


前面我们讲了,为了提升 Java 运行时的性能,JVM 引入了 JIT,也就是即时编译(Just In Time)技术。
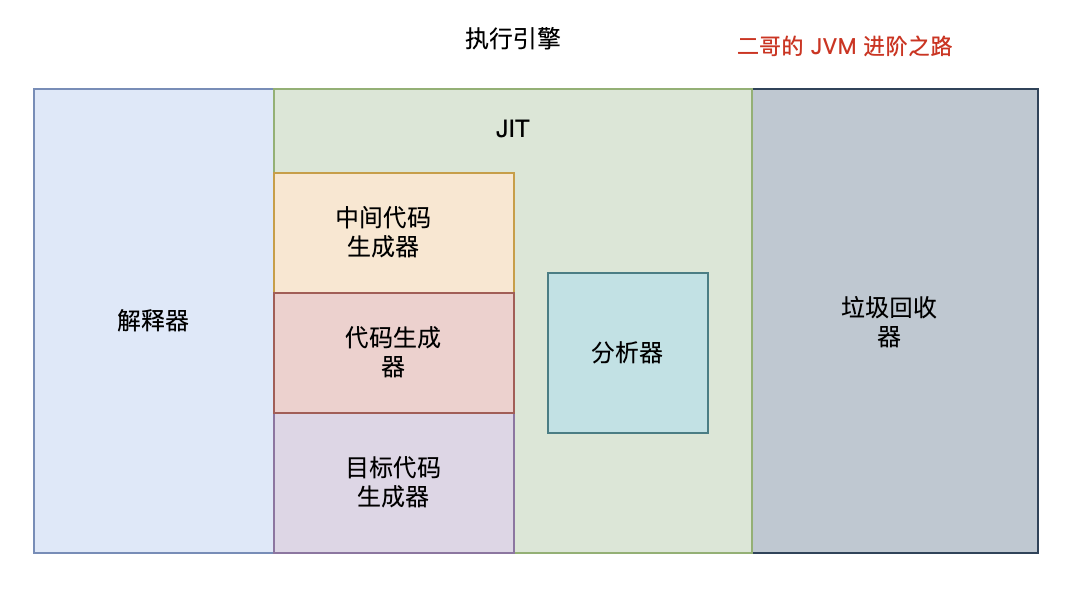
Java 代码首先被编译为字节码,JVM 在运行时通过解释器执行字节码。当某部分的代码被频繁执行时,JIT 会将这些热点代码编译为机器码,以此来提高程序的执行效率。
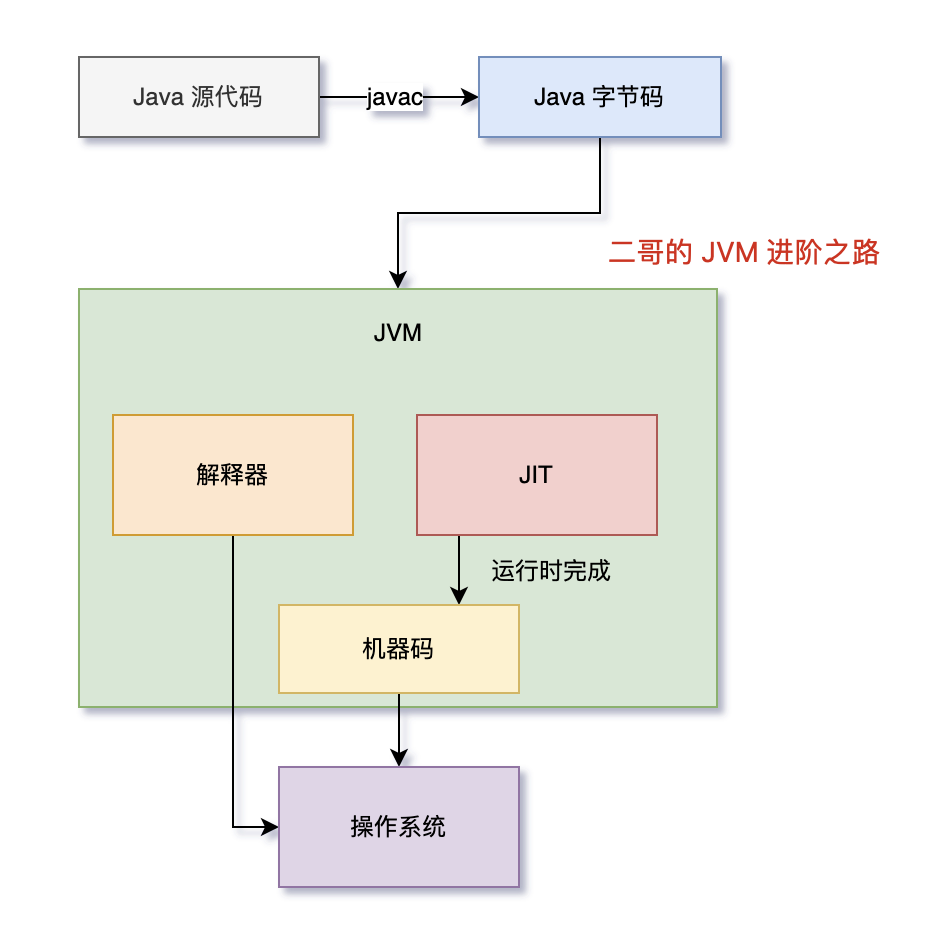
那为什么 JIT 就能提高程序的执行效率呢,解释器不也是将字节码翻译为机器码交给操作系统执行吗?
解释器在执行程序时,对于每一条字节码指令,都需要进行一次解释过程,然后执行相应的机器指令。这个过程在每次执行时都会重复进行,因为解释器不会记住之前的解释结果。
与此相对,JIT 会将频繁执行的字节码编译成机器码。这个过程只发生一次。一旦字节码被编译成机器码,之后每次执行这部分代码时,直接执行对应的机器码,无需再次解释。
除此之外,JIT 生成的机器码更接近底层,能够更有效地利用 CPU 和内存等资源,同时,JIT 能够在运行时根据实际情况对代码进行优化(如内联、循环展开、分支预测优化等),这些优化是在机器码级别上进行的,可以显著提升执行效率。
换句话说,解释器是一个循规蹈矩的人,每次都要按照规则来执行,而 JIT 是一个“偷奸耍滑”的人,他会根据实际情况来做出最优的选择。
好,我们再来梳理一下。
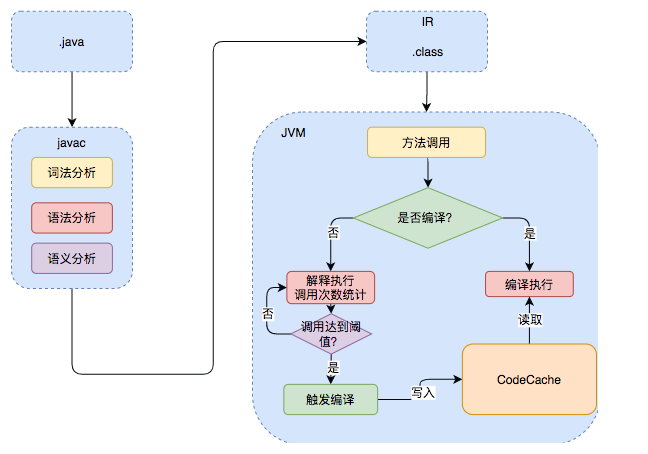
Java 的执行过程分为两步,第一步由 javac 将源码编译成字节码,在这个过程中会进行词法分析、语法分析、语义分析。
第二步,解释器会逐行解释字节码并执行,在解释执行的过程中,JVM 会对程序运行时的信息进行收集,在这些信息的基础上,JIT 会逐渐发挥作用,它会把字节码编译成机器码,但不是所有的代码都会被编译,只有被 JVM 认定为热点代码,才会被编译。
怎么样才会被认为是热点代码呢?
JVM 中有一个阈值,当方法或者代码块的在一定时间内的调用次数超过这个阈值时就会被认定为热点代码,然后编译存入 codeCache 中。当下次执行时,再遇到这段代码,就会从 codeCache 中直接读取机器码,然后执行,以此来提升程序运行的性能。
整体的执行过程大致如下图所示:
这里的 codeCache 让我想起了 Redis,Redis 也是将热点数据存储在内存中,以此来提升访问速度。
OK,解释清楚了 JIT 的原理,我们来看看 JIT 的实现。
JVM 的编译器
JVM 中集成了两种编译器,一种是 Client Compiler,另外一种是 Server Compiler。
Client Compiler 注重启动速度和局部的优化,Server Compiler 则更加关注全局的优化,性能会更好,但由于会进行更多的全局分析,所以启动速度会慢一些。
两种编译器相辅相成,互为臂膀,共同把 JVM 的性能带到了一个新的高度。
Client Compiler
就那虚拟机中的太子 HotSpot 来说吧,它就带有一个 Client Compiler,被称为 C1 编译器,启动速度极快。
C1 通常会做这三件事:
①、局部简单可靠的优化,比如在字节码上进行一些基础优化,方法内联、常量传播等。
我们来举例看一下什么是方法内联,假设我们有两个简单的方法:
public class Example {
public int add(int a, int b) {
return a + b;
}
public void run() {
int result = add(5, 3);
System.out.println(result);
}
}
在执行 run 方法时,会调用 add 方法,方法内联优化后,会将 add 方法的字节码直接插入到 run 方法中,这样就不用再去调用 add 方法了,直接执行 run 方法就可以了。
public class Example {
public void run() {
int a = 5;
int b = 3;
int result = a + b; // 这里是内联后的 add 方法体
System.out.println(result);
}
}
②、将字节码编译成 HIR(High-level Intermediate Representation),别计较它中文名叫什么,我觉得与其死板的翻译,不如就记住它叫 HIR,一种比较接近源代码的形式。
通过借助 HIR 我们可以实现冗余代码消除、死代码删除等编译优化工作,我们同样通过代码来看一下。
public class OptimizationExample {
public int calculate(int x, int y) {
int a = x + y;
int b = x + y; // 冗余计算
return a * b;
}
}
很明显,上面的代码中,b 的值是可以直接通过 a 的值计算出来的,所以 b 的计算就是冗余的,我们可以通过 HIR 来消除这种冗余计算。
public class OptimizationExample {
public int calculate(int x, int y) {
int a = x + y;
return a * a; // 使用一个计算结果
}
}
在 HIR 优化阶段,编译器识别到 x + y 的计算是冗余的,因此它将第二次计算的结果用第一次的结果替换。
③、最后将 HIR 转换成 LIR(Low-level Intermediate Representation),比较接近机器码了。这期间会做一些寄存器分配、窥孔优化等。
寄存器分配是指在编译时将程序中的变量分配到 CPU 的寄存器上。由于寄存器的访问速度远快于内存,因此合理的寄存器分配可以显著提高程序的执行效率。
来看这段代码:
int a = 5;
int b = 10;
int c = a + b;
System.out.println(c);
在没有寄存器优化的情况下,编译器会将变量 a、b、c 分配到内存中,然后在执行时,再从内存中读取变量的值。有了寄存器分配优化呢?
R1 = 5 // 将 5 赋值给寄存器 R1
R2 = 10 // 将 10 赋值给寄存器 R2
R3 = R1 + R2 // 将 R1 和 R2 的和赋值给寄存器 R3

1人已点赞

回复