


PaiFlow工作流Agent是如何做超时控制与异常处理的?
工作流在执行过程中,很难保证每一次都能按照预期顺利跑完。现实情况可能是,模型调用超时,代码本身存在 bug。所以我们需要提前考虑异常情况下的处理,未雨绸缪(聪明如我)。
PaiFlow 的异常处理方案,首先考虑的是容错性。比如网络波动、短暂的服务不可用等,通过重试机制,让流程有机会自我恢复,而不是一次失败就终止。
其次是可控性。异常处理必须要引入超时控制,防止某个节点卡死,拖垮整个工作流。然后还要灵活,不同业务场景对异常的容忍度不一样,有的要立即失败,有的要给兜底结果继续向下执行,还有的需要异常分支。
最后要有记录,无论是日志、回调事件,还是最终的执行结果,都应该让用户和开发者清楚地知道哪里出了问题,系统做了什么决策,流程最终是如何结束的。
典型的既要又要😄。
理想状态下,用户构建出的工作流应该是一个完整的 DAG 图,并且每个节点都能按部就班地执行。
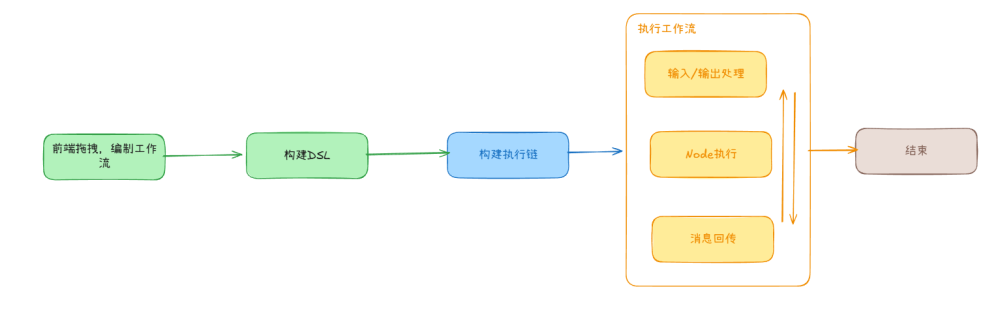
但如果用户拖拽出来的工作流没有 End 节点、存在自环、节点参数未填写等,这些都可能导致 DSL 构建失败;又或者执行过程中,因为变量过多/内存泄露导致 OOM;还有一些节点在执行的时候,依赖的服务挂了、模型超时等原因失败;再或者工作流执行成功了,但在给客户端回传消息的过程中,网络断了、连接挂了。。。。。。
对于业务场景下的异常,比如说工作流不完整、缺少参数、节点逻辑配置错误等,应该明确告诉用户哪里错了。对于程序异常,基本上都是因为系统本身存在 bug、第三方服务不可用、代码未覆盖边界等,这些异常一方面需要报警,另一方面要尽可能保障主流程可恢复。
对于 PaiFlow,第一期我们聚焦这几个环节:
-
节点执行超时,避免某...

8人已点赞








热门评论
9 条评论
回复