



大家好,我是二哥呀。
最近有不少同学反馈不知道该投哪些公司了,那我这里再给大家分享一个榜单,基本上都是国内的科技独角兽公司,帮大家打开思路。
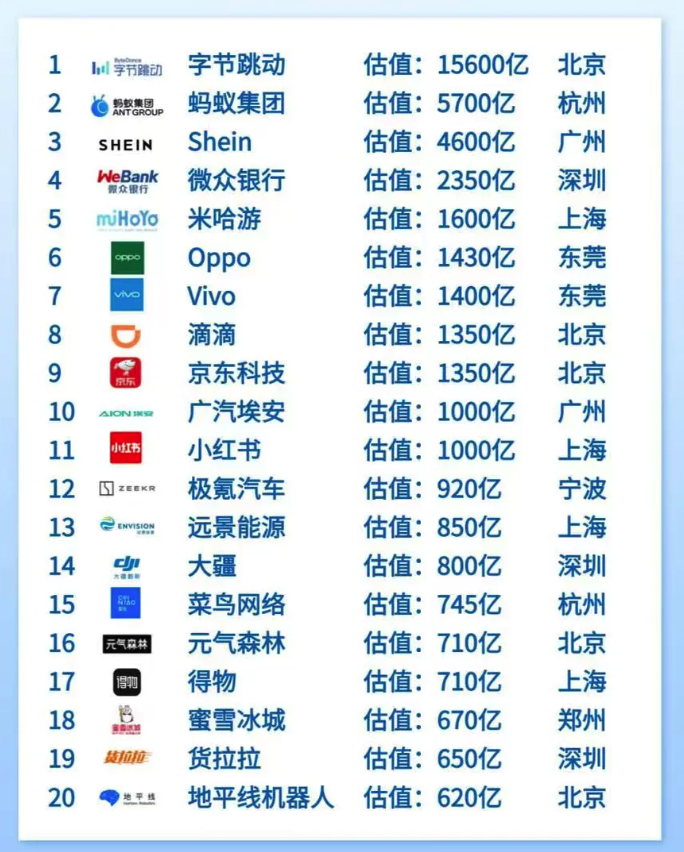
前 20 名分别是字节跳动、蚂蚁、shein、微众银行、米哈游、Oppo、vivo。。。。。。得物、蜜雪、货拉拉、地平线机器人等。
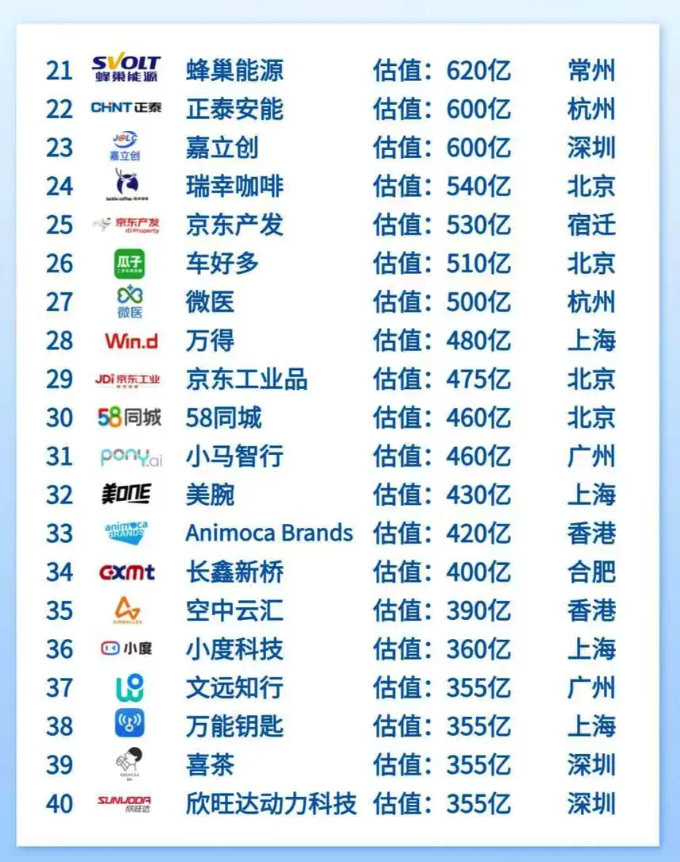
接着依次是瑞幸、万得、小马智行、小度科技、欣旺达等等。
这里科普一嘴,独角兽是指「2000年后成立+估值超10亿美金的非上市公司」,涵盖 AI、新能源、半导体等热门赛道,不知道有没有你认知以外的公司在里面?
如果有公司你还没有去投,是时候去冲一波了。
9 月底,我知道很多同学已经焦躁不安,有点撑不住了,这时候最重要的就是稳住心态。因为 HR 和面试官也疲惫了,等国庆过后,应该是一波非常好的机会。
长假过后,精神气爽。
我这段时间会高频给大家分享一些经典的八股和项目&场景,还没 offer 的同学一定要在别人懈怠的时候偷偷超车。
刚好最近有位球友参加了 Oppo 的线下面试,那我们就以榜单上的第六名 Oppo 为切入点,来复盘一下一面题目:

有基础的 Java 后端四大件八股,也有实习和派聪明 RAG 项目,还是非常典型的、有参加价值的一场面试。
Oppo一面
自我介绍
我是来自家里蹲大学的小王,拿到过 xx 年度的国家励志奖学金,拿到过 xxx 年度的竞赛第二名;刚好之前也在 vivo 实习过,主要负责 xxxx,有哪些量化数据巴拉巴拉。
项目目前做了一个派聪明,和一个 MySQL 的轮子项目。
其中派聪明是一个企业级的 AI 知识库管理系统 。它的核心功能是对用户上传的私有文档(比如 Word、PDF、txt 等),进行语义解析和向量处理,然后存储到 ElasticSearch 中以供后续的关键词检索和语义检索。
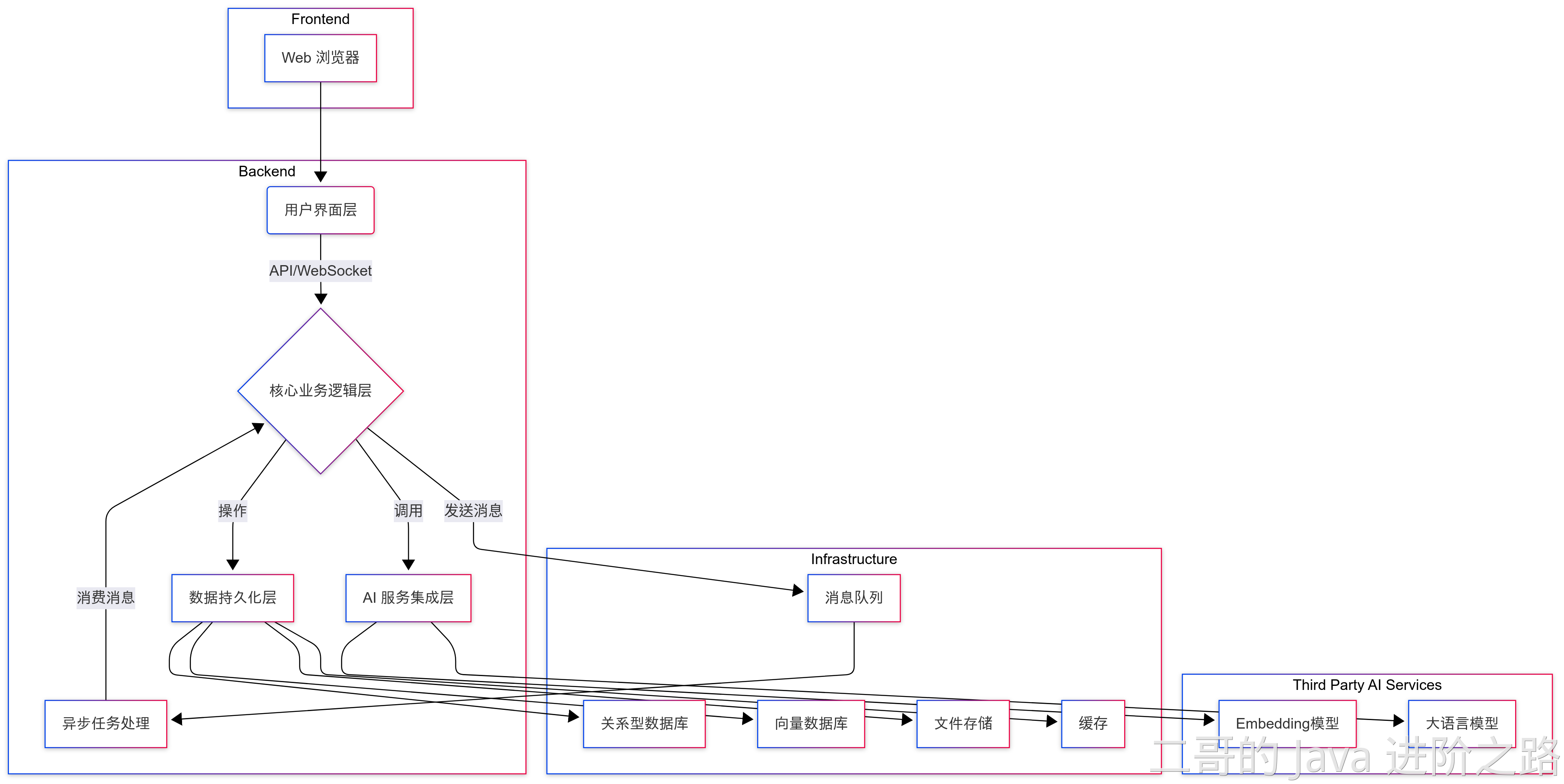
当用户通过聊天界面进行对话时,系统会将用户输入的内容进行语义转化,通过 ES 的混合检索召回 TOPK 个相关信息,最后再将最近的上下文一起封装到 prompt,再发送给 LLM,从而实现检索增强生成,也就是利用 RAG 的技术架构来减少模型的输出幻觉。
另外一个项目xxxx。
我个人也是 Oppo 手机的忠实用户,也非常期待能加入到 Oppo 这个大家庭。
CopyOnWrite原理
CopyOnWrite 的核心思想是写操作时创建一个新数组,修改后再替换原数组,这样就能够确保读操作无锁,从而提高并发性能。
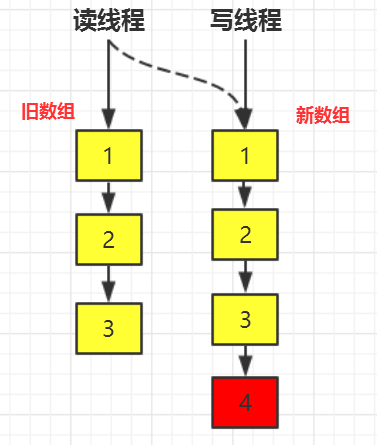
内部使用 volatile 变量来修饰数组 array,以确保读操作的内存可见性。
private transient volatile Object[] array;
写操作的时候使用 ReentrantLock 来保证线程安全。
public boolean add(E e) {
final ReentrantLock lock = this.lock;
// 加锁
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
// 创建一个新数组
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
// 替换原数组
setArray(newElements);
return true;
} finally {
// 释放锁
lock.unlock();
}
}
缺点就是写操作的时候会复制一个新数组,如果数组很大,写操作的性能会受到影响。
CAS操作,带来哪些问题
CAS 存在三个经典问题,ABA 问题、自旋开销大、只能操作一个变量等。
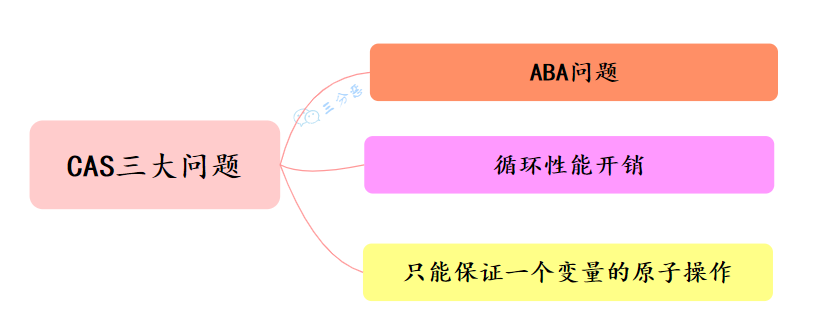
ABA 问题指的是,一个值原来是 A,后来被改为 B,再后来又被改回 A,这时 CAS 会误认为这个值没有发生变化。
线程 1:CAS(A → B),修改变量 A → B
线程 2:CAS(B → A),变量又变回 A
线程 3:CAS(A → C),CAS 成功,但实际数据已被修改过!
可以使用版本号/时间戳的方式来解决 ABA 问题。
比如说,每次变量更新时,不仅更新变量的值,还更新一个版本号。CAS 操作时,不仅比较变量的值,还比较版本号。
CAS 失败时会不断自旋重试,如果一直不成功,会给 CPU 带来非常大的执行开销。
可以加一个自旋次数的限制,超过一定次数,就切换到 synchronized 挂起线程。
jvm垃圾回收有哪些阶段、哪些阶段STW、G1回收器原理
Java 的垃圾回收过程主要分为标记存活对象、清除无用对象、以及内存压缩/整理三个阶段。不同的垃圾回收器在执行这些步骤时会采用不同的策略和算法。
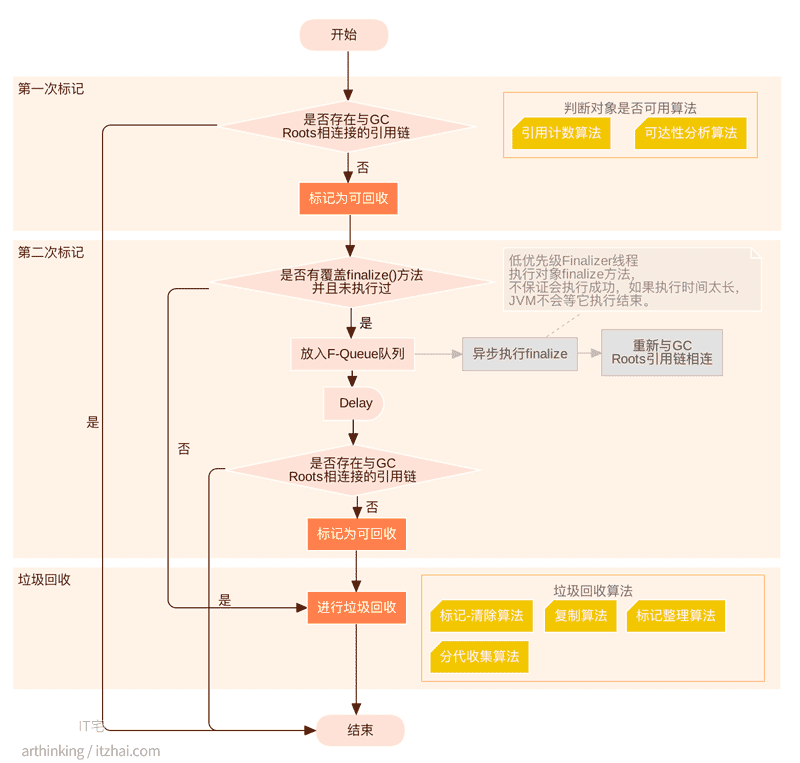
哪些阶段会触发 STW?
STW 是 JVM 为了垃圾回收而暂停所有用户线程的机制。
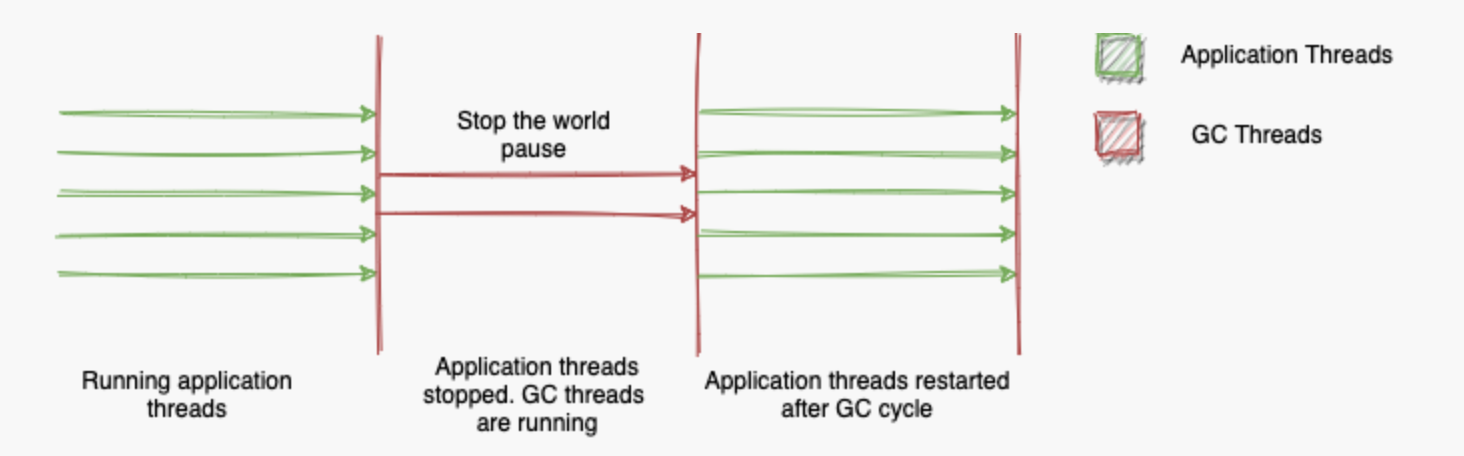
对于新生代的垃圾收集器 Serial 和 ParNew,整个垃圾回收过程都会触发 STW,但因为年轻代小,通常很快(几毫秒到几十毫秒)。
1. 初始标记(STW)
- 暂停所有用户线程
- 标记 GC Roots 直接引用的对象
2. 复制存活对象(STW)
- 将 Eden 和 Survivor0 中的存活对象复制到 Survivor1
- 清空 Eden 和 Survivor0
3. 更新引用(STW)
- 更新所有指向移动对象的引用
CMS 在此基础上进行了改进,通过并发执行来减少 STW 时间,会在初始标记和重新标记阶段触发 STW。
1. 初始标记 Initial Mark(STW)✅
- 时间很短
- 仅标记 GC Roots 直接引用的对象
- 标记所有年轻代对象引用的老年代对象
2. 并发标记 Concurrent Mark(并发执行)
- 用户线程继续运行
- GC 线程遍历整个对象图
- 标记所有存活对象
3. 重新标记 Remark(STW)✅
- 修正并发标记期间的变化
- 使用增量更新算法
- 这个阶段时间比初始标记长
4. 并发清除 Concurrent Sweep(并发执行)
- 用户线程继续运行
- 清理未标记的对象
- 不进行压缩,会产生碎片
G1 垃圾收集器了解吗?
G1 在 JDK 1.7 时引入,在 JDK 9 时取代 CMS 成为默认的垃圾收集器。
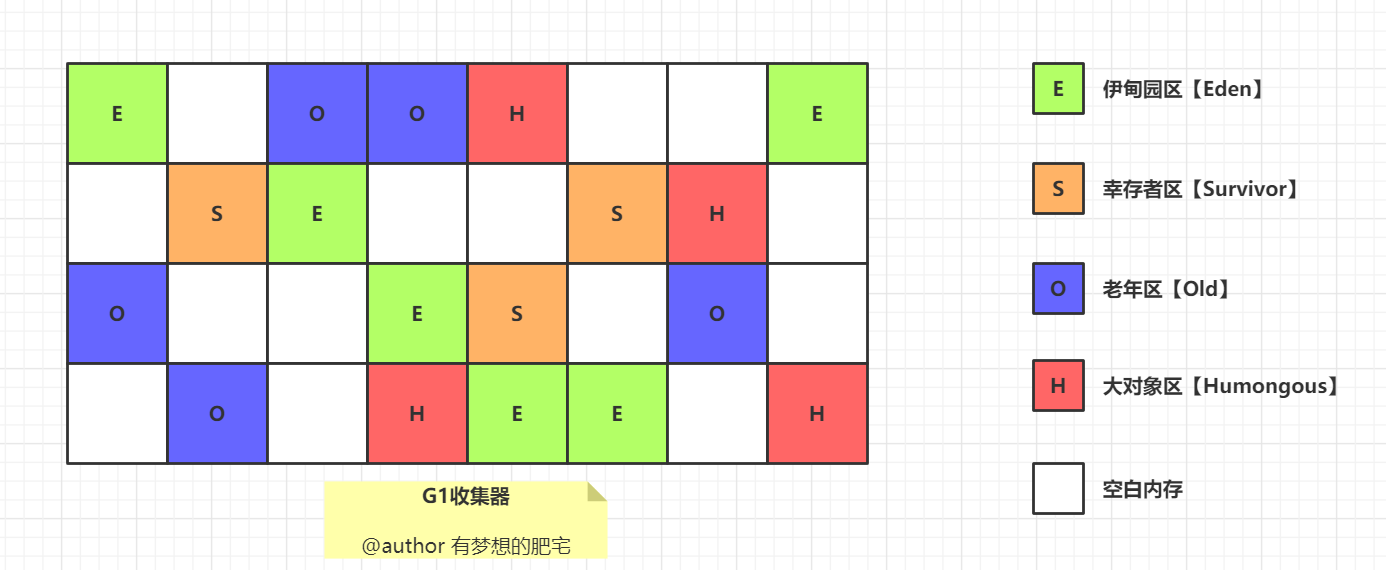
G1 把 Java 堆划分为多个大小相等的独立区域 Region,每个区域都可以扮演新生代或老年代的角色。
同时,G1 还有一个专门为大对象设计的 Region,叫 Humongous 区。
大对象的判定规则是,如果一个大对象超过了一个 Region 大小的 50%,比如每个 Region 是 2M,只要一个对象超过了 1M,就会被放入 Humongous 中。
这种区域化管理使得 G1 可以更灵活地进行垃圾收集,只回收部分区域而不是整个新生代或老年代。
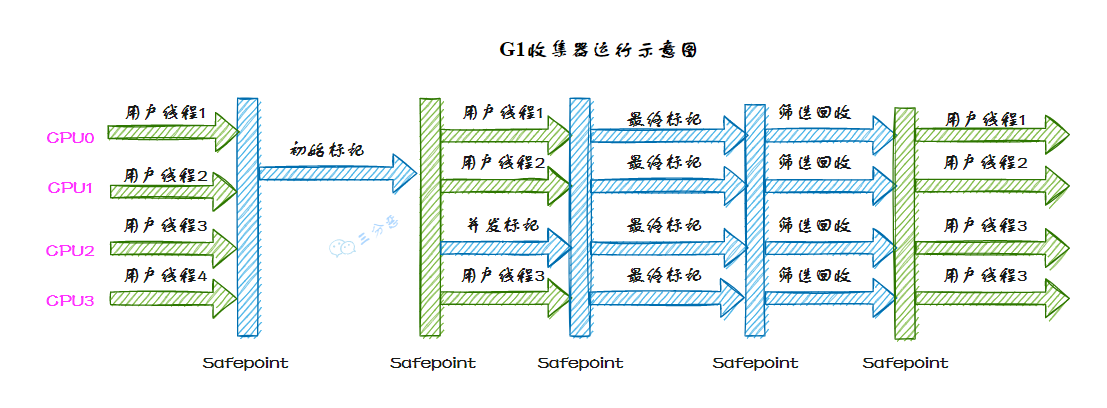
G1 收集器的运行过程大致可划分为这几个步骤:
①、并发标记,G1 通过并发标记的方式找出堆中的垃圾对象。并发标记阶段与应用线程同时执行,不会导致应用线程暂停。
②、混合收集,在并发标记完成后,G1 会计算出哪些区域的回收价值最高(也就是包含最多垃圾的区域),然后优先回收这些区域。这种回收方式包括了部分新生代区域和老年代区域。
选择回收成本低而收益高的区域进行回收,可以提高回收效率和减少停顿时间。
③、可预测的停顿,G1 在垃圾回收期间仍然需要「Stop the World」。不过,G1 在停顿时间上添加了预测机制,用户可以 JVM 启动时指定期望停顿时间,G1 会尽可能地在这个时间内完成垃圾回收。
spring自动装配原理
自动装配的本质就是让 Spring 容器自动帮我们完成 Bean 之间的依赖关系注入,而不需要我们手动去指定每个依赖。简单来说,就是“我们不用告诉 Spring 具体怎么注入,Spring 自己会想办法找到合适的 Bean 注入进来”。
自动装配的工作原理简单来说就是,Spring 容器在启动时自动扫描 @ComponentScan 指定包路径下的所有类,然后根据类上的注解,比如 @Autowired、@Resource 等,来判断哪些 Bean 需要被自动装配。
@Configuration
@ComponentScan("com.github.paicoding.forum.service")
@MapperScan(basePackages = {
"com.github.paicoding.forum.service.article.repository.mapper",
"com.github.paicoding.forum.service.user.repository.mapper"
// ... 更多包路径
})
public class ServiceAutoConfig {
// Spring自动扫描指定包下的所有组件并注册为Bean
}
之后分析每个 Bean 的依赖关系,在创建 Bean 的时候,根据装配规则自动找到合适的依赖 Bean,最后根据反射将这些依赖注入到目标 Bean 中。
Spring Boot的启动原理了解吗?
Spring Boot 的启动主要围绕两个核心展开,一个是 @SpringBootApplication 注解,一个是 SpringApplication.run() 方法。
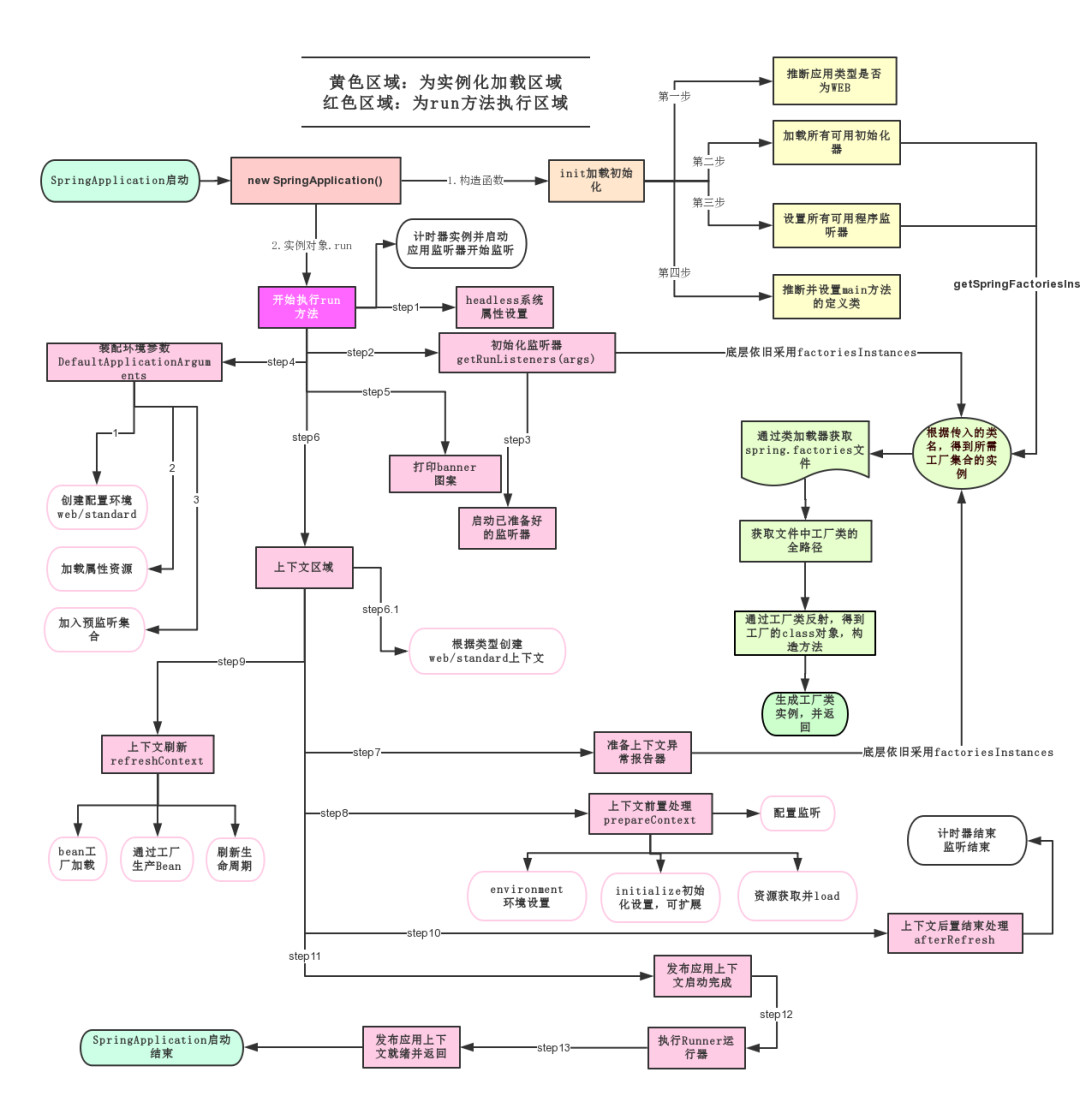
SpringApplication.run() 方法是 Spring Boot 项目的启动入口,内部流程大致可以分为 5 个步骤:
①、创建 SpringApplication 实例,并识别应用类型,比如说是标准的 Servlet Web 还是响应式的 WebFlux,然后准备监听器和初始化监听容器。
②、创建并准备 ApplicationContext,将主类作为配置源进行加载。
③、刷新 Spring 上下文,触发 Bean 的实例化,比如说扫描并注册 @ComponentScan 指定路径下的 Bean。
④、触发自动配置,在 Spring Boot 2.7 及之前是通过 spring.factories 加载的,3.x 是通过读取 AutoConfiguration.imports,并结合 @ConditionalOn 系列注解依据条件注册 Bean。
⑤、如果引入了 Web 相关依赖,会创建并启动 Tomcat 容器,完成 HTTP 端口监听。
要在启动阶段自定义逻辑该怎么做?
可以通过实现 ApplicationRunner 接口来完成启动后的自定义逻辑。
比如说在技术派项目中,我们就在 run 方法中追加了:JSON 类型转换配置和动态设置应用访问地址等。
redis缓存穿透的解决方案?
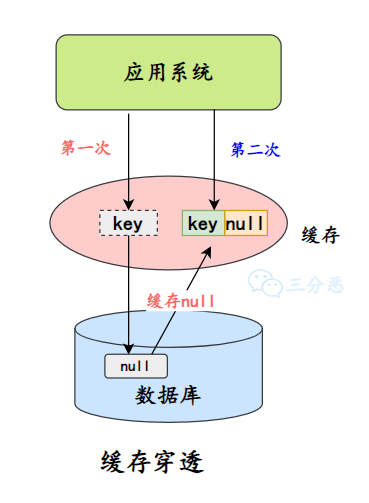
缓存穿透是指查询的数据在缓存中没有命中,因为数据压根不存在,所以请求会直接落到数据库上。如果这种查询非常频繁,就会给数据库造成很大的压力。
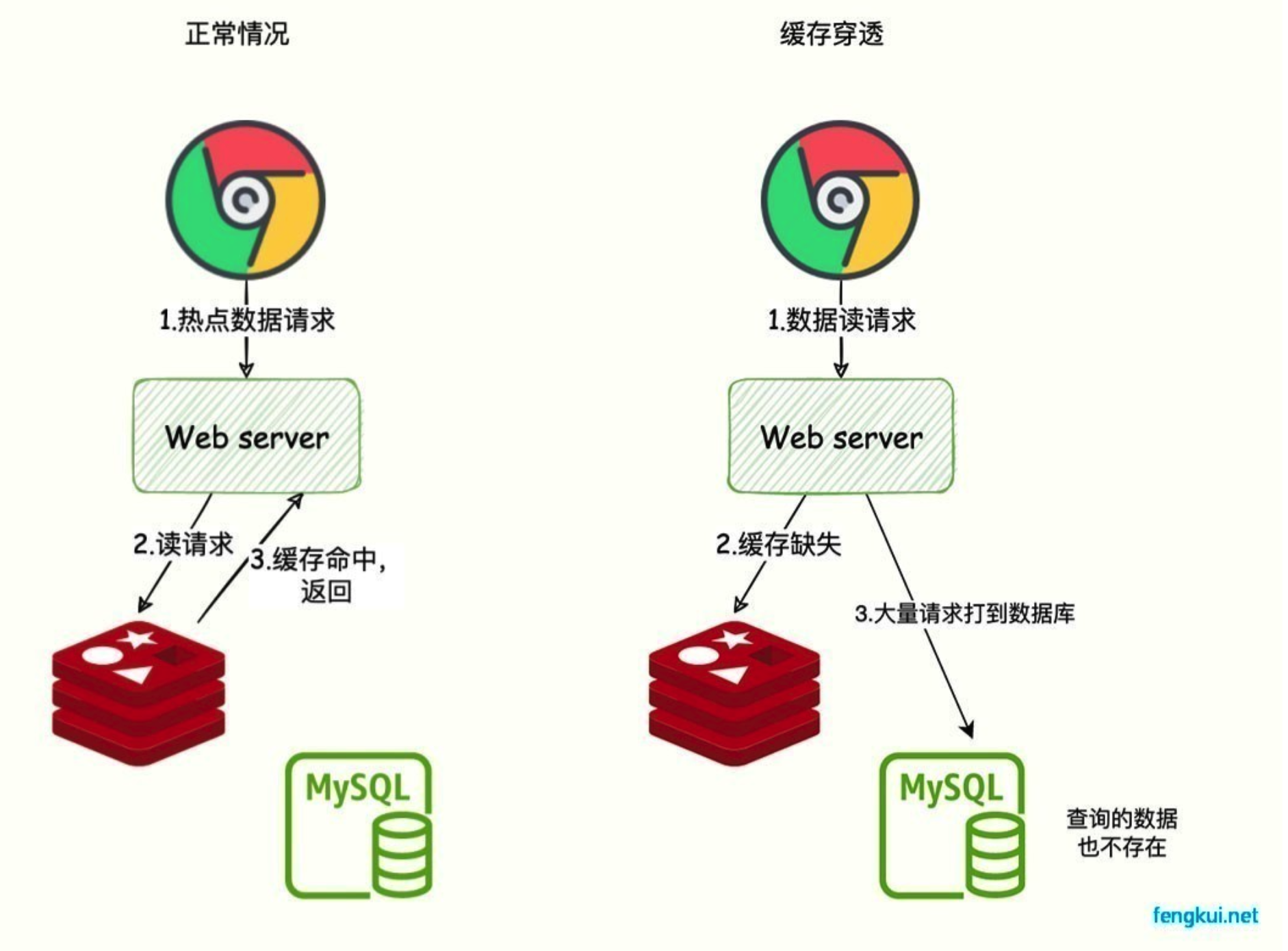
缓存击穿是因为单个热点数据缓存失效导致的,而缓存穿透是因为查询的数据不存在,原因可能是自身的业务代码有问题,或者是恶意攻击造成的,比如爬虫。
常用的解决方案有两种:第一种是布隆过滤器,它是一种空间效率很高的数据结构,可以用来判断一个元素是否在集合中。
我们可以将所有可能存在的数据哈希到布隆过滤器中,查询时先检查布隆过滤器,如果布隆过滤器认为该数据不存在,就直接返回空;否则再去查询缓存,这样就可以避免无效的缓存查询。
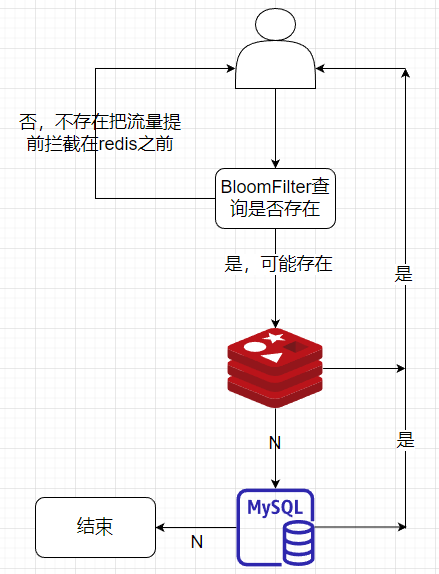
布隆过滤器存在误判,即可能会认为某个数据存在,但实际上并不存在。但绝不会漏判,即如果布隆过滤器认为某个数据不存在,那它一定不存在。因此它可以有效拦截不存在的数据查询,减轻数据库压力。
第二种是缓存空值。对于不存在的数据,我们将空值写入缓存,并设置一个合理的过期时间。这样下次相同的查询就能直接从缓存返回,而不再访问数据库。
布隆过滤器为什么不支持删除?怎么样支持删除?
布隆过滤器并不支持删除操作,这是它的一个重要限制。
当我们添加一个元素时,会将位数组中的 k 个位置设置为 1。由于多个不同元素可能共享相同的位,如果我们尝试删除一个元素,将其对应的 k 个位重置为 0,可能会错误地影响到其他元素的判断结果。
例如,元素 A 和元素 B 都将位置 5 设为 1,如果删除元素 A 时将位置 5 重置为 0,那么对元素 B 的查询就会产生错误的"不存在"结果,这违背了布隆过滤器的基本特性。
如果想要实现删除操作,可以使用计数布隆过滤器,它在每个位置上存储一个计数器而不是单一的位。这样可以通过减少计数器的值来实现删除操作,但会增加内存开销。
public class CountingBloomFilter<T> {
private int[] counters;
private int size;
private int hashFunctions;
public CountingBloomFilter(int size, int hashFunctions) {
this.size = size;
this.hashFunctions = hashFunctions;
this.counters = new int[size];
}
public void add(T element) {
int[] positions = getHashPositions(element);
for (int position : positions) {
counters[position]++;
}
}
public void remove(T element) {
int[] positions = getHashPositions(element);
for (int position : positions) {
if (counters[position] > 0) {
counters[position]--;
}
}
}
public boolean mightContain(T element) {
int[] positions = getHashPositions(element);
for (int position : positions) {
if (counters[position] == 0) {
return false;
}
}
return true;
}
private int[] getHashPositions(T element) {
// 计算哈希位置的代码
}
}
介绍一下怎么使用ES和embedding实现检索的?ES里面存的是什么?
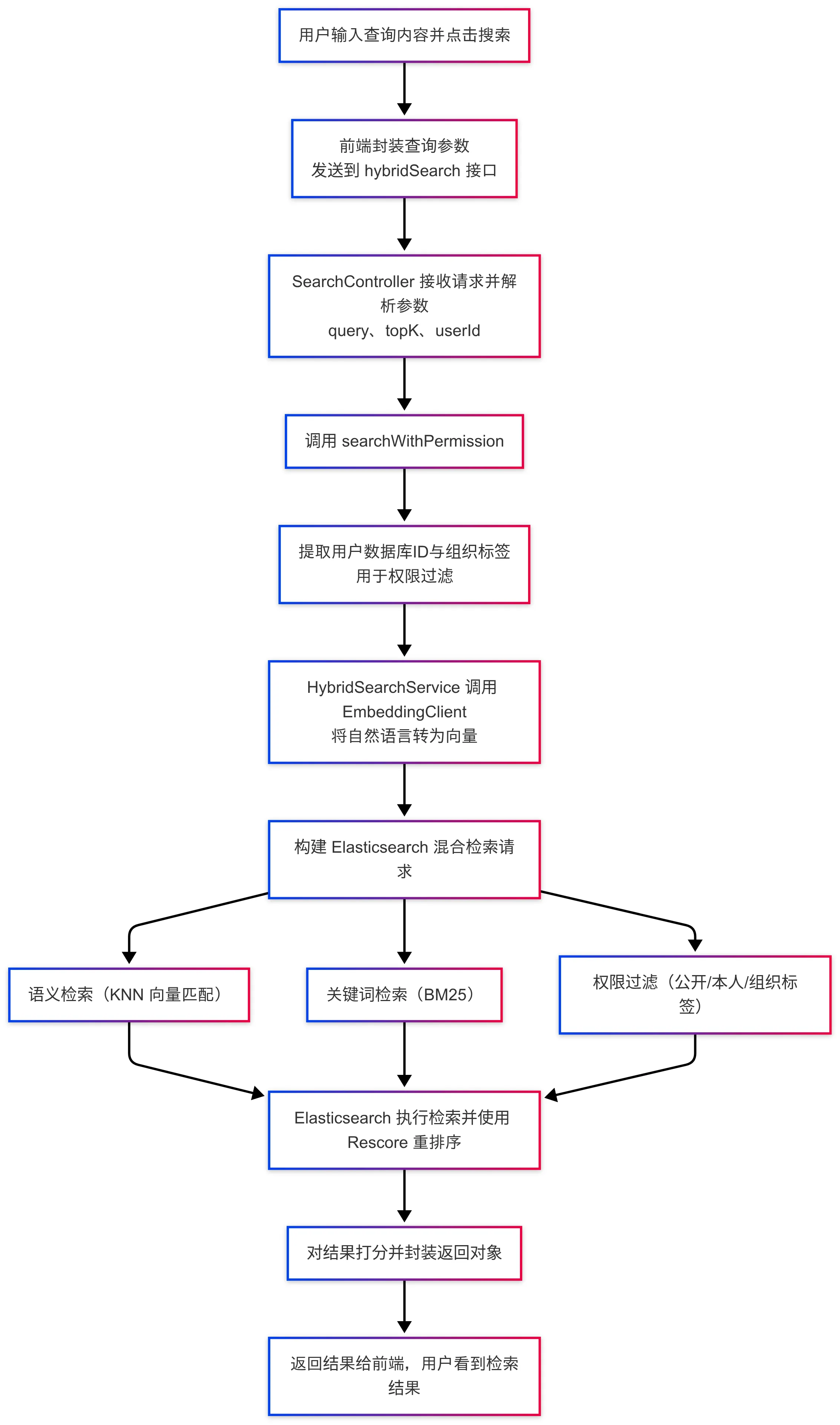
首先,用户通过前端页面输入搜索内容并提交,前端会将查询语句、用户信息等参数封装成 HTTP 请求发送到后端。后端接收到请求后,会解析出查询关键词和用户身份。
在进入搜索逻辑前,系统首先会调用外部的 Embedding 模型将用户的自然语言查询转化为向量表示。这一步是实现语义相似度搜索的基础。同时,系统还会提取出用户对应的组织标签,用于后续的权限过滤。
随后,系统会构造出一个 Elasticsearch 混合查询。融合了三类能力:首先是基于查询向量的 KNN 语义检索,用于找出语义上最接近的文本块;其次是基于关键词的 BM25 检索,用于匹配关键词相似的文档;最后是权限过滤机制,确保返回的文档必须是公开的、或属于该用户本人,或其组织标签在用户的有效标签列表中。
为了提高结果的相关性和精度,我们还会使用 Elasticsearch 的 rescore 机制,根据 BM25 与向量匹配的得分对初步召回的结果进行重排序,找到最终排名靠前的文档,并打分后返回给前端。
我们在 ElasticSearch 中新建了一个名 knowledge_base 的索引,它将为每一条数据存储两种关键信息。
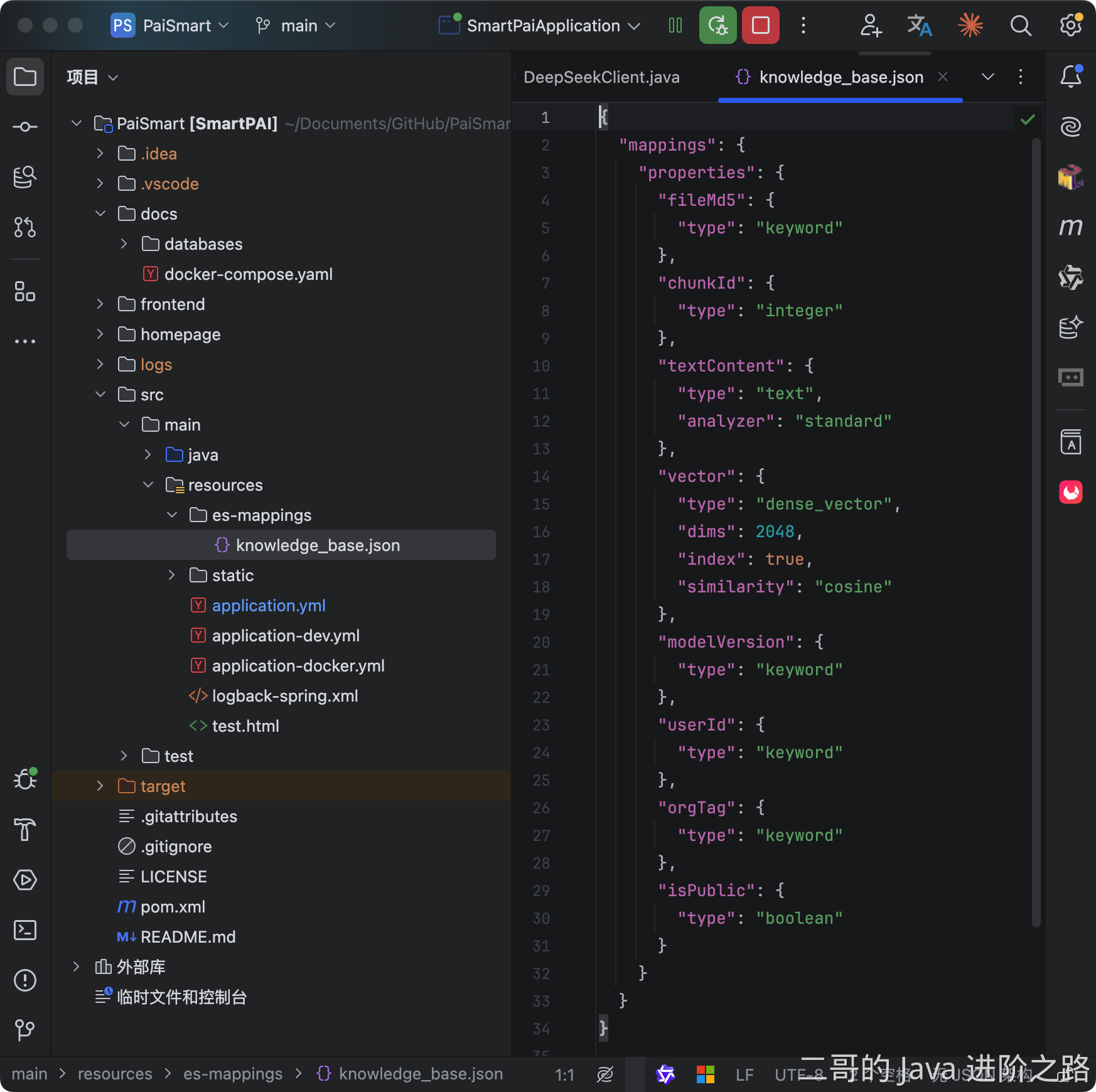
textContent 字段的类型定义为"text",专门用于全文搜索。当文档存入 ES 时,其内容会被分析器拆解成独立的词语,并建立倒排索引。这个结构是实现快速、高效关键词匹配的基石。
vector 字段的类型定义为 "dense_vector", 专门存储文本的“语义指纹”。文档内容在存入前,会被 Embedding 模型转换成一个 2048 维的数学向量。这个向量使得系统可以在语义层面进行相似性比较,是实现向量搜索的根本。
看你用过AI,说说你对现在AI发展的理解吧?能帮我们干什么?
我觉得未来的 AI 会变得更加"无感化",就像现在的互联网一样,我们不会觉得自己在用互联网,但它已经渗透到生活的方方面面。AI 也会是这样,不再是一个独立的产品,而是融入到各种业务系统中。
从技术架构的角度来说,我觉得未来的 AI 系统会更加模块化和标准化。就像现在我们用的 Spring AI 框架,能让我们开发者很容易地把 AI 能力集成到自己的应用中。可能几行代码就能给系统加上智能推荐、自动分析、智能客服这些功能。AI Agent 我觉得会变得更加专业化和垂直化。
现在的 Agent 还比较通用,但是未来可能会有专门的代码审查 Agent、专门的运维 Agent、专门的测试 Agent 等等。每个 Agent 在自己的领域内会变得非常专业,甚至超过普通的工程师。现在各大厂的 AI Coding 也都在主力推这些工具。
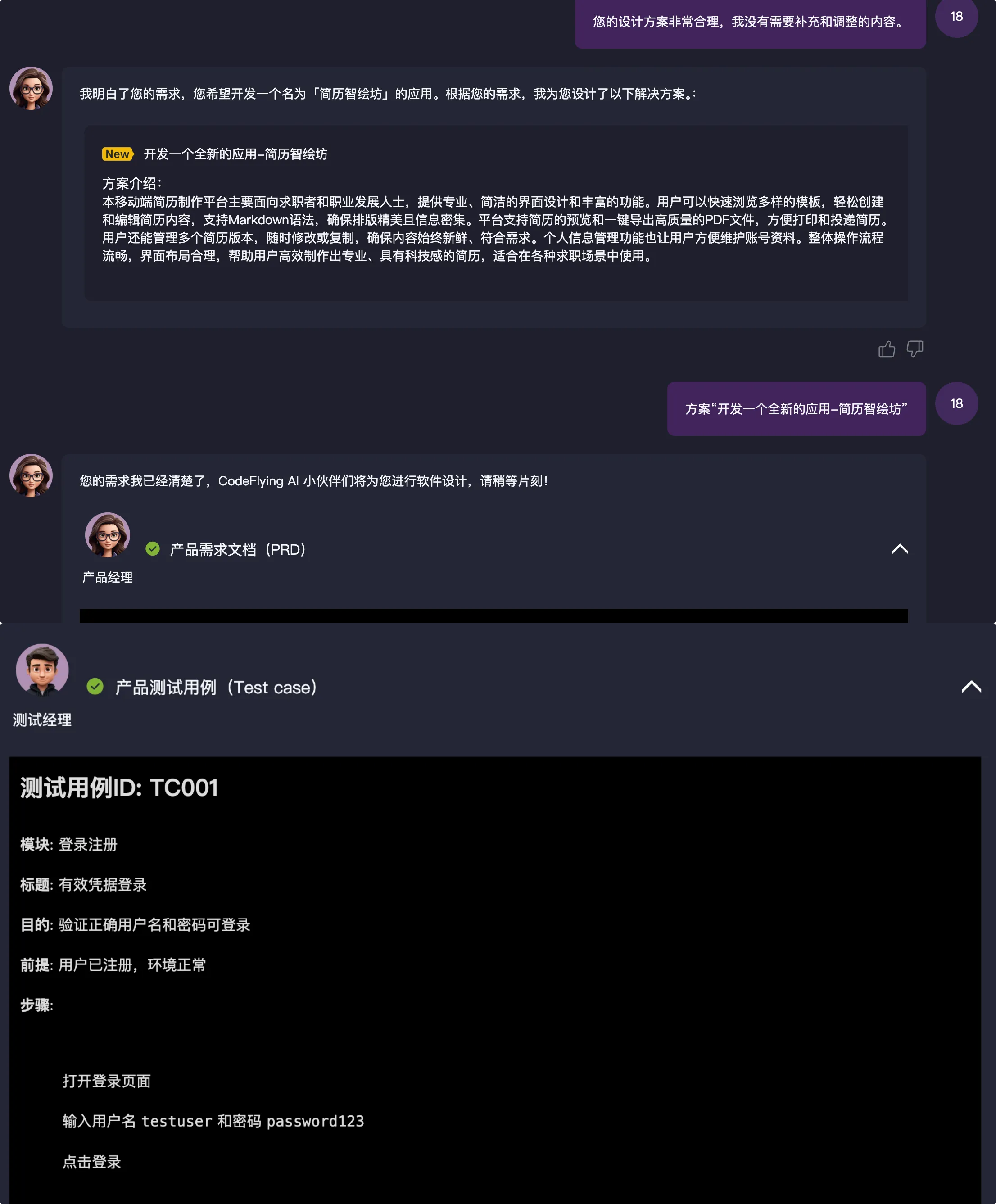
另外我觉得多 Agent 协作会成为趋势。就像现在的微服务架构一样,不同的 Agent 负责不同的职能,然后通过某种协议来协作完成复杂的任务。比如一个需求进来,产品 Agent 负责理解需求,架构 Agent 负责系统设计,开发 Agent 负责写代码,测试 Agent 负责测试,运维 Agent 负责部署。
从我们后端开发的工作来说,我觉得 AI 不会完全替代我们,但是会改变我们的工作方式。可能以后我们更多的是在设计系统架构、定义业务规则、优化性能这些高层次的工作上,而一些重复性的编码工作会被 AI 处理。
不过说实话,技术变化这么快,具体会发展成什么样很难预测。但有一点我比较确定,就是会越来越智能,越来越好用。
更多问题
一些重复性的问题大家可以直接通过面渣逆袭在线版查看。

ending
一个人可以走得很快,但一群人才能走得更远。二哥的编程星球已经有 9800 多名球友加入了,如果你也需要一个良好的学习环境,戳链接 🔗 加入我们吧。这是一个 简历精修 + 编程项目实战+ Java 面试指南的私密圈子,你可以阅读星球专栏、向二哥提问、帮你制定学习计划、和球友一起打卡成长。
两个置顶帖「球友必看」和「知识图谱」里已经沉淀了非常多优质的学习资源,相信能帮助你走的更快、更稳、更远。
欢迎点击左下角阅读原文了解二哥的编程星球,这可能是你学习求职路上最有含金量的一次点击。

最后,把二哥的座右铭送给大家:没有什么使我停留——除了目的,纵然岸旁有玫瑰、有绿荫、有宁静的港湾,我是不系之舟。共勉 💪。




回复