



大家好,我是二哥呀。
对比阿里、腾讯这些互联网大厂来说,小米的薪酬确实性价比高,应届生能开到 18k 就算是比较高的水平了。
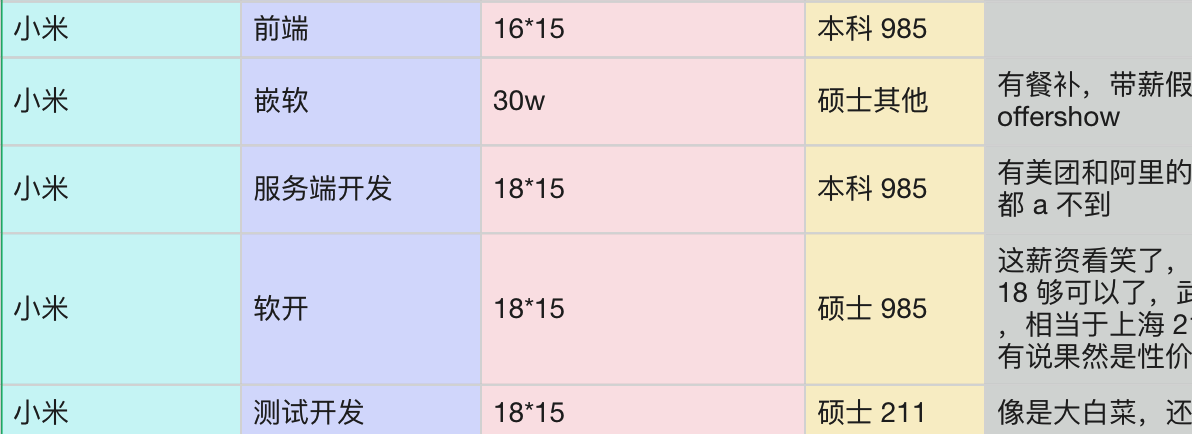
但现实就是,能去互联网大厂的同学基本上都是头部或者肩部选手,对于腰部和裆部选手来说,能拿到 18k 的 base 就很心满意足了。
并且如果把这个数目拉到社会平均水平,也能站在前 5%。
在某脉上看到一位小米员工的爆料说:
入职小米5年多,岗位后端开发,职级16,薪酬3.8万*15,总包57万,在米真不低了,知足。
我觉得这种心态就非常好,比较是偷走幸福的小偷,只要薪资是满足自己预期的,很可以了。
况且说真心话,小米这些年的发展有目共睹。就像雷军在昨天的演讲中提到的,同时供两个孩子上大学,芯片和汽车,不容易。
我必须诚恳地说,该冲小米还是要冲,尤其是武汉和南京的同学。小米目前在招软开岗位还是非常多的,争取赶在长假前上岸是最好的节奏,这样假期就可以放肆的摆烂。

再坚持坚持,算上今天,假期前还有 3 个工作日,真的有机会。
就像雷军在演讲里提到的,改变是一种信念,每一个正在经历改变的人,都会迎来属于自己的精彩。

接下来,我们来复盘一下《Java面试指南》专栏中收录的同学 Q 小米一面面经,希望下次碰到原题的同学都能口若悬河,吊打面试官😄
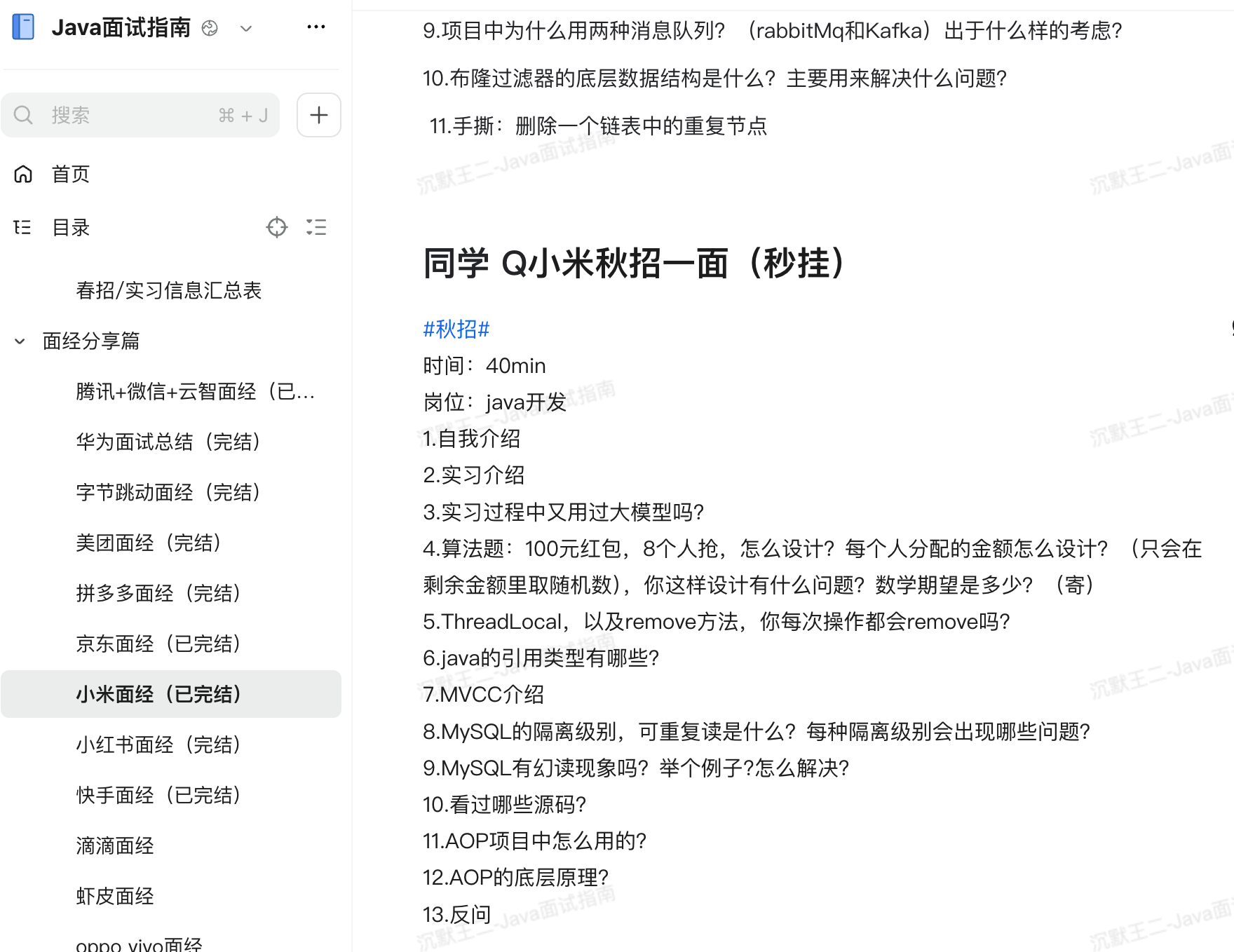
重点复盘容易错,没有思路的题目,重复性的问题大家可以直接通过面渣逆袭在线版查看。

同学 Q 小米秋招一面面经
自我介绍
我是来自武理工的小王,拿到过 xx 年度的国家励志奖学金,拿到过 xxx 年度的竞赛第二名;刚好之前在参加过小米训练营,主要负责 xxxx,有哪些量化数据巴拉巴拉。
项目目前做一个基于 RAG 架构的企业级私有知识库派聪明,其核心意义在于解决现代企业知识管理的痛点,推动组织智能化转型。

当用户通过聊天界面进行对话时,系统会将用户输入的内容进行语义转化,通过 ES 的混合检索召回 TOPK 个相关信息,最后再将最近的上下文一起封装到 prompt,再发送给 LLM,从而实现检索增强生成,也就是利用 RAG 的技术架构来减少模型的输出幻觉。
另外一个项目xxxx。
我个人是小米的忠实用户,手机从小米 6 用到小米 14,如果能够有幸加入小米这个大家庭,我会奖励自己一部小米 17。
实习介绍
我 xxx 公司实习的时候,是一套基于 SpringCloud & SpringCloud Alibaba & LLM 的分布式微服务的智能项目管理系统。
我在项目中主要负责消息通知方案的抽离,将其放到了公共组件 pmhub-base-notice 中,支持发送消息到企业微信等第三方平台。
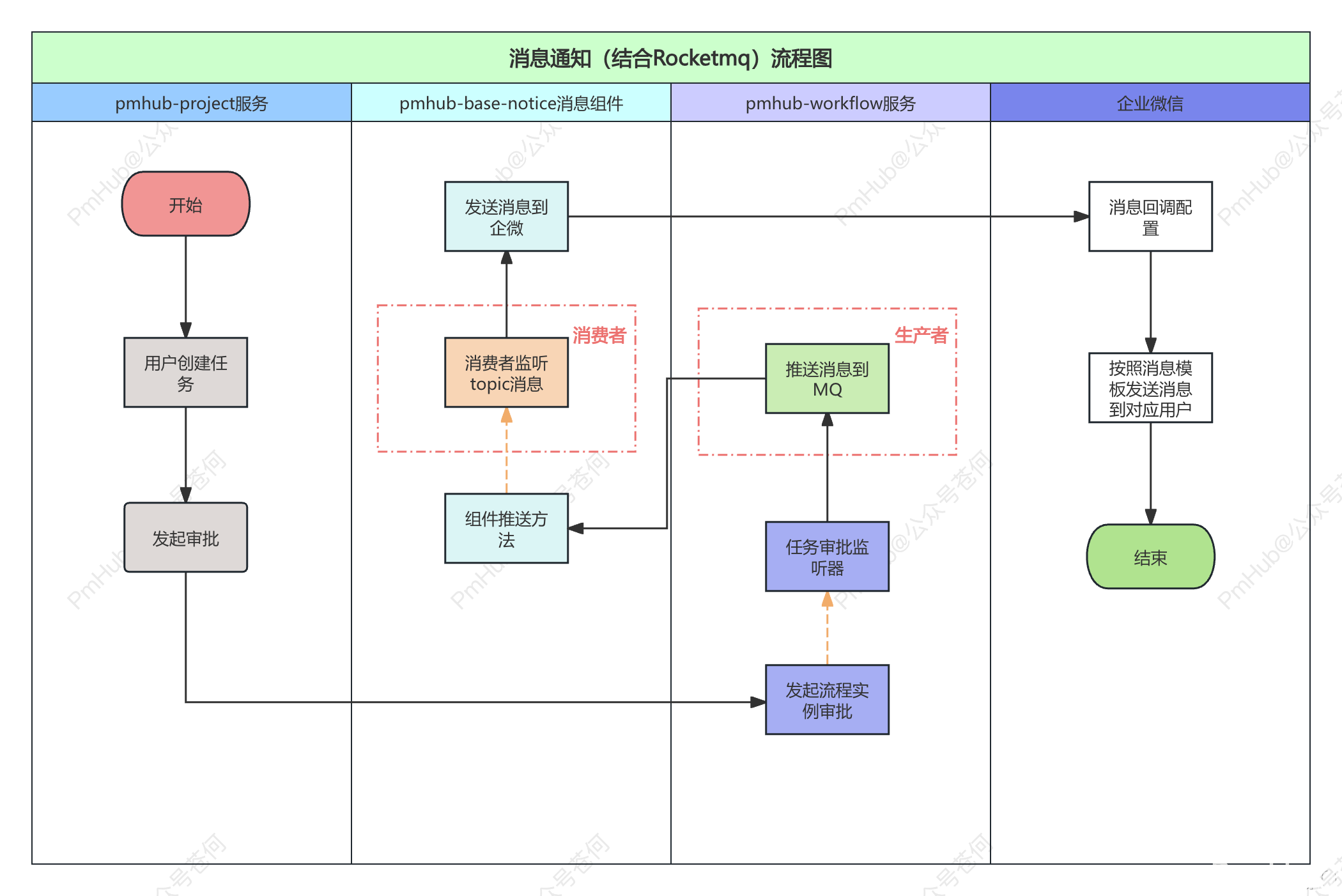
任何服务只需要添加 pmhub-base-notice 即可拥有消息收发能力。
实习过程中有用过大模型吗?
我在实习期间确实有接触和使用大模型,遇到一些重复性的编码时,我会使用 Claude Code,可以切换到国内的智谱、千问、DeepSeek,效果投挺不错。
平常遇到不熟悉的技术概念或者报错信息时,我也会去问多个大模型,我觉得目前效果不错的是 Google 的 Gemini,然后再去官方文档或者技术社区深入了解。这样比直接 Google 搜索要更快一些,特别是对于一些比较新的技术栈。
团队内部也有一些关于大模型使用的讨论和规范。比如涉及敏感业务数据的代码不能直接粘贴给公开的大模型,需要做脱敏处理。还有就是生成的代码必须经过充分的测试和 review 才能上线。
算法题:100元红包,8个人抢,怎么设计?每个人分配的金额怎么设计?
把 100 元想象成一条长度为 100 的线段,随机生成 7 个切割点(8 个人需要 7 个切割点),然后按照切割出的长度来分配金额。
具体实现步骤:
- 生成 7 个随机切割点,范围在
[0, 100]之间 - 对这 7 个切割点进行排序
- 计算相邻切割点之间的距离,就是每个人分到的金额
- 处理边界情况,保证每个人至少分到 0.01 元
- 每个人获得红包的期望都是 100/8 = 12.5元,没有先后顺序的影响
代码参考:
public List<Double> distributeRedPacket(double totalAmount, int peopleCount) {
List<Double> result = new ArrayList<>();
List<Double> cutPoints = new ArrayList<>();
Random random = new Random();
// 添加起始点和结束点
cutPoints.add(0.0);
cutPoints.add(totalAmount);
// 生成随机切割点
for (int i = 0; i < peopleCount - 1; i++) {
cutPoints.add(random.nextDouble() * totalAmount);
}
// 排序切割点
Collections.sort(cutPoints);
// 计算每个人分到的金额
for (int i = 1; i < cutPoints.size(); i++) {
double amount = cutPoints.get(i) - cutPoints.get(i - 1);
// 保证最少0.01元,四舍五入保留两位小数
amount = Math.max(0.01, Math.round(amount * 100) / 100.0);
result.add(amount);
}
return result;
}
ThreadLocal,以及remove方法
ThreadLocal 是一种用于实现线程局部变量的工具类。它允许每个线程都拥有自己的独立副本,从而实现线程隔离。
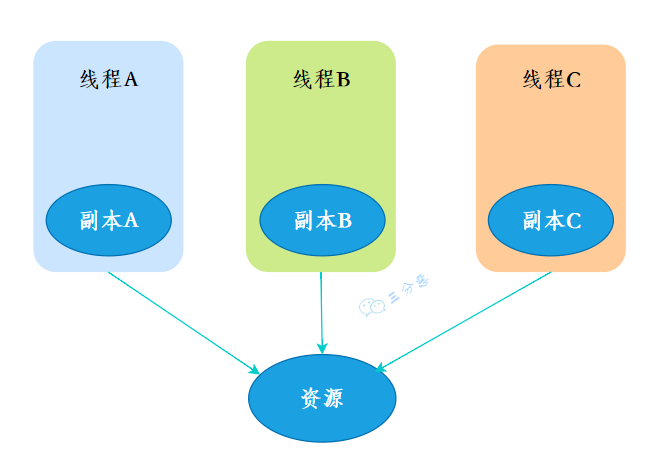
remove() 会调用 ThreadLocalMap 的 remove 方法遍历哈希表,找到 key 等于当前 ThreadLocal 的 Entry,找到后会调用 Entry 的 clear 方法,将 Entry 的 value 设置为 null。
你每次操作都会remove吗?
我不是每次操作都 remove,主要是根据使用场景来决定的。在一些短生命周期的场景中,比如处理单个 HTTP 请求的上下文信息,我通常会在请求结束时统一 remove。
public class ReqInfoContext {
private static TransmittableThreadLocal<ReqInfo> contexts = new TransmittableThreadLocal<>();
public static void addReqInfo(ReqInfo reqInfo) {
contexts.set(reqInfo);
}
public static void clear() {
contexts.remove(); // 清除ThreadLocal中的数据
}
public static ReqInfo getReqInfo() {
return contexts.get();
}
}
但在一些需要跨多个方法调用保持状态的场景中,就不会每次都 remove。
我的使用原则是:
- 在方法级别使用时,try-finally 保证 remove
- 在请求级别使用时,通过拦截器或 Filter 统一清理
- 如果存储的对象比较大,使用完立即 remove
- 定期检查 ThreadLocal 的使用情况,避免遗漏
java的引用类型有哪些?
引用数据类型有:
MySQL的隔离级别,可重复读是什么?每种隔离级别会出现哪些问题?
隔离级别定义了一个事务可能受其他事务影响的程度,MySQL 支持四种隔离级别,分别是:读未提交、读已提交、可重复读和串行化。
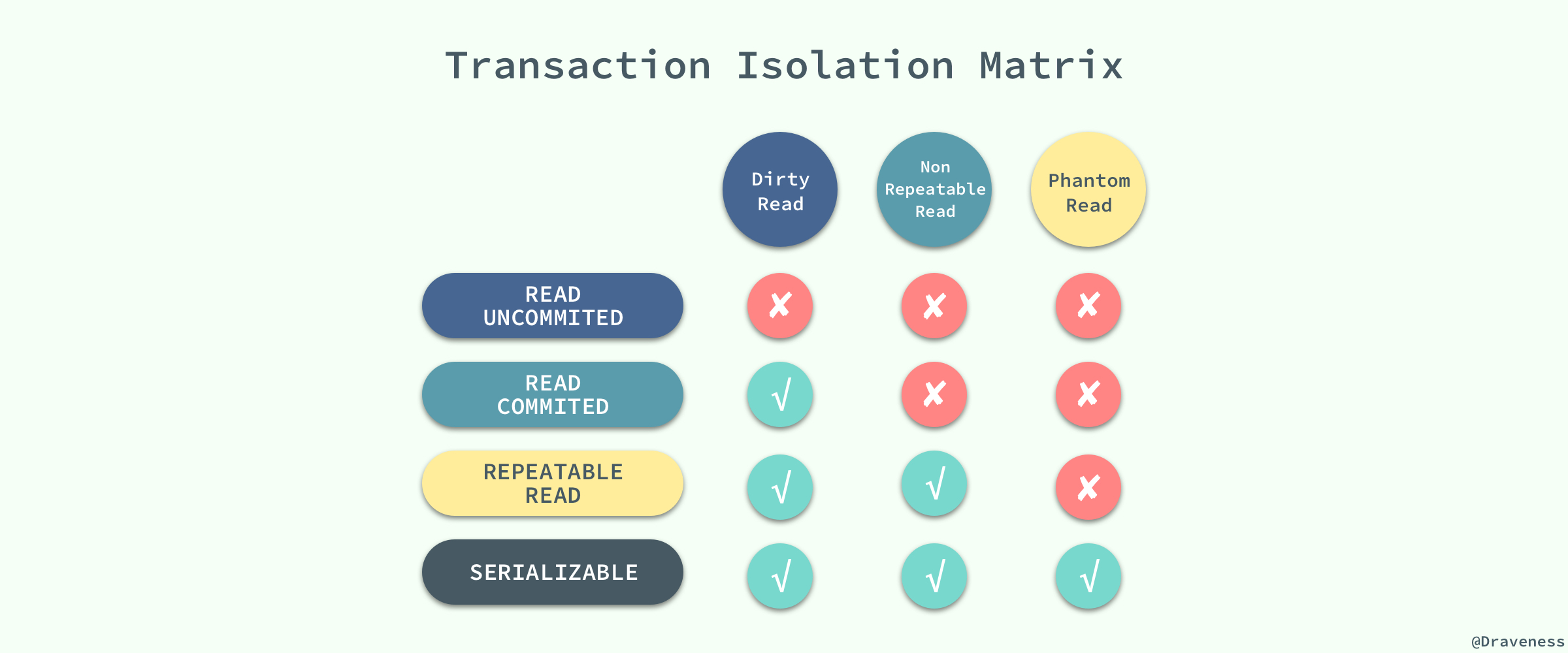
可重复读能确保同一事务内多次读取相同数据的结果一致,即使其他事务已提交修改。

读未提交会出现脏读,读已提交会出现不可重复读,可重复读是 InnoDB 默认的隔离级别,可以避免脏读和不可重复读,但会出现幻读。不过通过 MVCC 和临键锁,能够防止大多数并发问题。
串行化最安全,但性能较差,通常不推荐使用。
MySQL有幻读现象吗?举个例子?
幻读是指在同一个事务中,多次执行相同的范围查询,结果却不同。这种现象通常发生在其他事务在两次查询之间插入或删除了符合当前查询条件的数据。
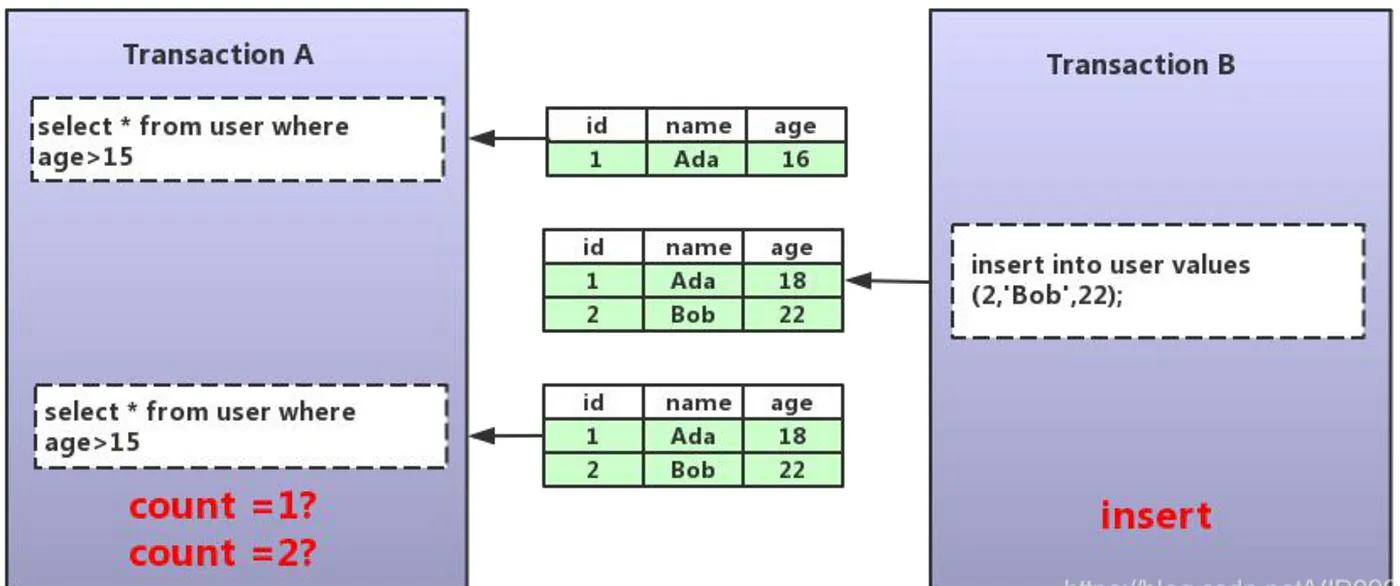
比如说事务 A 在第一次查询某个条件范围的数据行后,事务 B 插入了一条新数据且符合条件范围,事务 A 再次查询时,发现多了一条数据。
我们来验证一下,先创建测试表,插入测试数据。
CREATE TABLE `user_info` (
`id` BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键id',
`name` VARCHAR(32) NOT NULL DEFAULT '' COMMENT '姓名',
`gender` VARCHAR(32) NOT NULL DEFAULT '' COMMENT '性别',
`email` VARCHAR(32) NOT NULL DEFAULT '' COMMENT '邮箱',
PRIMARY KEY (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8mb4 COMMENT='用户信息表';
-- 插入测试数据
INSERT INTO `user_info` (`id`, `name`, `gender`, `email`) VALUES
(1, 'Curry', '男', 'curry@163.com'),
(2, 'Wade', '男', 'wade@163.com'),
(3, 'James', '男', 'james@163.com');
COMMIT;
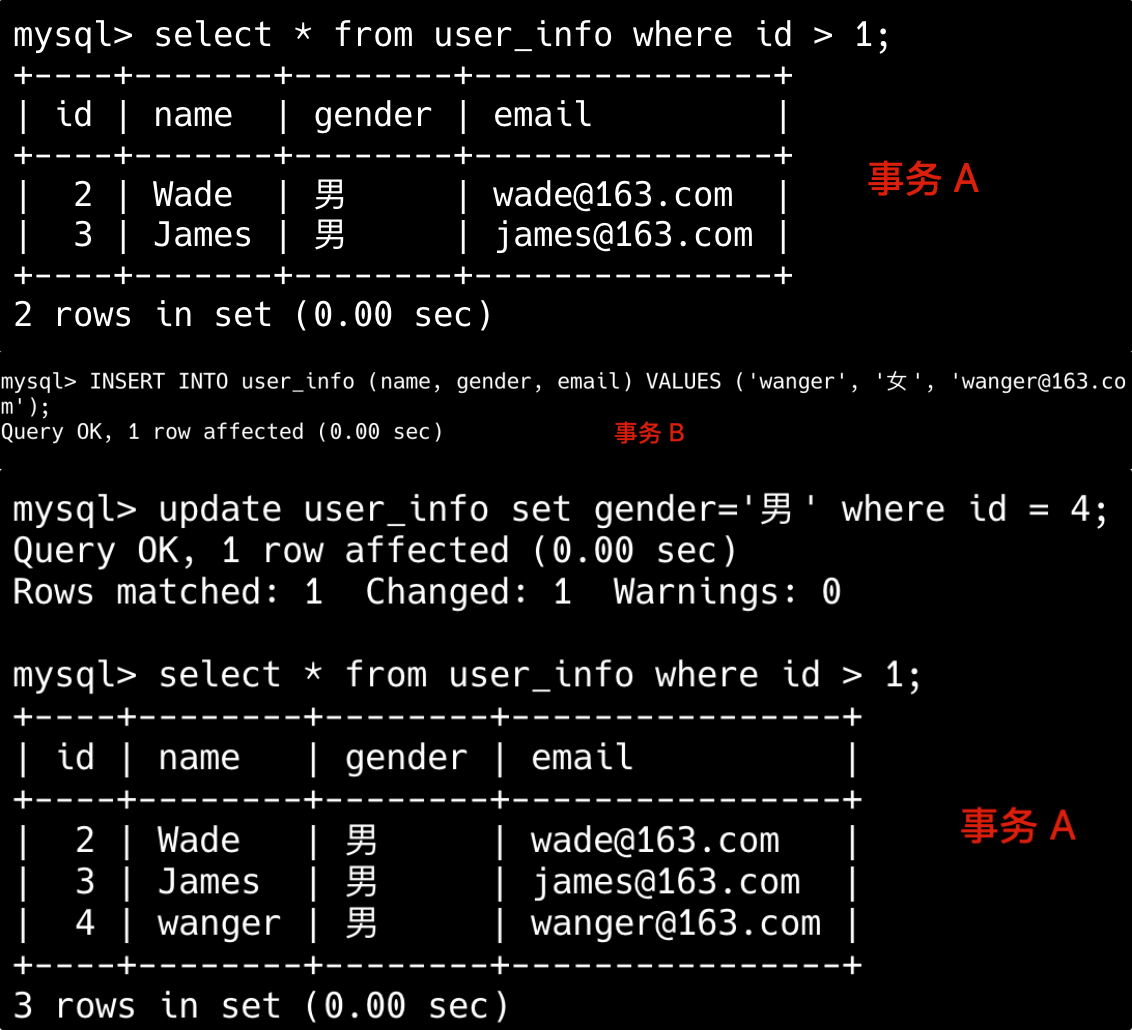
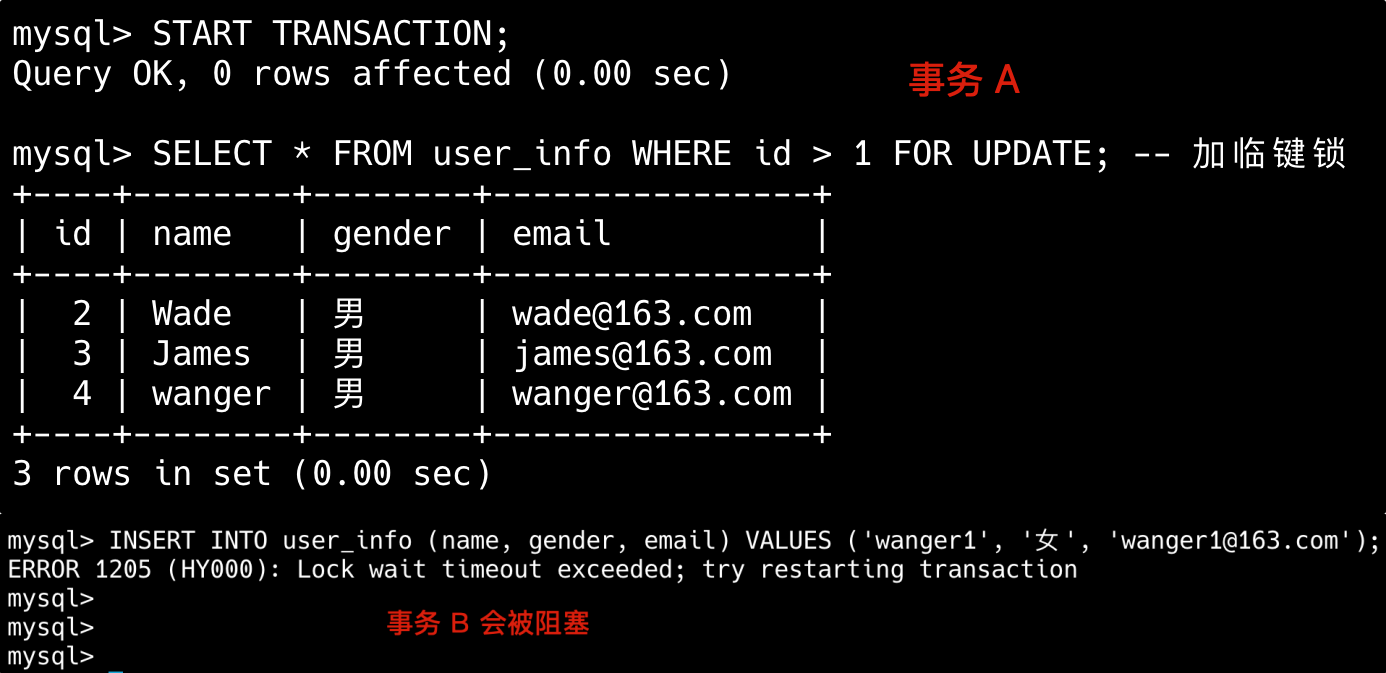
然后我们在事务 A 中执行查询 SELECT * FROM user_info WHERE id > 1;,在事务 B 中插入数据 INSERT INTO user_info (name, gender, email) VALUES ('wanger', '女', 'wanger@163.com');,再在事务 A 中修改刚刚插入的数据 update user_info set gender='男' where id = 4;,最后在事务 A 中再次查询 SELECT * FROM user_info WHERE id > 1;。
如何避免幻读?
MySQL 在可重复读隔离级别下,通过 MVCC 和临键锁可以在一定程度上避免幻读。
比如说在查询时显示加锁,利用临键锁锁定查询范围,防止其他事务插入新的数据。
START TRANSACTION;
SELECT * FROM user_info WHERE id > 1 FOR UPDATE; -- 加临键锁
COMMIT;
其他事务在插入数据时,会被阻塞,直到当前事务提交或回滚。
使用 SELECT 查询时,如果没有显式加锁,InnoDB 会使用 MVCC 提供一致性视图。
每个事务在启动时都会生成一个 Read View,用来确定哪些数据对当前事务可见。
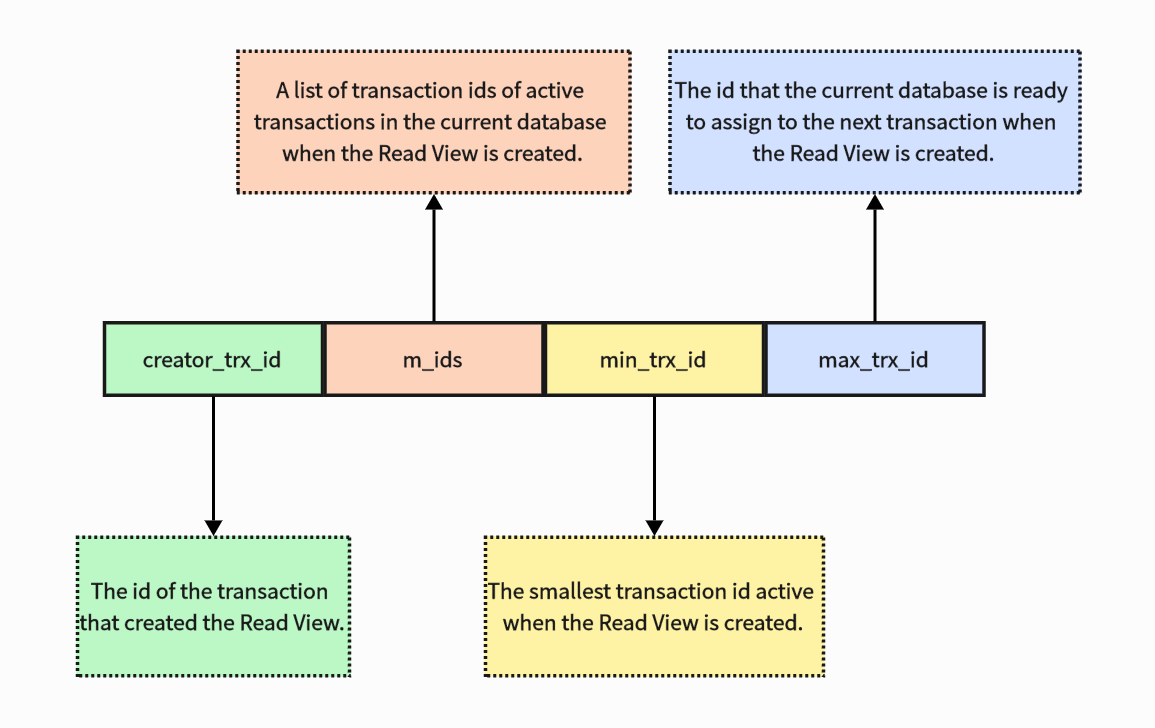
其他事务在当前事务启动后插入的新数据不会被当前事务看到,因此不会出现幻读。
看过哪些源码?
看过一些 Spring 的源码,主要是带着问题去看的,比如遇到一些技术难点或者想深入理解某个功能的时候。
我重点看过的是 IoC 容器的初始化过程,特别是 ApplicationContext 的启动流程。从 refresh() 方法开始,包括 Bean 的定义和加载、Bean 工厂的准备、Bean 的实例化和初始化这些关键步骤。
看源码的时候发现 Spring 用了很多设计模式,比如工厂模式、单例模式、模板方法模式等等,这对我平时写代码也很有启发。
还有就是 Spring 的 Bean 生命周期,从 BeanDefinition 的创建到 Bean 的实例化、属性注入、初始化回调,再到最后的销毁,整个过程还是挺复杂的。看了源码之后对 @PostConstruct、@PreDestroy 这些注解的执行时机就更清楚了。
不过说实话,Spring 的源码确实比较难啃,涉及的概念和技术点太多了。我一般是结合一些技术博客和 Claude 一起看,这样理解起来会相对容易一些。
AOP项目中怎么用的?
答:AOP 在实际工作/编码学习中有很多应用场景,我按照使用频率来说说几个主要的。
事务管理是用得最多的场景,基本上每个项目都会用到。只需要在 Service 方法上加个 @Transactional 注解,Spring 就会自动帮我们管理事务的开启、提交和回滚。
日志记录也是一个很常见的应用。在技术派实战项目中,就利用了 AOP 来打印接口的入参和出参日志、执行时间,方便后期 bug 溯源和性能调优。
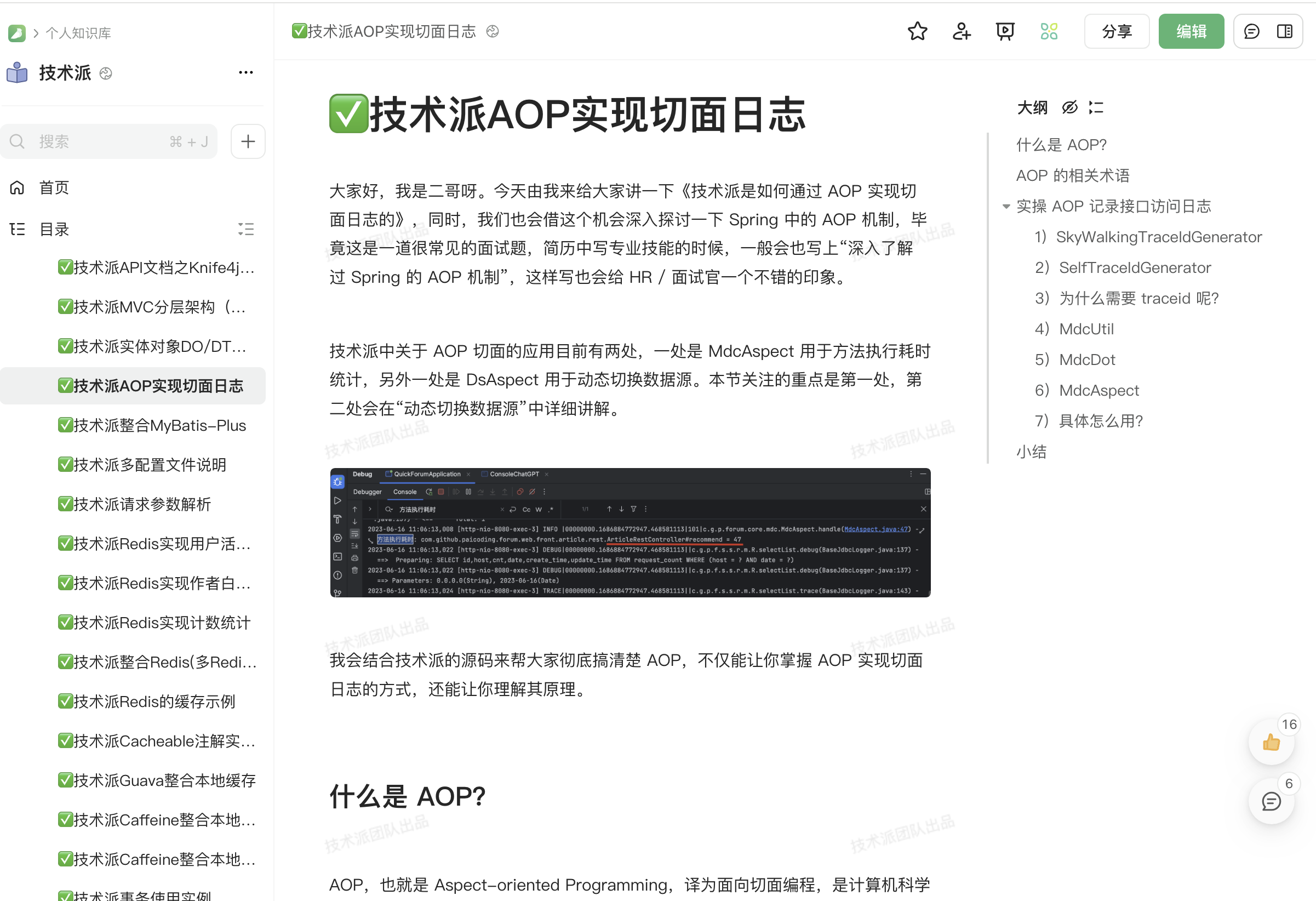
AOP的底层原理?
从技术实现上来说,AOP 主要是通过动态代理来实现的。如果目标类实现了接口,就用 JDK 动态代理;如果没有实现接口,就用 CGLIB 来创建子类代理。代理对象会在方法执行前后插入我们定义的切面逻辑。
ending
一个人可以走得很快,但一群人才能走得更远。二哥的编程星球已经有 9800 多名球友加入了,如果你也需要一个良好的学习环境,戳链接 🔗 加入我们吧。这是一个 简历精修 + 编程项目实战+ Java 面试指南的私密圈子,你可以阅读星球专栏、向二哥提问、帮你制定学习计划、和球友一起打卡成长。
两个置顶帖「球友必看」和「知识图谱」里已经沉淀了非常多优质的学习资源,相信能帮助你走的更快、更稳、更远。
欢迎点击左下角阅读原文了解二哥的编程星球,这可能是你学习求职路上最有含金量的一次点击。

最后,把二哥的座右铭送给大家:没有什么使我停留——除了目的,纵然岸旁有玫瑰、有绿荫、有宁静的港湾,我是不系之舟。共勉 💪。




回复