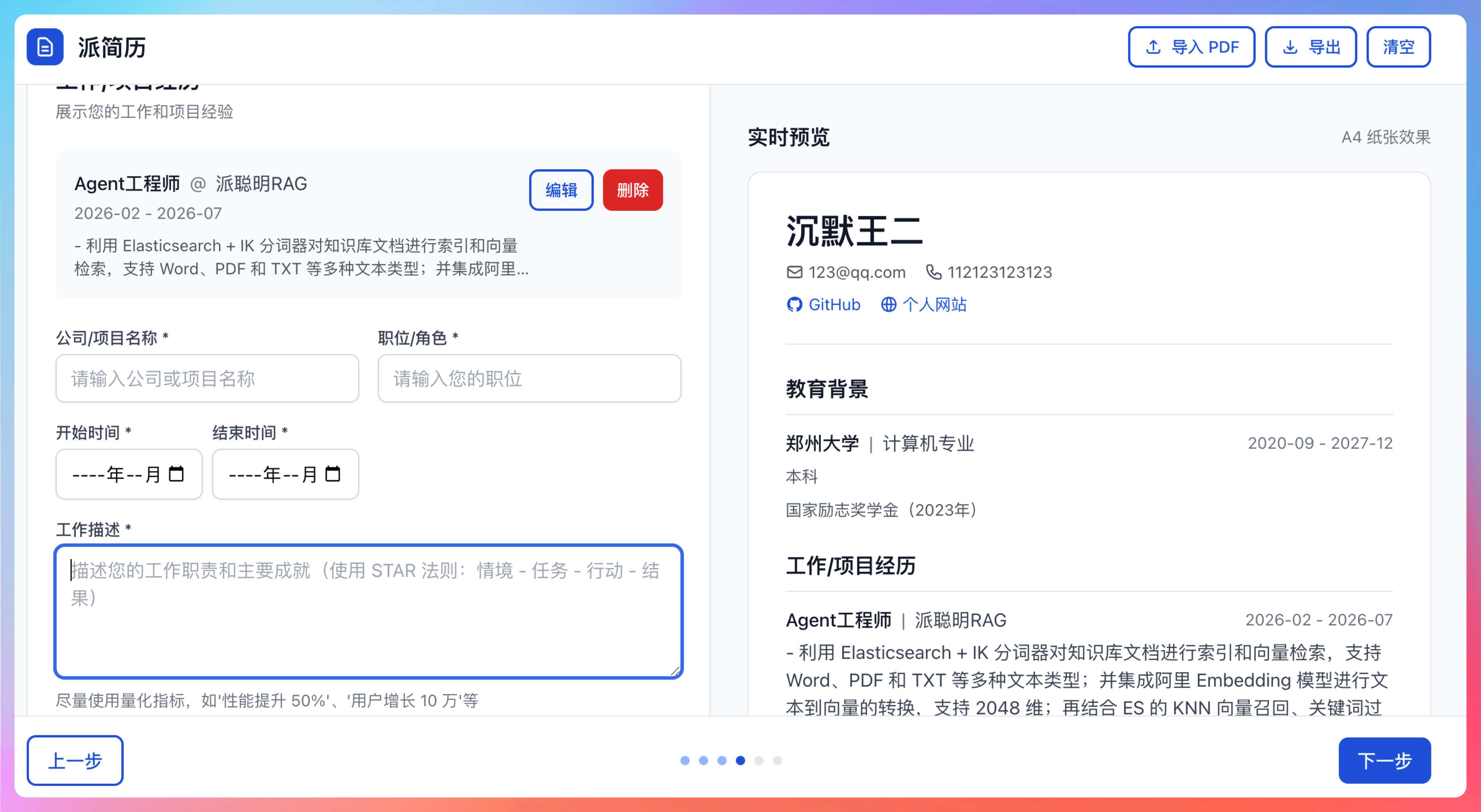
②、查看预览 - 右侧实时显示简历预览效果
③、导入 PDF - 点击顶部导入 PDF按钮上传现有简历自动解析
④、分析简历 - 导航到分析步骤,获取智能改进建议

来看看给出的诊断结果:
- 手机号码格式不正确
- 个人总结过于简单
- 缺少专业技能
- 项目经历还有改进空间。
这个诊断,和我在星球里给小伙伴们改简历的思路几乎一样。
接下来是AI智能分析。这里需要提前在 .env 中配置API Key。
然后就可以把简历的情况发送给 LLM 进行诊断了。注意这里的提示词,会把简历的填写情况抽取出来作为提示词。
你是一位专业的简历顾问。请分析简历并提供专业建议。必须严格按照 JSON 格式输出。\n\n请分析以下简历,提供专业、具体的改进建议。\n\n## 简历内容\n\n### 基本信息\n姓名:(未填写)\n邮箱:(未填写)\n手机:(未填写)\n所在地:(未填写)\nGitHub: (未填写)\n网站:(未填写)\n个人总结:(未填写)\n\n### 教育背景\n(未填写)\n\n### 专业技能\n(未填写)\n\n### 工作/项目经历\n(未填写)\n\n## 分析要求\n\n请从以下维度分析这份简历
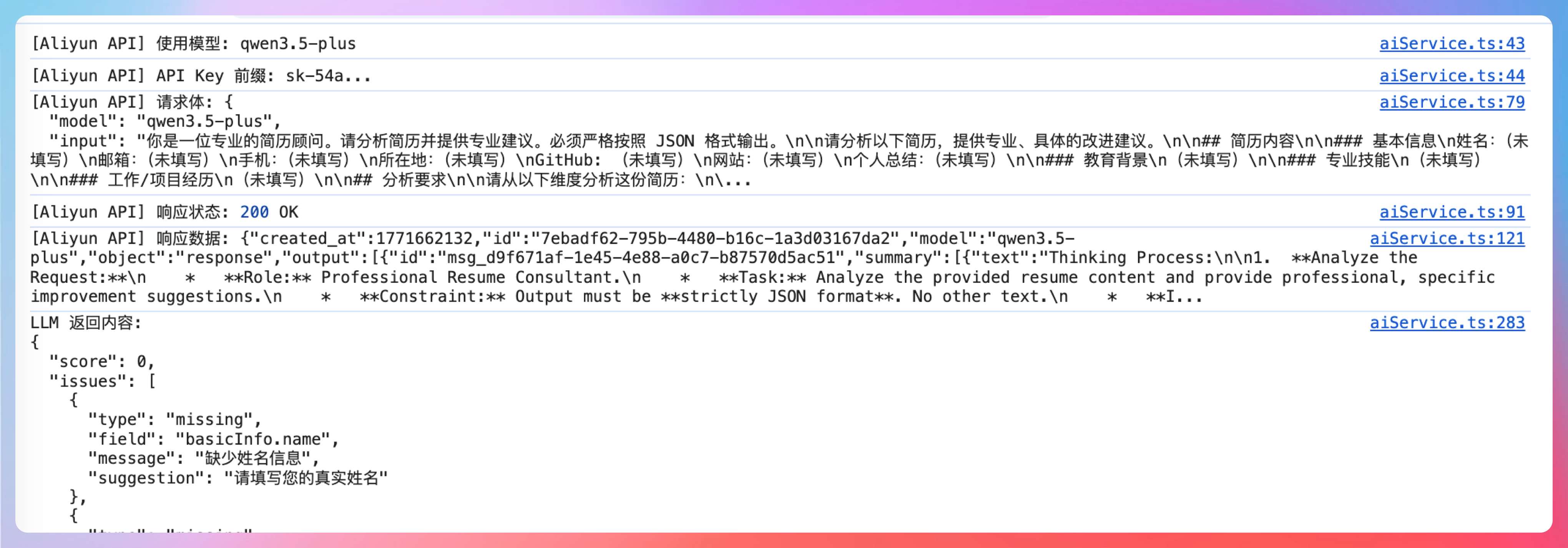
针对一份完全空白的简历,建议如下:
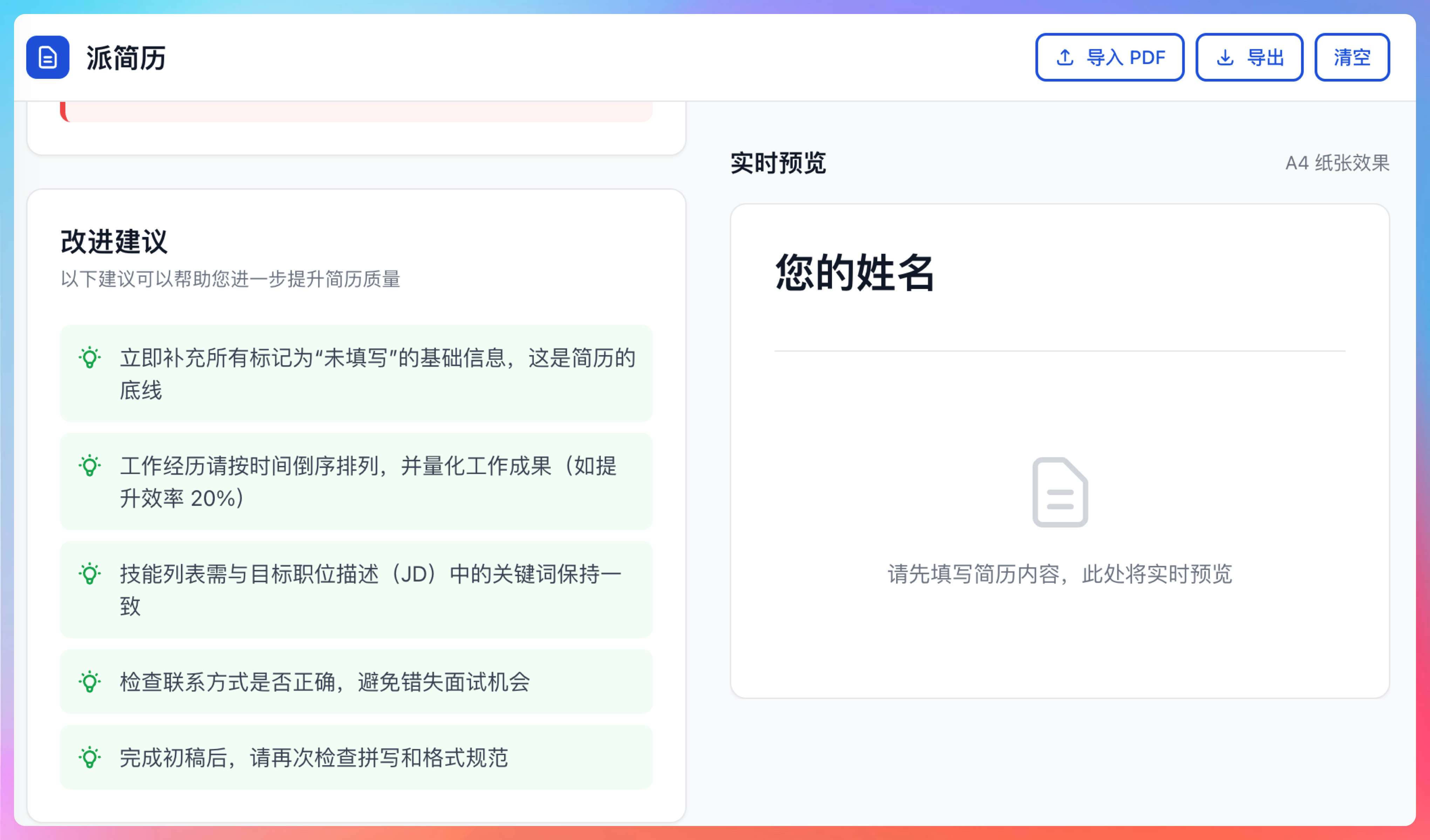
半个小时能开发出来这样一个可用的网站,我认为Qwen3.5-Plus已经很强了,后续配上后端,基本上就是一个完全可以开源出来的完整作品了。
成品率很高。
⑤、导出简历 - 点击导出按钮打印或保存为 PDF
这个 Case 测试下来,我对 Qwen3.5-Plus 的能力有了新的认知。
它不只是会写代码,而是真的理解简历这个场景,知道求职者需要什么、HR看重什么。
表单设计合理、交互流畅、诊断专业——这些能力的背后,是它对真实业务场景的理解。
接下来这个 Case 我们来换个角度——测测常识推理。
测试 Prompt:
我想去洗车,洗车店距离我家1米。你说我应该开车过去还是走过去?
这道题,看起来简单,但暗藏玄机。
1米,是个什么概念?正常成年人走 1 米,大概 1 秒。开车的话,上车、启动、开过去、停车,可能比走路还慢。
更关键的是:洗车店就在家门口,开车去洗车,是不是有点……多余?
Qwen3.5-Plus 的回答,让我有点意外:

它不只是回答走还是开,而是把整个场景都考虑进去了:或者,这可能不是洗车店,而是你家的车库? 如果是这样,那你已经在洗车店里面了,不用动。
这道题测的不是知识,是常识。
AI 要答对,得理解洗车这个场景的真实流程,还得有基本的生活经验。
Qwen3.5-Plus 的表现,说明它不只是背数据,而是真的在"理解"问题。
除了上面测的这些,Qwen3.5-Plus 还有一些值得一提的能力:
- 支持上传文件、图像、视频、音频各种附件
- 支持深入研究、网页开发等技能
- 在代码补全、Bug 修复、项目重构等场景表现优秀
如果你是开发者,可以试试把它接进自己的工作流。如果你是普通用户,直接去通义千问官网体验就行。
测完 Qwen3.5-Plus,我最大的感受是:国产大模型,真的不一样了。
不是那种还能用的不一样,是可以打的不一样。
如果你在找一个能写代码、能推理、还能理解生活场景的 AI 助手,Qwen3.5-Plus 值得一试。
开源版本更是香,自己部署、二次开发,想怎么玩怎么玩。
【AI 做苦力,我们做创造。这才是 AI 时代的正确打开方式。】
国产大模型走到今天,靠的不是嘴上说说,是一代代模型的迭代,一个个真实场景的打磨。
千问团队用实际行动证明了一件事:中国开发者,也能做出世界级的开源模型。
日子还长,路还远。
但只要方向对了,就不怕走得慢。
如果这篇测评对你有用,记得点赞,转发给需要的人。
我们下期见!


回复