



大家好,我是二哥呀。
给大家贴个喜报,都来沾沾好运🍀buff 吧,没准假期前就能顺利拿下一个 offer,假期就可以放肆地摆,坐等节后开奖。
上面这个球友在 9 月 24 号这一天,在星球里发帖说靠派聪明 RAG拿到了京东的 offer,部门还非常不错。按照京东这两年的开奖节奏,base 还挺值得期待。
我贴一下 Java 面试指南专栏中收录的 25 届秋招薪资大家参考一下。
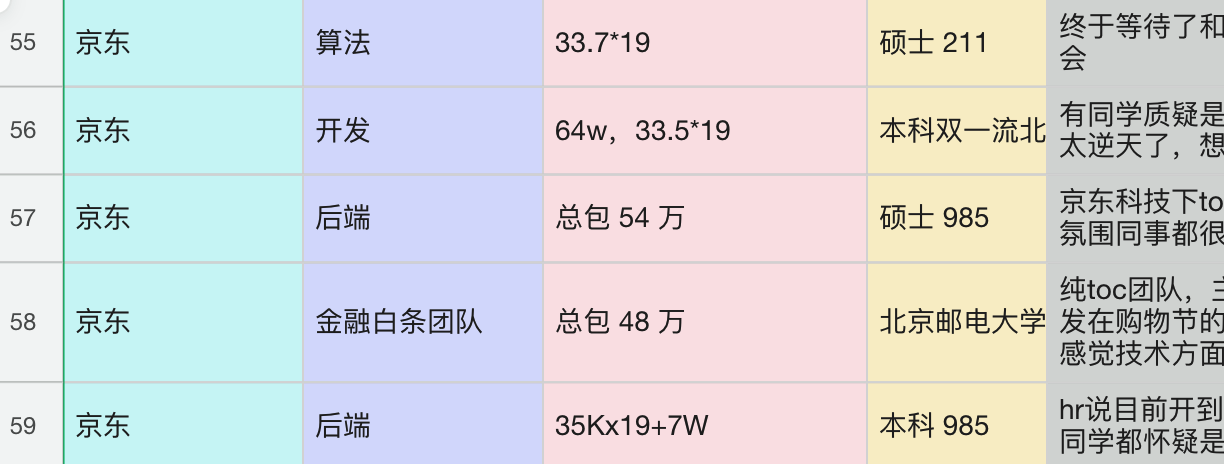
香还是挺香的。
假期前还有两个工作日,猛猛冲一波吧,没准咱就是那个幸运儿呢!
今天我们就以另外一个球友的京东 JDS 一面为例,来复盘一下京东的面试强度,下次再碰到原题,必过!

同学 19 京东 JDS 一面面经
自我介绍
我是来自家里蹲大学的小王,拿到过 xx 年度的国家励志奖学金,拿到过 xxx 年度的竞赛第二名;刚好之前在拼多多实习过,主要负责 xxxx,有哪些量化数据巴拉巴拉。
项目目前做一个基于 RAG 架构的企业级私有知识库派聪明,其核心意义在于解决现代企业知识管理的痛点,推动组织智能化转型。

当用户通过聊天界面进行对话时,系统会将用户输入的内容进行语义转化,通过 ES 的混合检索召回 TOPK 个相关信息,最后再将最近的上下文一起封装到 prompt,再发送给 LLM,从而实现检索增强生成,也就是利用 RAG 的技术架构来减少模型的输出幻觉。
另外一个项目xxxx。
我个人是京东的忠实用户,平常买东西和点外卖也都会用京东 APP,到货是真的快,品质也有保障。
实习期间怎么快速熟悉公司业务?
刚入职的时候,我会主动找团队里的老同事聊天,了解项目的背景和整体架构。大部分同事都挺愿意帮助新人的,关键是要问对问题。
接下来我会重点看需求文档、技术方案、接口文档这些,了解系统的设计思路。如果发现文档有问题或者缺失,我会主动去完善,这样既能加深理解,又能为团队做贡献。
然后从一些相对简单的 bug 修复或者小功能开发开始,这样可以快速熟悉代码结构和开发流程。通过修改代码,能够深入理解系统的各个模块是如何协作的。而且完成小任务也能快速建立成就感和信心。
如果有机会做一些涉及多个系统或模块的任务,我会主动申请。并把学到的业务知识、技术方案、常见问题的解决方法记录下来,形成自己的知识库。
讲讲你某个需求具体的研发方案
我碰到的一个需求是大文件上传。传统的上传方式经常出现这种情况:网络稍微不稳定就上传失败,得重新来。
我用了分片上传的技术,把大文件切成小块,一块一块地上传。这个实现很巧妙,用 Redis 的 BitMap 来记录哪些分片已经上传了。即使中间断网了,也能从断点继续,不用重头开始。而且用 MinIO 做对象存储,可以很好地处理海量文件。
public void uploadChunk(String fileMd5, int chunkIndex, long totalSize, String fileName,
MultipartFile file, String orgTag, boolean isPublic, String userId) throws IOException {
logger.info("[uploadChunk] 开始处理分片上传请求 => fileMd5: {}, chunkIndex: {}, totalSize: {}, fileName: {}",
fileMd5, chunkIndex, totalSize, fileName);
// 检查分片是否已上传
if (isChunkUploaded(fileMd5, chunkIndex)) {
logger.info("分片已存在,跳过上传 => fileMd5: {}, chunkIndex: {}", fileMd5, chunkIndex);
return;
}
// 上传分片到MinIO
String chunkPath = String.format("%s/chunk_%d", fileMd5, chunkIndex);
minioClient.putObject(PutObjectArgs.builder()
.bucket(bucketName)
.object(chunkPath)
.stream(file.getInputStream(), file.getSize(), -1)
.build());
// 在Redis中标记分片已上传
markChunkUploaded(fileMd5, chunkIndex);
}
实现实习需求的途中,用了哪些java基本特性或者基础知识?
为了解决超大文件解析过程中出现的 OOM 问题,我采用了流式的 IO 处理,尽可能在任何时候都只处理一小段数据,避免全量加载。
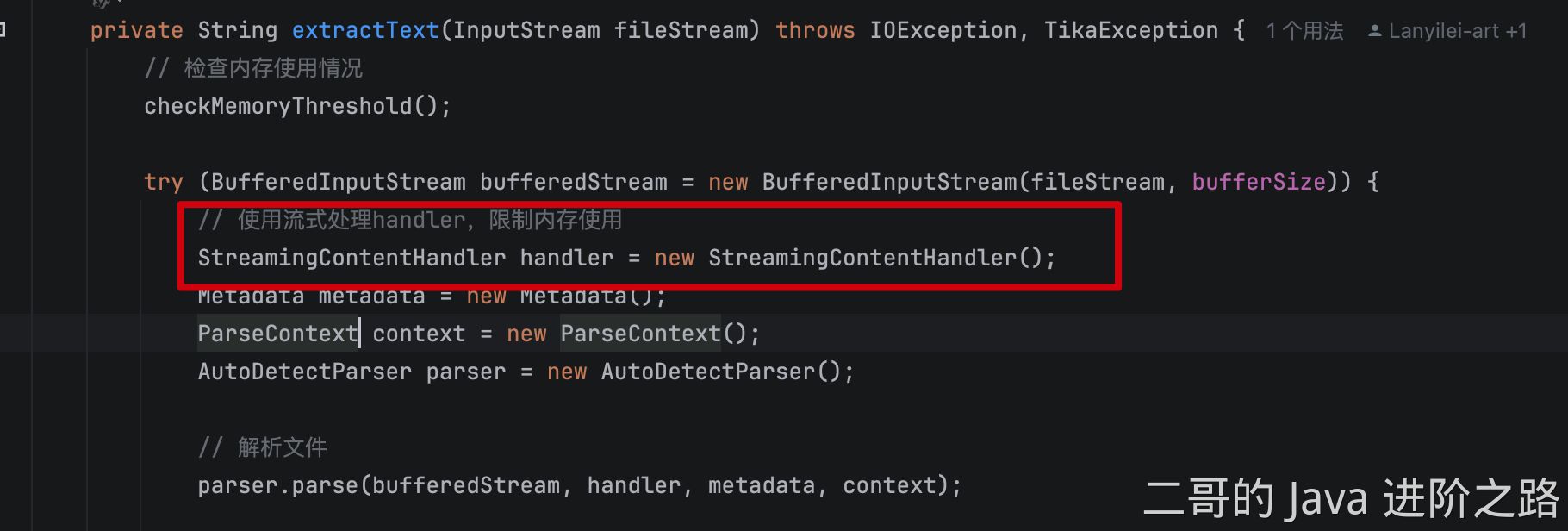
我自定义了一个 StreamingContentHandler,它在每次处理字符的回调函数中,会判断当前内容是否达到了分块阈值,如果是就马上进行切片、入库。这样整个过程就不再需要等待解析完成之后一次性处理,而是边读边处理。
HashMap 链表转红黑树阈值
树化发生在 table 数组的长度大于 64,且链表的长度大于 8 的时候。
为什么是 8 呢?
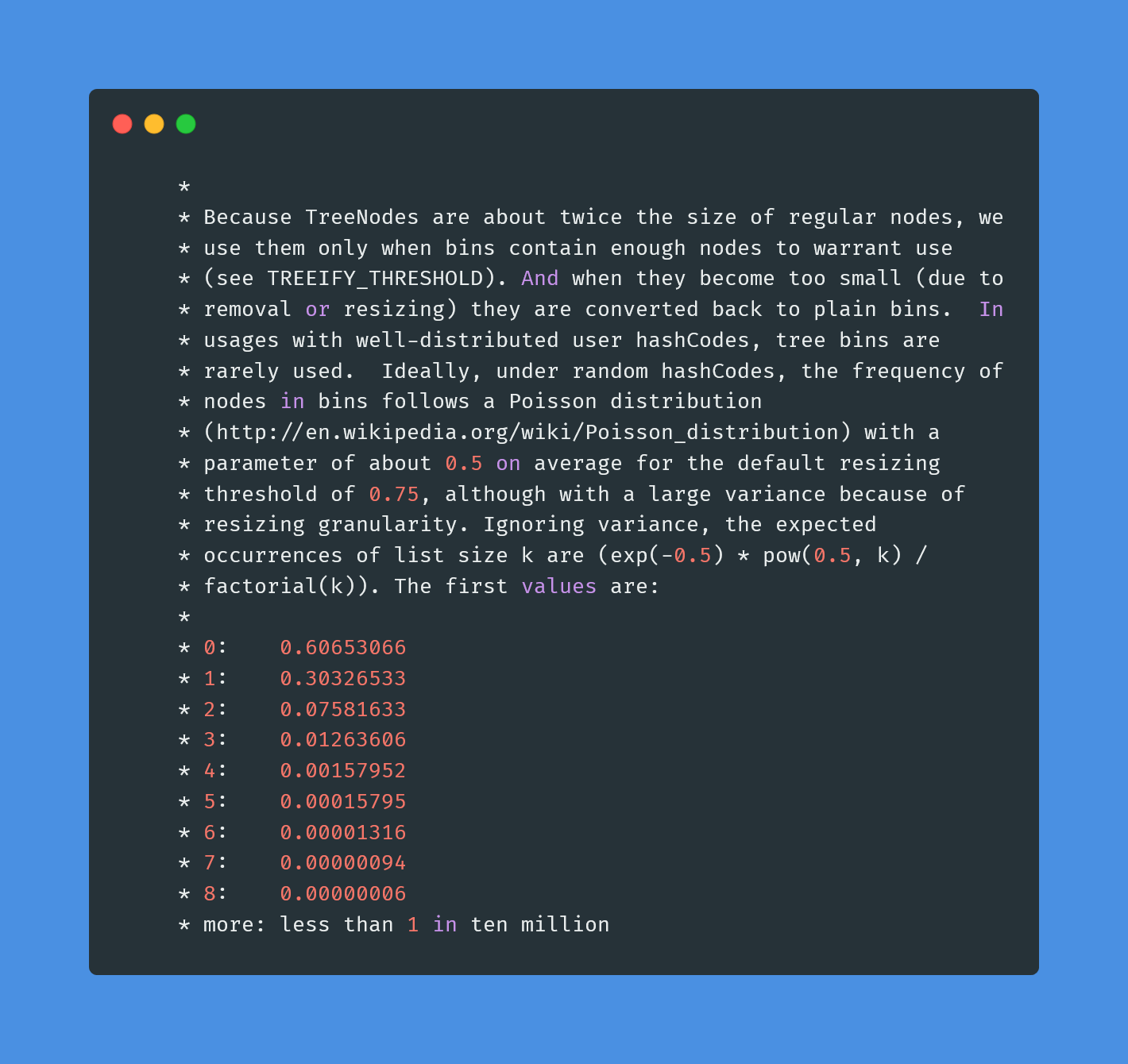
和统计学有关。理想情况下,使用随机哈希码,链表里的节点符合泊松分布,出现节点个数的概率是递减的,节点个数为 8 的情况,发生概率仅为 0.00000006。
也就是说,在正常情况下,链表长度达到 8 是个小概率事件。
8 是一个平衡点。当链表长度小于 8 时,即使是 O(n) 的查找,由于 n 比较小,实际性能还是可以接受的,而且链表的内存开销小。当链表长度达到 8 时,查找性能已经比较差了,这时候转换为红黑树的收益就比较明显了,因为红黑树的查找、插入、删除操作的时间复杂度都是 O(log n)。
负载因子干什么用的
负载因子(load factor)是一个介于 0 和 1 之间的数值,用于衡量哈希表的填充程度。它表示哈希表中已存储的元素数量与哈希表容量之间的比例。
- 负载因子过高(接近 1)会导致哈希冲突增加,影响查找、插入和删除操作的效率。
- 负载因子过低(接近 0)会浪费内存,因为哈希表中有大量未使用的空间。
默认的负载因子是 0.75,这个值在时间和空间效率之间提供了一个良好的平衡。
扩容机制具体流程
扩容时,HashMap 会创建一个新的数组,其容量是原来的两倍。然后遍历旧哈希表中的元素,将其重新分配到新的哈希表中。
如果当前桶中只有一个元素,那么直接通过键的哈希值与数组大小取模锁定新的索引位置:e.hash & (newCap - 1)。
如果当前桶是红黑树,那么会调用 split() 方法分裂树节点,以保证树的平衡。
如果当前桶是链表,会通过旧键的哈希值与旧的数组大小取模 (e.hash & oldCap) == 0 来作为判断条件,如果条件为真,元素保留在原索引的位置;否则元素移动到原索引 + 旧数组大小的位置。
了解哪些设计模式?说说它们的应用场景
单例模式、策略模式。
在需要控制资源访问,如配置管理、连接池管理时经常使用单例模式。它确保了全局只有一个实例,并提供了一个全局访问点。
在有多种算法或策略可以切换使用的情况下,我会使用策略模式。像技术派实战项目中,我就使用策略模式对接了讯飞星火、OpenAI、智谱 AI 等多家大模型,实现了一个可以自由切换大模型基座的智能助手服务。
策略模式的好处是,不用在代码中写 if/else 判断,而是将不同的 AI 服务封装成不同的策略类,通过工厂模式创建不同的 AI 服务实例,从而实现 AI 服务的动态切换。
后面想添加新的 AI 服务,只需要增加一个新的策略类,不需要修改原有代码,这样就提高了代码的可扩展性。
模版模式在java中具体怎么实现的?
模板方法通常通过抽象类和继承来实现。抽象类定义了一个模板方法,该方法包含了一系列步骤的调用顺序,而具体的步骤则由子类实现。
abstract class AbstractClass {
// 模板方法,定义算法的骨架
public final void templateMethod() {
stepOne();
stepTwo();
}
protected abstract void stepOne();
protected abstract void stepTwo();
}
class ConcreteClassA extends AbstractClass {
@Override
protected void stepOne() {
System.out.println("ConcreteClassA: Step One");
}
@Override
protected void stepTwo() {
System.out.println("ConcreteClassA: Step Two");
}
}
class ConcreteClassB extends AbstractClass {
@Override
protected void stepOne() {
System.out.println("ConcreteClassB: Step One");
}
@Override
protected void stepTwo() {
System.out.println("ConcreteClassB: Step Two");
}
}
讲讲单例模式的实现逻辑,怎么避免实例被重复加载?
单例模式(Singleton Pattern)是一种创建型设计模式,它确保一个类只有一个实例,并提供一个全局访问点来获取该实例。
实现单例模式的关键点在于:
- 私有构造方法:确保外部代码不能通过构造器创建类的实例。
- 私有静态实例变量:持有类的唯一实例。
- 公有静态方法:提供全局访问点以获取实例,如果实例不存在,则在内部创建。
这样就能避免实例被重复加载。
锁加到类上和方法上有什么区别?
将 synchronized 加到方法上时,锁定的是整个方法,任何线程在调用该方法时都会获得该对象的锁,直到方法执行完毕才释放锁。
将 synchronized 加到代码块上 synchronized (Singleton.class)时,锁定的是类的 Class 对象,所有对这个类的 synchronized 代码块都会串行执行。
synchronized的底层实现
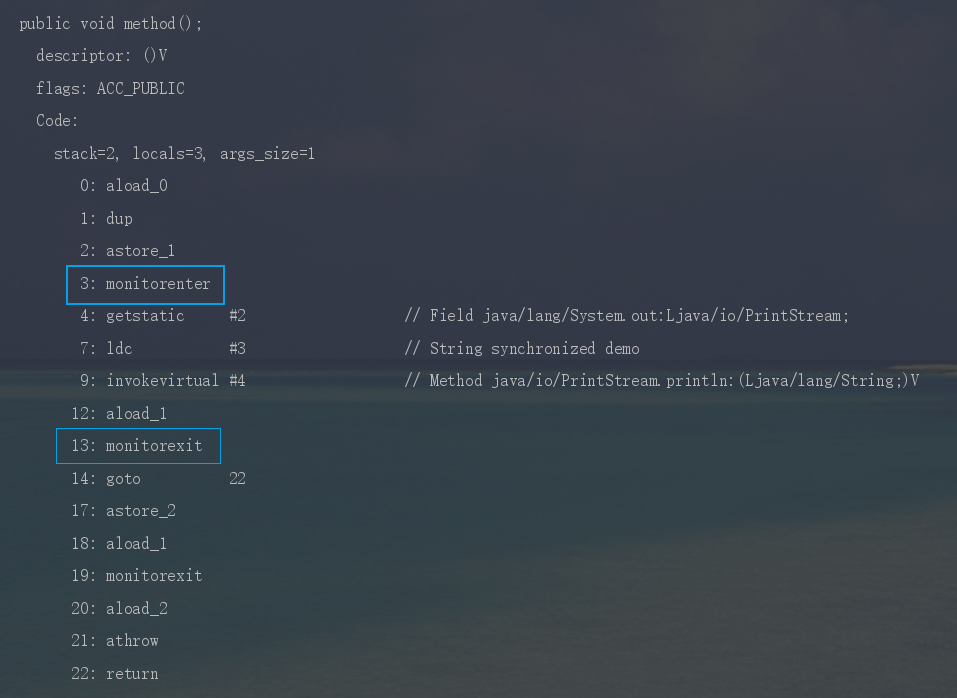
synchronized 依赖 JVM 内部的 Monitor 对象来实现线程同步。使用的时候不用手动去 lock 和 unlock,JVM 会自动加锁和解锁。
synchronized 加锁代码块时,JVM 会通过 monitorenter、monitorexit 两个指令来实现同步:
- 前者表示线程正在尝试获取 lock 对象的 Monitor;
- 后者表示线程执行完了同步代码块,正在释放锁。
使用 javap -c -s -v -l SynchronizedDemo.class 反编译 synchronized 代码块时,就能看到这两个指令。
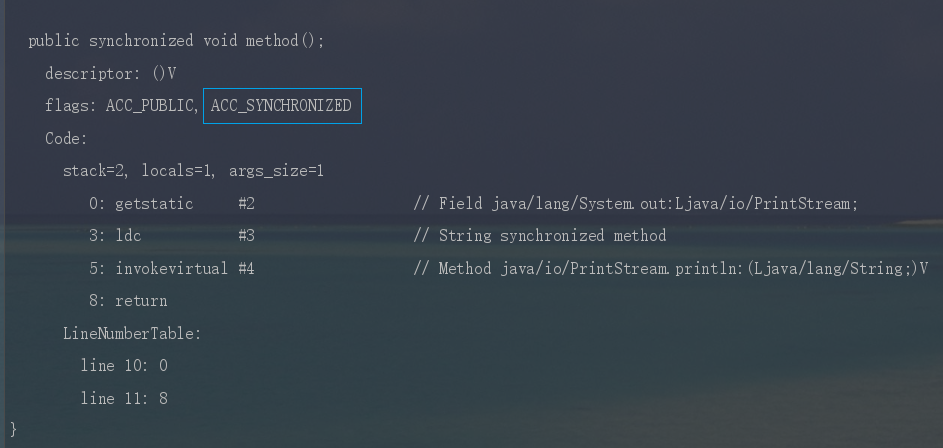
synchronized 修饰普通方法时,JVM 会通过 ACC_SYNCHRONIZED 标记符来实现同步。
java中创建一个对象的流程是什么
当我们使用 new 关键字创建一个对象时,JVM 首先会检查 new 指令的参数是否能在常量池中定位到类的符号引用,然后检查这个符号引用代表的类是否已被加载、解析和初始化。如果没有,就先执行类加载。
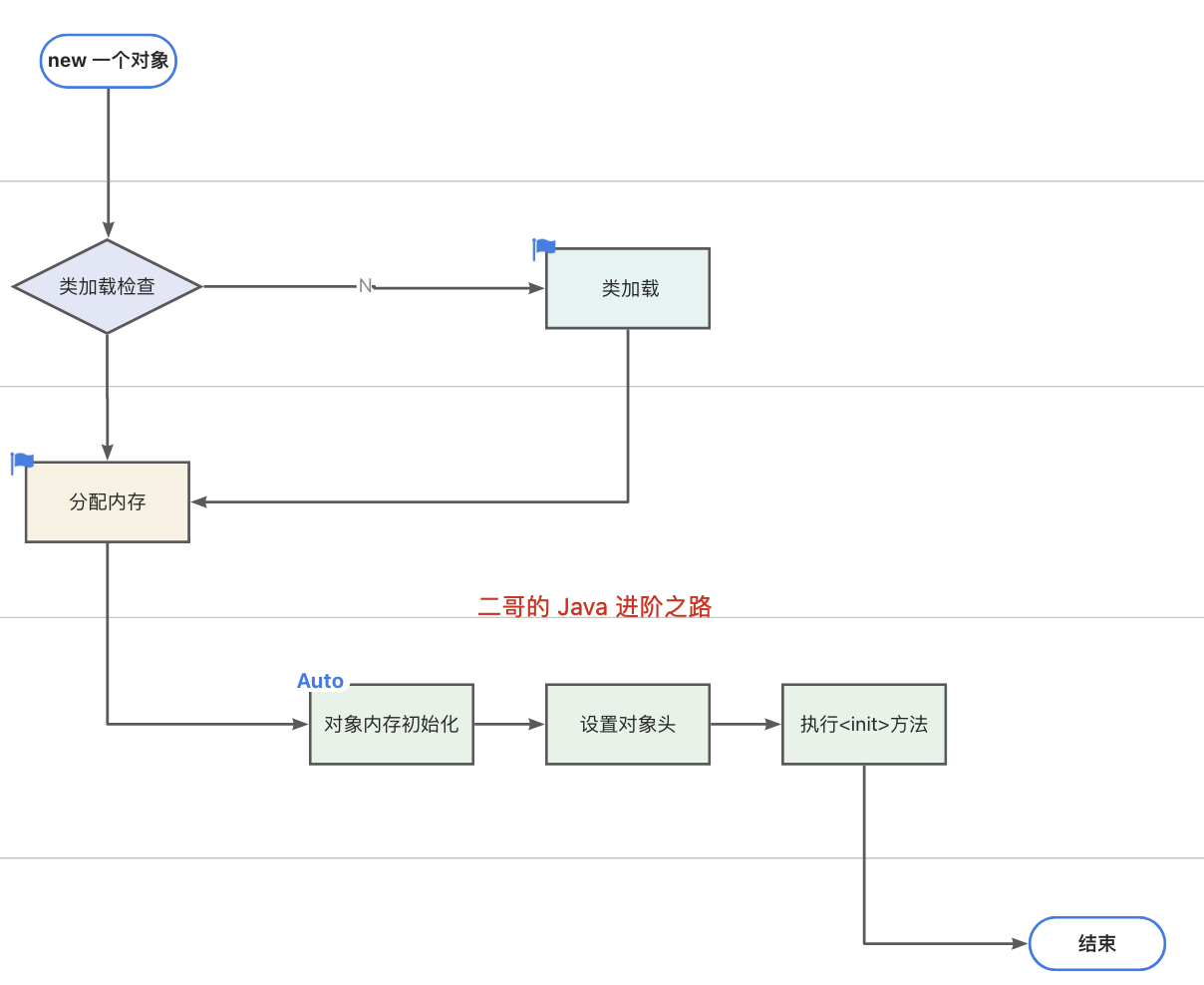
如果已经加载,JVM 会为对象分配内存完成初始化,比如数值类型的成员变量初始值是 0,布尔类型是 false,对象类型是 null。
接下来会设置对象头,里面包含了对象是哪个类的实例、对象的哈希码、对象的 GC 分代年龄等信息。
最后,JVM 会执行构造方法 <init> 完成赋值操作,将成员变量赋值为预期的值,比如 int age = 18,这样一个对象就创建完成了。
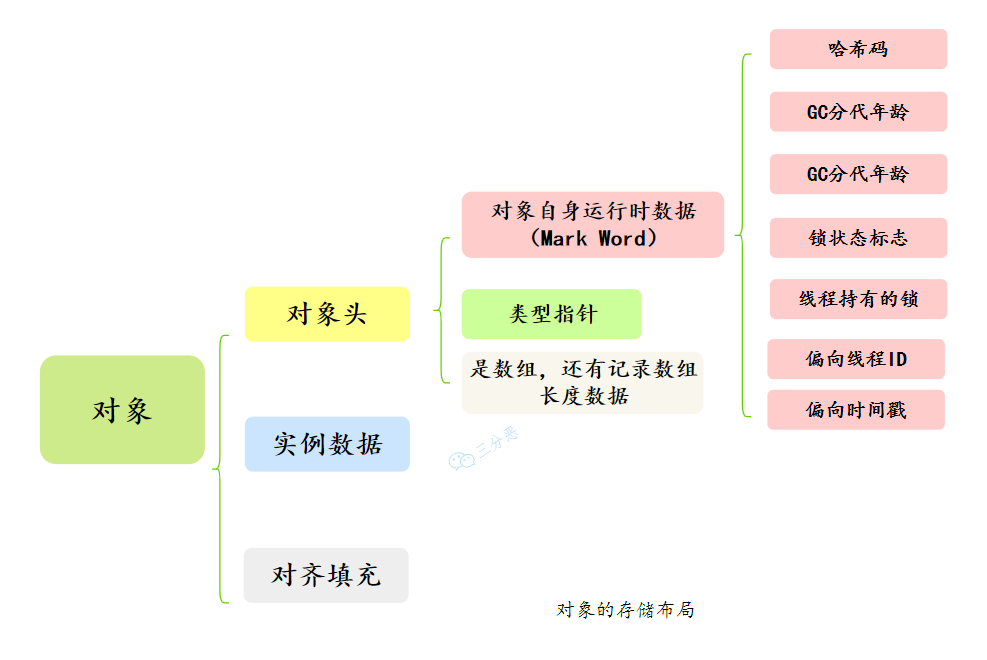
一个对象的结构是什么,包含哪些内容
对象的内存布局是由 Java 虚拟机规范定义的,但具体的实现细节各有不同,如 HotSpot 和 OpenJ9 就不一样。
就拿我们常用的 HotSpot 来说吧。对象在内存中包括三部分:对象头、实例数据和对齐填充。
说说数据库回表是什么意思
当使用非聚簇索引进行查询时,MySQL 需要先通过非聚簇索引找到主键值,然后再根据主键值回到聚簇索引中查找完整数据行,这个过程称为回表。
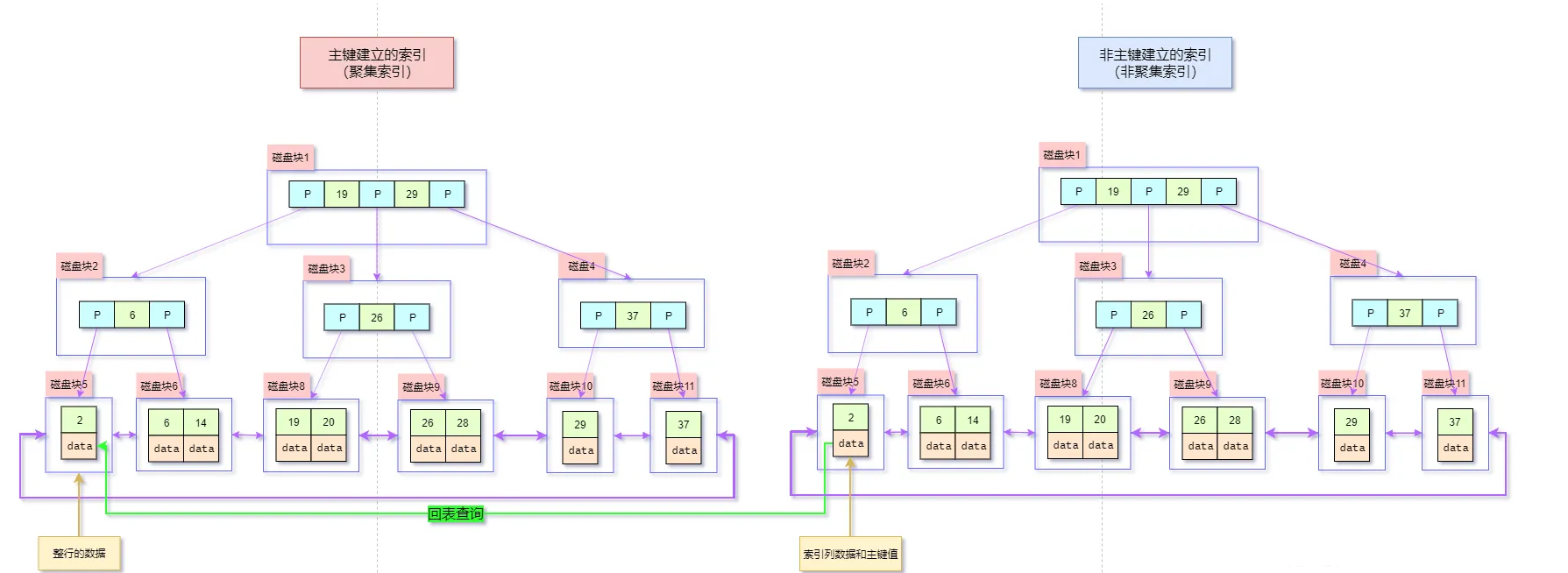
假设现在有一张用户表 users:
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(50),
age INT,
email VARCHAR(50),
INDEX (name)
);
执行查询:
SELECT * FROM users WHERE name = '王二';
查询过程如下:
- 第一步,MySQL 使用 name 列上的非聚簇索引查找所有
name = '王二'的主键 id。 - 第二步,使用主键 id 到聚簇索引中查找完整记录。
如果一个线上服务内存、CPU飙高,或者接口超时,说说大概的排查思路?具体可以用哪些工具?
CPU 占用过高怎么排查?
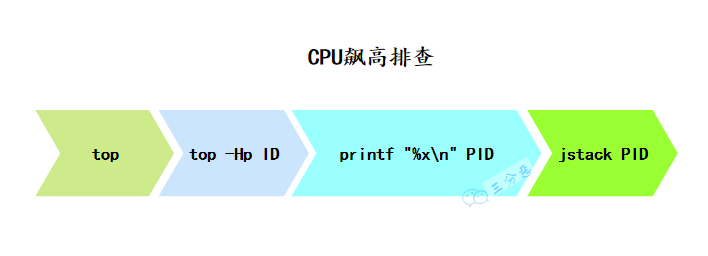
首先,使用 top 命令查看 CPU 占用情况,找到占用 CPU 较高的进程 ID。接着,使用 jstack 命令查看对应进程的线程堆栈信息。然后再使用 top 命令查看进程中线程的占用情况,找到占用 CPU 较高的线程 ID。
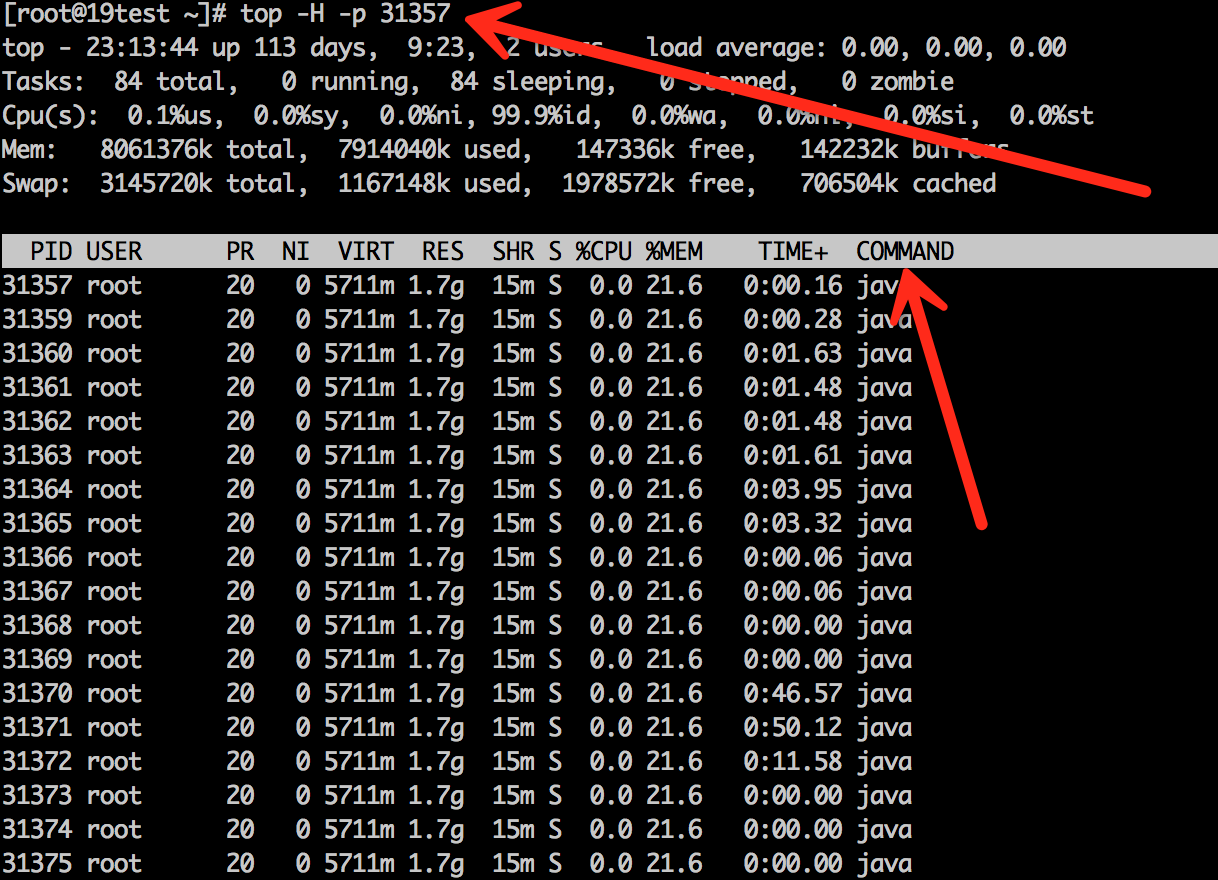
接着在 jstack 的输出中搜索这个十六进制的线程 ID,找到对应的堆栈信息。最后,根据堆栈信息定位到具体的业务方法,查看是否有死循环、频繁的垃圾回收、资源竞争导致的上下文频繁切换等问题。
内存飙高问题怎么排查?
内存飚高一般是因为创建了大量的 Java 对象导致的,如果持续飙高则说明垃圾回收跟不上对象创建的速度,或者内存泄漏导致对象无法回收。
排查的方法主要分为以下几步:
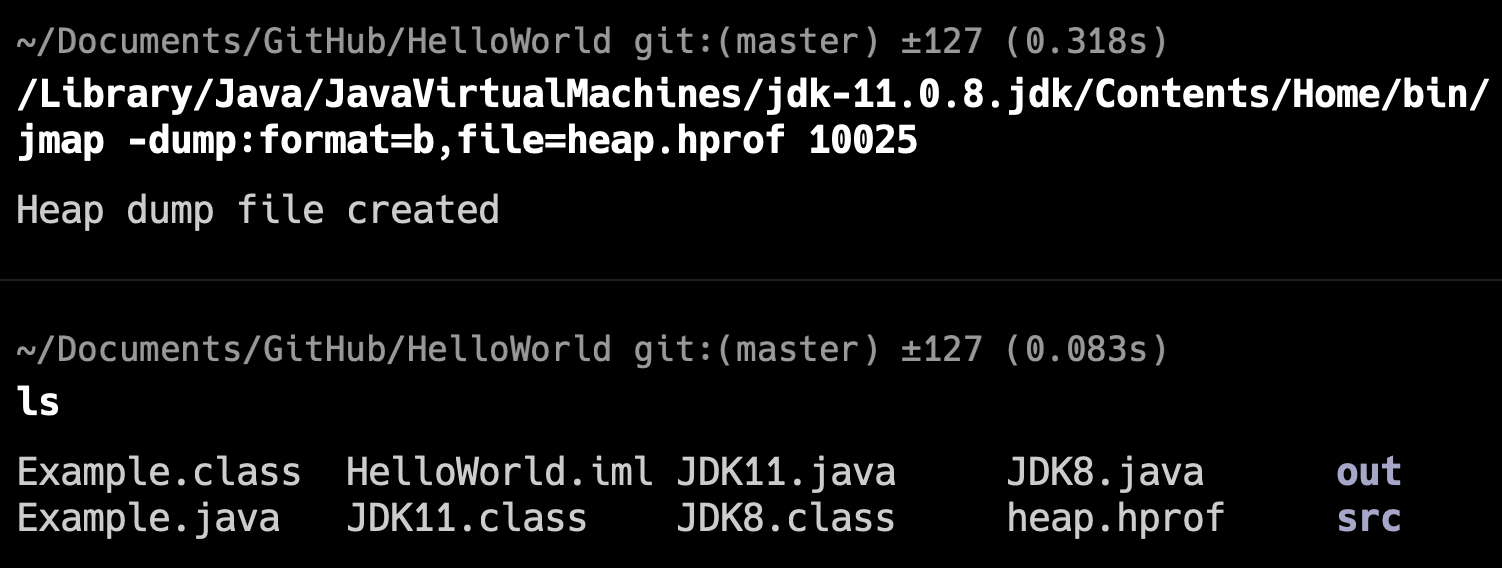
第一,先观察垃圾回收的情况,可以通过 jstat -gc PID 1000 查看 GC 次数和时间。或者使用 jmap -histo PID | head -20 查看堆内存占用空间最大的前 20 个对象类型。
第二步,通过 jmap 命令 dump 出堆内存信息。
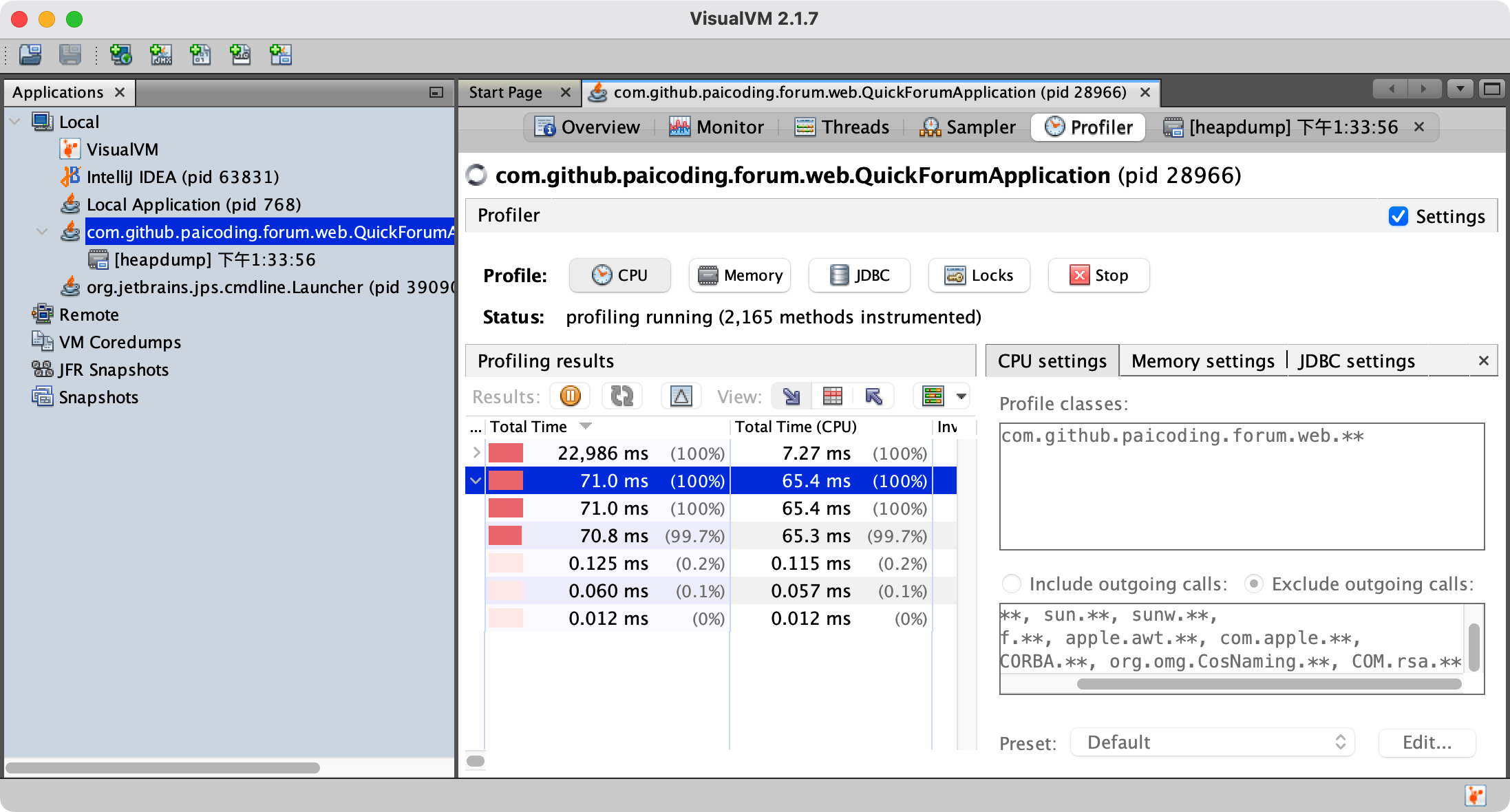
第三步,使用可视化工具分析 dump 文件,比如说 VisualVM,找到占用内存高的对象,再找到创建该对象的业务代码位置,从代码和业务场景中定位具体问题。
接口超时的问题排查过吗?
接口超时的排查要从多个层面分析。首先看应用层的监控,比如接口的响应时间分布、错误率、QPS 等指标。
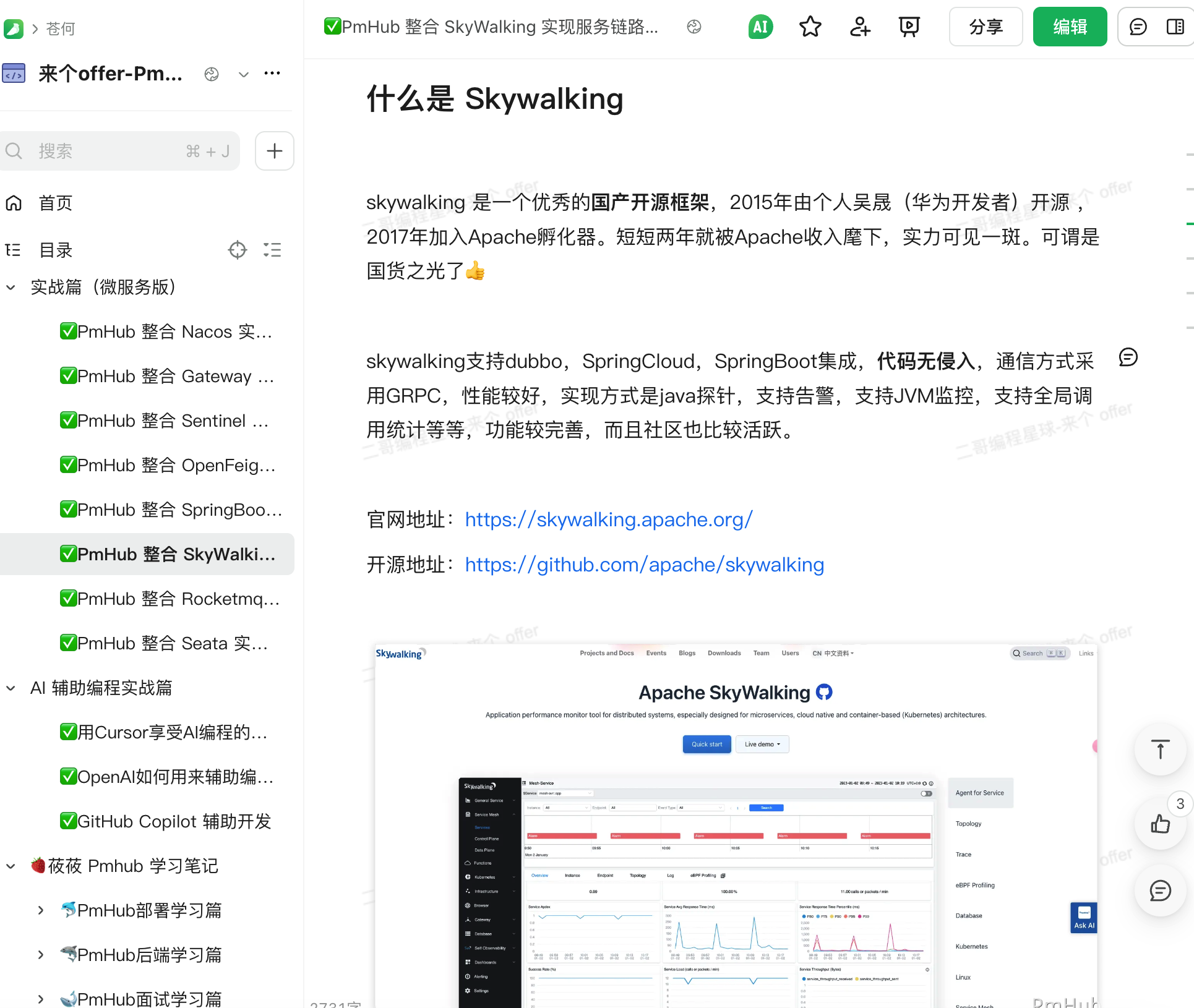
如果有 Skywalking 这种工具,可以看调用链路的详细耗时分布,定位是哪个环节慢了。
数据库层面要检查慢查询日志,看是不是某些 SQL 执行时间过长。可能是缺少索引、查询条件不合适、或者锁等待。我会用 EXPLAIN 分析 SQL 的执行计划,看是否需要优化。
网络层面也要考虑,比如下游服务响应慢、网络抖动等。可以通过 ping、telnet 等工具测试网络连通性和响应时间。
更多问题
一些重复性的问题大家可以直接通过面渣逆袭在线版查看。

ending
一个人可以走得很快,但一群人才能走得更远。二哥的编程星球已经有 9800 多名球友加入了,如果你也需要一个良好的学习环境,戳链接 🔗 加入我们吧。这是一个 简历精修 + 编程项目实战+ Java 面试指南的私密圈子,你可以阅读星球专栏、向二哥提问、帮你制定学习计划、和球友一起打卡成长。
两个置顶帖「球友必看」和「知识图谱」里已经沉淀了非常多优质的学习资源,相信能帮助你走的更快、更稳、更远。
欢迎点击左下角阅读原文了解二哥的编程星球,这可能是你学习求职路上最有含金量的一次点击。

最后,把二哥的座右铭送给大家:没有什么使我停留——除了目的,纵然岸旁有玫瑰、有绿荫、有宁静的港湾,我是不系之舟。共勉 💪。



回复