


面渣逆袭OpenClaw篇:1.3万字60张图,AI Agent 八股第一波
01、卸载龙虾的命令是什么?
“王哥,你这个问题问得好。很多人以为卸载就是跑一条 npm uninstall -g openclaw,错。”
这样卸载不干净,残留文件会藏在系统的各个角落,下次重装的时候各种报错——端口被占用、配置冲突、插件加载失败,一堆莫名其妙的问题。
正确的卸载姿势分三步。
第一步:停止 Gateway 服务
openclaw gateway stop
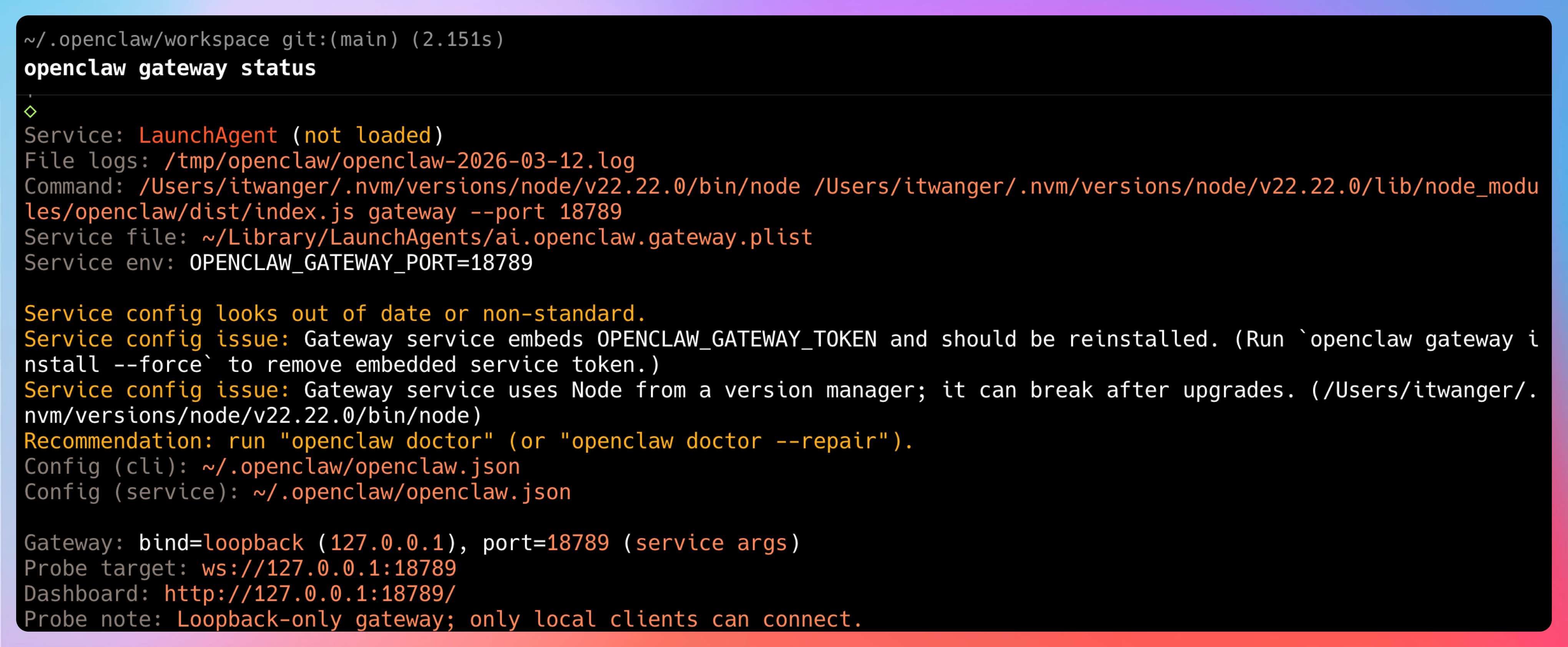
如果 Gateway 正在跑任务,强制停止可能会丢数据。建议先检查状态:
openclaw gateway status
确认显示 stopped 再继续。
第二步:执行官方卸载命令
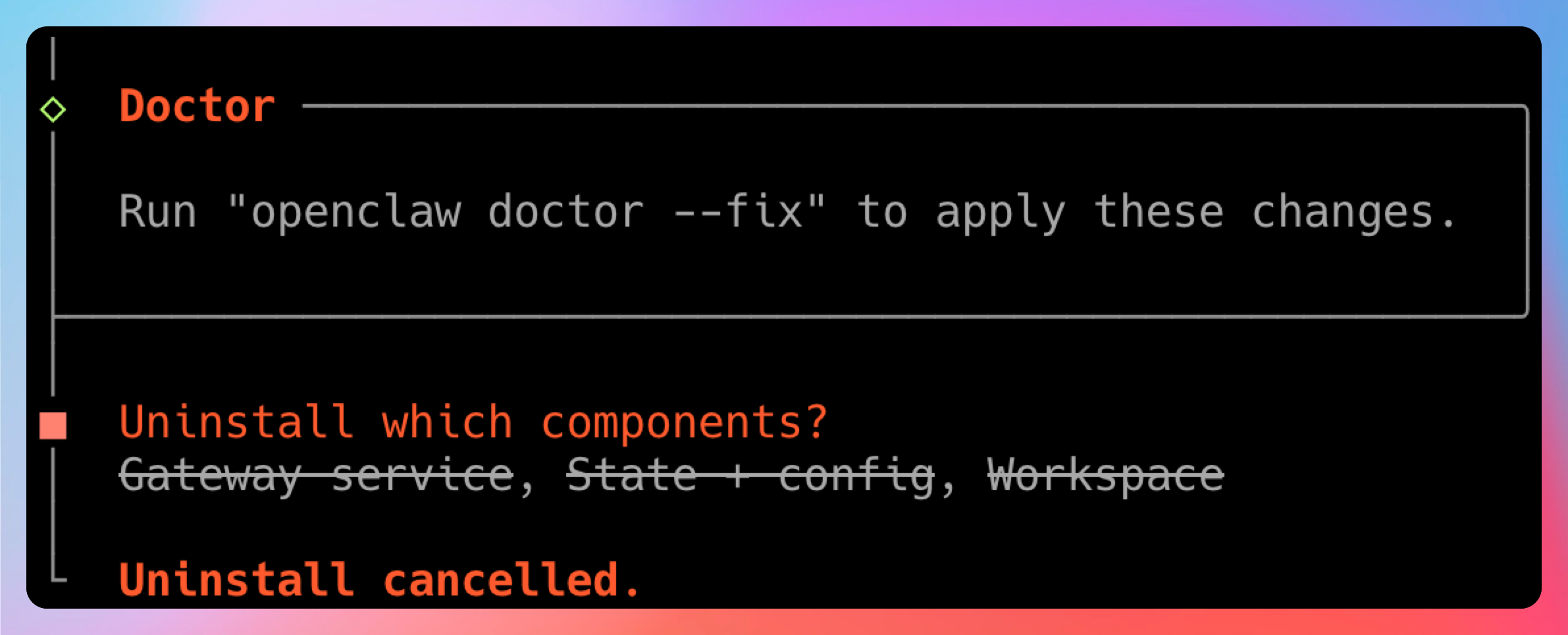
openclaw uninstall
这个命令会弹出一个交互界面,让你选择要删除哪些内容。用空格键全选,然后回车确认。它会帮你:
- 停止并卸载 Gateway 服务
- 删除
~/.openclaw/状态目录 - 清理工作区配置
- 移除插件和缓存
第三步:移除全局 CLI 包
npm rm -g openclaw
如果你用的是 pnpm 或 bun,对应换成:
pnpm rm -g openclaw
bun rm -g openclaw
遇到权限错误就加 sudo。
老王点点头:“那卸载后怎么验证干净?”
我说:“执行以下命令,确认没有残留:”
# 检查全局包
npm list -g openclaw
# 检查目录
ls ~/.openclaw/
# 检查端口占用
lsof -i:18789
全部返回空或“not found”,才算卸载干净。
老王听完点点头:“行,卸载这块确实熟。那我追问一下,~/.openclaw/ 目录里都有什么?为什么删这个目录这么重要?”
memo:更新与3月26日,顺带给大家分享一下二哥编程星球的喜报,蔚来和机器人公司的日常实习拿下,恭喜这位球友。

02、龙虾的架构了解吗?
“王哥,你这是要考我架构啊。”
~/.openclaw/ 是 OpenClaw 的“神经中枢”,里面存放着所有配置和状态。
~/.openclaw/
├── openclaw.json # 全局配置文件
├── gateway/ # Gateway 相关
│ ├── config.json # Gateway 配置
│ ├── logs/ # 日志目录
│ └── pid # 进程 ID 文件
├── plugins/ # 插件目录
│ ├── @openclaw/ # 官方插件
│ └── @wecom/ # 第三方插件
├── workspaces/ # Agent 工作区
│ ├── default/ # 默认 Agent
│ └── paigit/ # 自定义 Agent
├── skills/ # 技能包
├── cache/ # 缓存目录
└── .env # 环境变量

老王继续追问:“这里面的每个目录都有什么用?你挑重点讲。”
2-1 openclaw.json有什么用?
这是 OpenClaw 的“大脑配置中心”。
{
"version": "2026.3.2",
"gateway": {
"port": 18789,
"auth": "token",
"host": "0.0.0.0"
},
"channels": {
"feishu": {
"appId": "cli_xxx",
"appSecret": "xxx"
},
"wecom": {
"botId": "xxx",
"secret": "xxx"
}
},
"model": {
"provider": "glm",
"profile": "coding-plan",
"defaultModel": "glm-5"
},
"plugins": [
"@openclaw/feishu-plugin",
"@wecom/wecom-openclaw-plugin"
]
}
里面记录了:
- Gateway 配置:监听端口、认证方式、绑定地址
- IM 通道配置:飞书、企微等应用的凭证
- 大模型配置:提供商、套餐、默认模型
- 插件列表:已安装的插件及其加载顺序
王哥追问:“Gateway 配置里的 auth: "token" 是什么意思?Gateway 到底是干什么的?”

2-2 Gateway有什么用?
“王哥,Gateway 是 OpenClaw 架构里最关键的设计。”
很多人用 OpenClaw,只知道装完跑 openclaw gateway start,但不知道 Gateway 到底在干啥。
简单说,Gateway 是一个常驻后台的消息路由服务。
它的职责有三层:
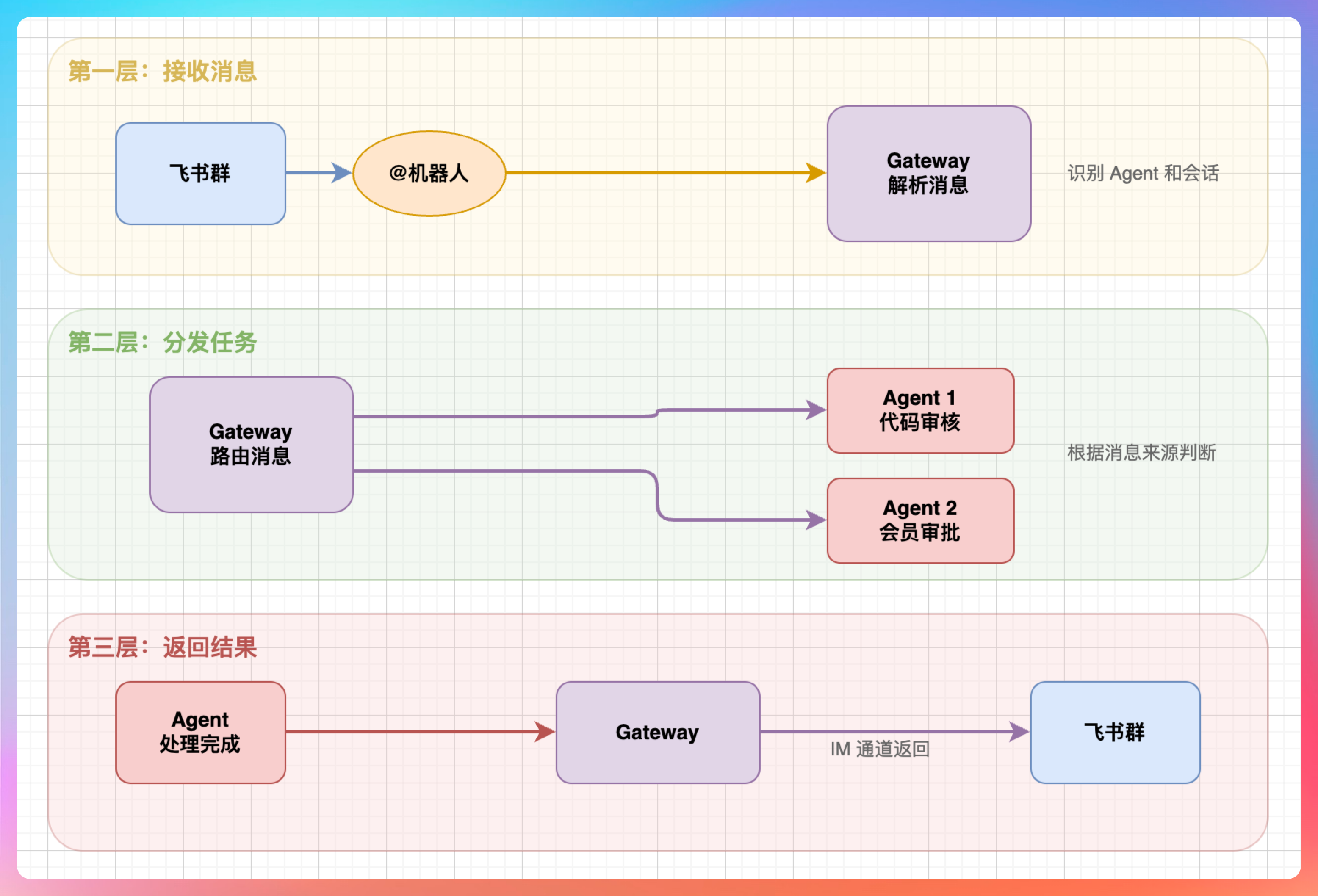
第一层:接收消息
你在飞书群里@机器人,飞书会把消息推送到 Gateway。Gateway 收到后,解析消息内容,识别是哪个 Agent、哪个会话。
第二层:分发任务
Gateway 把消息路由给对应的 Agent 处理。如果你配置了多个 Agent(比如一个负责代码审核,一个负责会员审批),Gateway 会根据消息来源判断该交给谁。
第三层:返回结果
Agent 处理完任务后,把结果交给 Gateway,Gateway 再通过 IM 通道发回飞书。
飞书消息 → Gateway → Agent → 大模型 → Agent → Gateway → 飞书回复
老王听完眼睛一亮:“小伙子有水平啊。为什么要这样分层?Gateway 和 Agent 为什么不耦合在一起?”
我说:“解耦。Gateway 负责 IM 通信,Agent 负责任务执行。这样你可以一个 Gateway 挂多个 Agent,每个 Agent 用不同的模型、跑不同的任务,互不干扰。”
老王点点头:“那如果 Gateway 挂了怎么办?有没有高可用方案?”
我说:“王哥,你这问题越来越深了。目前 OpenClaw 官方没有提供高可用方案,Gateway 是单点的。如果要上生产,我的建议是:”
- Gateway 集群部署,用负载均衡器分发请求
- 会话状态下沉到 Redis,Gateway 无状态
- 多实例之间用分布式锁协调任务执行
老王若有所思:“那插件呢?OpenClaw 的插件机制是怎么跑的?”
2-3 插件体系了解吗?
我说:“OpenClaw 采用的是微内核架构。”
核心只提供最基础的能力——消息收发、任务调度、工具调用。其他功能全部通过插件扩展。
- 飞书支持?插件。
- 企微支持?插件。
- 文档处理?插件。
插件安装在 ~/.openclaw/plugins/ 目录下,每个插件是一个独立的 npm 包。
# 安装飞书插件
openclaw plugins install @openclaw/feishu-plugin
# 安装企微插件
openclaw plugins install @wecom/wecom-openclaw-plugin
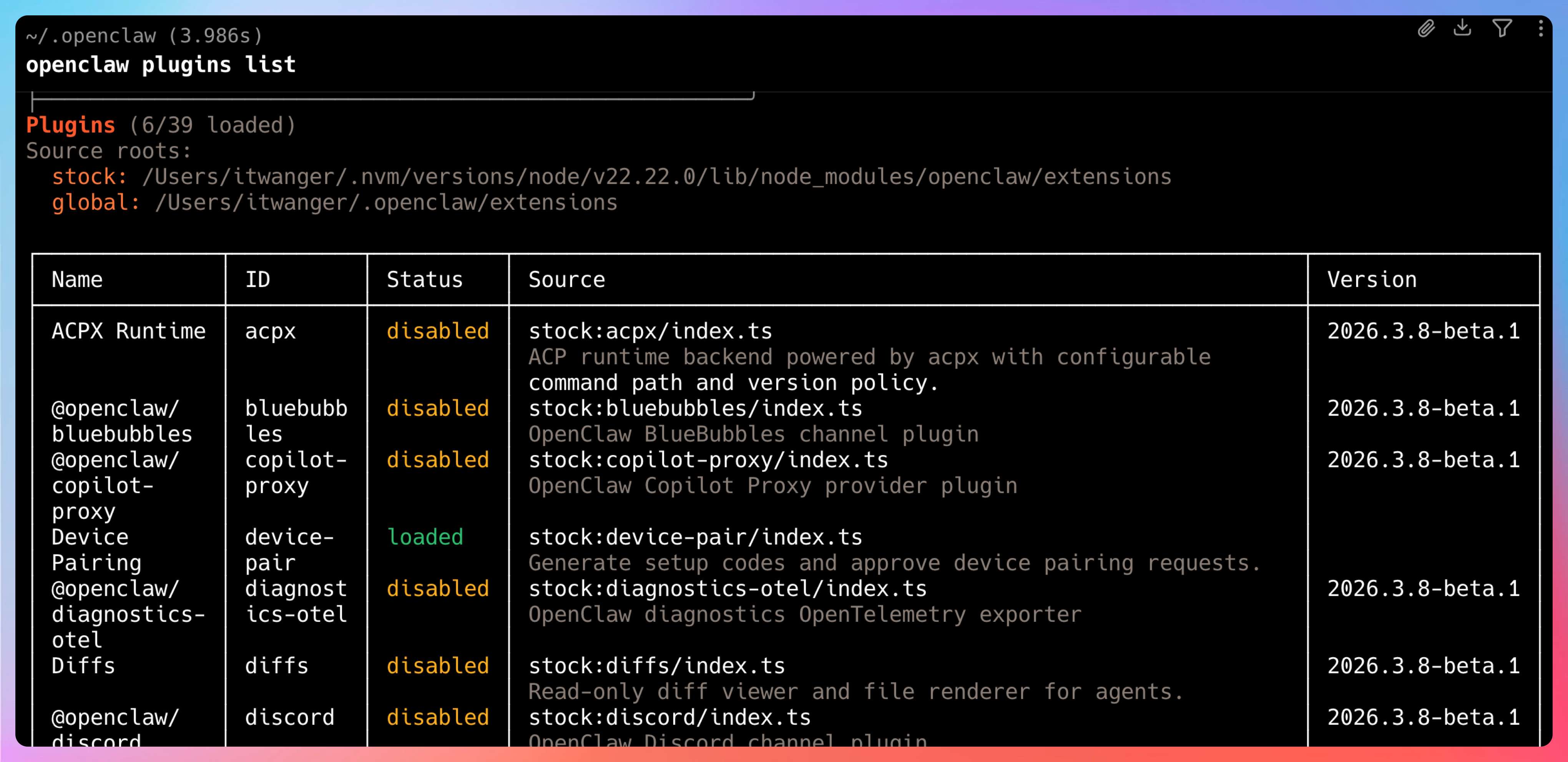
# 查看已安装插件
openclaw plugins list
老王追问:“插件加载的时机是什么?Gateway 启动的时候?如果两个插件对同一条消息都想处理,怎么解决冲突?”
我说:“对,Gateway 启动时会扫描 plugins 目录,按 openclaw.json 里的顺序加载所有插件。每个插件会注册自己的消息处理器和工具函数。”
“冲突解决靠优先级机制——openclaw.json 里可以设置插件优先级,优先级高的先处理。另外每个插件有自己的命名空间,互不干扰。”
老王满意地点点头:“架构这块讲清楚了。那我再问你——Gateway 的生命周期管理是怎样的?启动、停止、重启流程是什么?中间有什么坑?”
2-4 Gateway 的生命周期了解吗?
我说:“王哥,这个问题很实用,很多人踩过坑。”
启动 Gateway
openclaw gateway start
启动时会做几件事:
- 加载
openclaw.json配置 - 扫描并加载插件
- 初始化 IM 通道(连接飞书、企微等)
- 启动 HTTP 服务监听端口
- 写入 pid 文件
检查 Gateway 状态
openclaw gateway status
会显示:
- 运行状态(running / stopped)
- 进程 ID
- 监听端口
- 已加载的插件数量
停止 Gateway
openclaw gateway stop
如果 Gateway 卡住,可以强制停止:
openclaw gateway stop --force
或者直接杀进程:
kill $(cat ~/.openclaw/gateway/pid)
重启 Gateway
修改配置后需要重启:
openclaw gateway restart
2-5 启动时报错怎么排查?
老王追问:“启动的时候常见的报错有哪些?怎么排查?”
我说:“最常见的有三个问题。”
问题一:端口被占用
Error: Port 18789 is already in use
解决方法:
# 查看谁占用了端口
lsof -i:18789
# 杀掉占用进程
kill -9
问题二:插件加载失败
Error: Failed to load plugin @openclaw/feishu-plugin
解决方法:
# 重新安装插件
openclaw plugins uninstall @openclaw/feishu-plugin
openclaw plugins install @openclaw/feishu-plugin
问题三:配置文件损坏
Error: Invalid JSON in openclaw.json
解决方法:检查 JSON 格式,或者直接删掉重新配置。
老王点点头:“那消息流转呢?当你在飞书群里@机器人时,消息是怎么流转到 Agent 并返回结果的?整个链路涉及哪些组件?”
2-6 消息是怎么从飞书到龙虾再返回呢?
我说:“王哥,是这样的。”
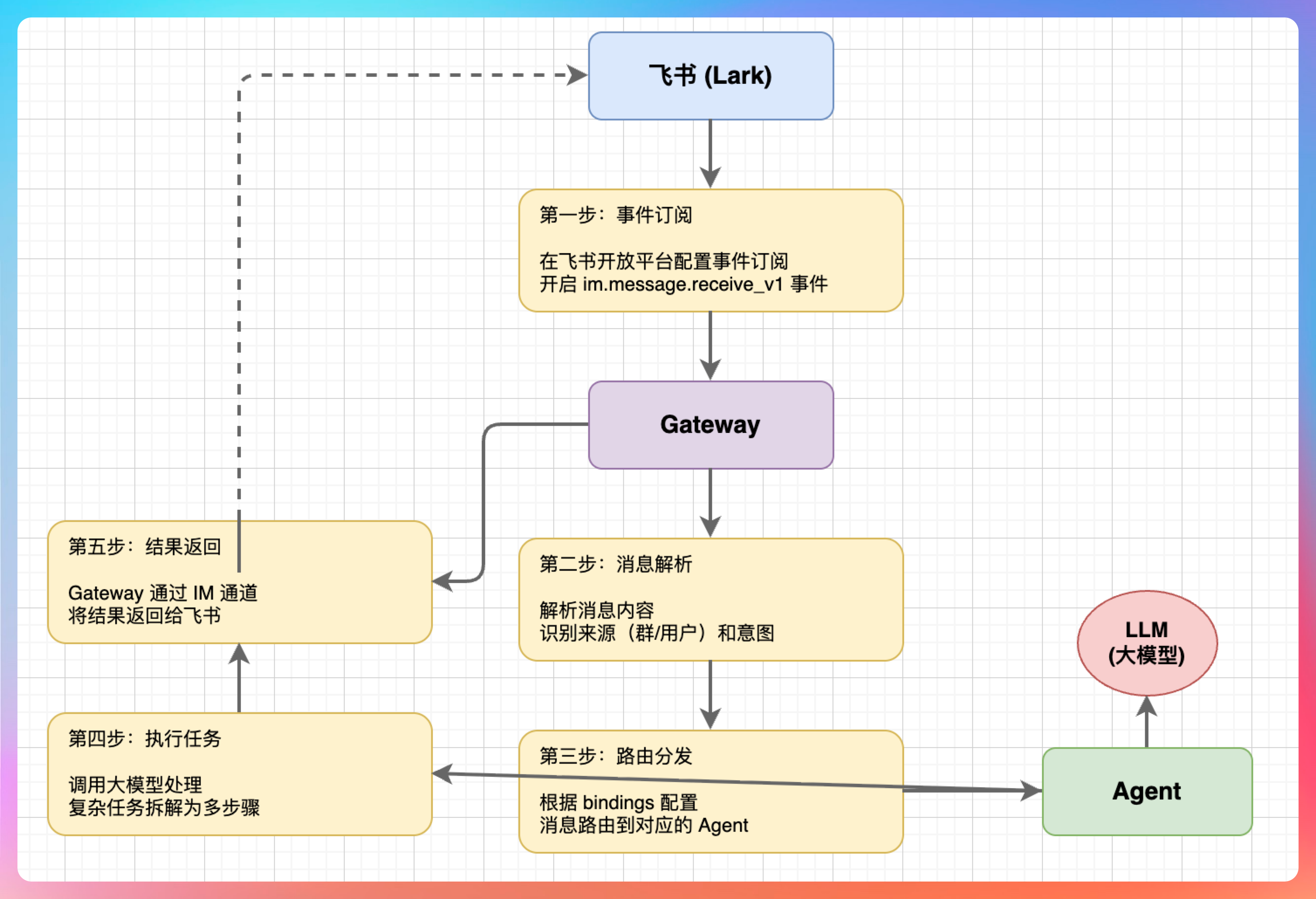
第一步:事件订阅
飞书把消息推给 Gateway。这需要在飞书开放平台配置事件订阅,开启 im.message.receive_v1 事件。
第二步:消息解析
Gateway 收到消息后,解析消息内容,识别来源(哪个群、哪个用户)和意图(要干什么)。
第三步:路由分发
根据 bindings 配置,把消息发给对应的 Agent。如果你配置了多个 Agent,Gateway 会根据消息来源判断该交给谁。
第四步:执行任务
Agent 调用大模型处理任务。如果是复杂任务,Agent 会拆解成多个步骤,一步步执行。
第五步:结果返回
Gateway 把结果通过 IM 通道返回给飞书。
2-7 龙虾有记忆吗?
老王追问:“那状态是怎么维护的?多轮对话的上下文存在哪里?”
我说:“会话上下文存在 ~/.openclaw/workspaces/ 目录下。每次对话会序列化保存,Gateway 重启后可以恢复。多轮对话用 session_id 标识,防止串台。”
2-8 并发处理能力如何?
老王接着问:“如果同时有 100 个用户@机器人,Gateway 怎么处理并发?”
我说:“Gateway 用异步非阻塞 IO 处理请求。每个消息生成唯一 request_id,防止混淆。Agent 执行队列化,避免资源竞争。”
老王点点头:“那 Agent 响应很慢怎么办?有没有优化方案?”
我说:“有几种优化思路:”
- 换更快的模型(比如 GPT-5.4)
- 简化 BOOT.md 里的指令
- 用流式输出,边生成边返回
- 复杂任务后台异步执行,先返回 ACK
老王听完感慨:“你这理解得够深的。那我再问你一个实际应用的问题,你用 OpenClaw 干过什么真实的业务场景?别给我整那些 demo。”
memo:更新与3月26日,顺带给大家分享一下二哥编程星球的喜报,腾讯暑期实习拿下,恭喜这位球友。
03、你用OpenClaw都干过什么?
我说:“王哥,这个问题问到我心坎里了。”
讲一个真实的场景——技术派(paicoding.com)的 gitcode 账号审核。
技术派加入的会员需要开通 gitcode 代码仓库的访问权限。以前这个流程是这样的:
- 会员申请加入
- 我收到通知
- 手动打开 gitcode 后台
- 搜索用户昵称
- 添加到对应的项目组
- 发消息通知会员审核通过
一个账号还好,如果一次来 20 个呢?光这个流程就要折腾半小时。
现在呢?我把这个任务交给了 OpenClaw。
第一步:创建一个专属 Agent
openclaw agents add PaiGit --workspace ~/openclaw-workspaces/paigit
第二步:配置 BOOT.md 告诉 Agent 它的职责
# PaiGit 职责
你是技术派的 gitcode 账号审核助手。
当收到飞书消息包含用户昵称时:
1. 登录 gitcode 后台
2. 搜索用户
3. 添加到技术派-会员组
4. 回复审核结果
第三步:绑定飞书通道
在飞书群里,我直接发消息:
帮我审核以下用户:张三、李四、王五
OpenClaw 收到消息后,自动执行整个审核流程。20 个账号,1 分钟搞定。
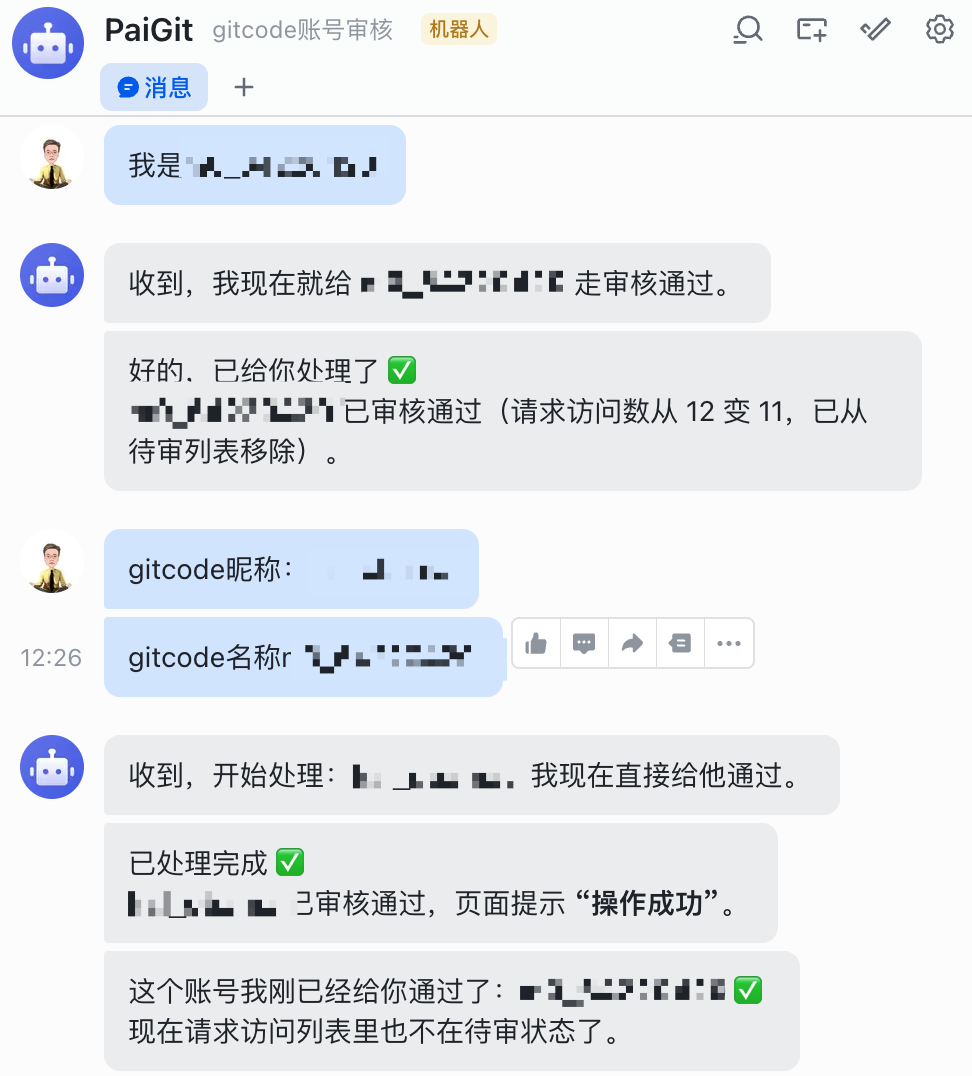
老王听完眼睛都直了:“这效率提升有点狠啊。”
我说:“还不止。我还给它设了定时任务,每天早上 9 点自动检查有没有新的待审核申请,有的话直接处理,处理完推送到飞书群。”
老王来了兴趣:“还有没有别的场景?”
3-1 飞书群消息同步搞过吗?
我又给他讲了一个——飞书群消息同步。
技术派有好几个飞书群:开发群、运营群、会员群。有时候一个群里发的消息需要同步到其他群,比如新功能上线通知。
以前的做法是:手动复制粘贴,或者用飞书的转发功能。但转发格式不好看,而且容易漏。
现在我用 OpenClaw 搞定了这个流程。
配置 Webhook
每个飞书群都有一个 Webhook 地址,可以在群设置里找到。
把这些 Webhook 地址告诉 OpenClaw:
记住以下群的 Webhook 地址:
发送同步指令
在开发群、运营群、会员群同时发送:派聪明 v2.0 今天上线了,新增了 AI 面试助手功能,大家快去体验!
OpenClaw 会自动调用 Webhook,把消息发到三个群。
老王点点头:“这个场景实用,省得一个个群转发。”
3-2 定时任务推送搞过吗?
“定时任务呢?你刚才说的每天早上 9 点给你推送最新的 hacknews 消息,是怎么实现的?”
OpenClaw 支持用自然语言创建定时任务。
直接告诉它:
每天早上 9 点,检查有 hacknews 有没有好玩的AI讯息,整理一下发送给我。
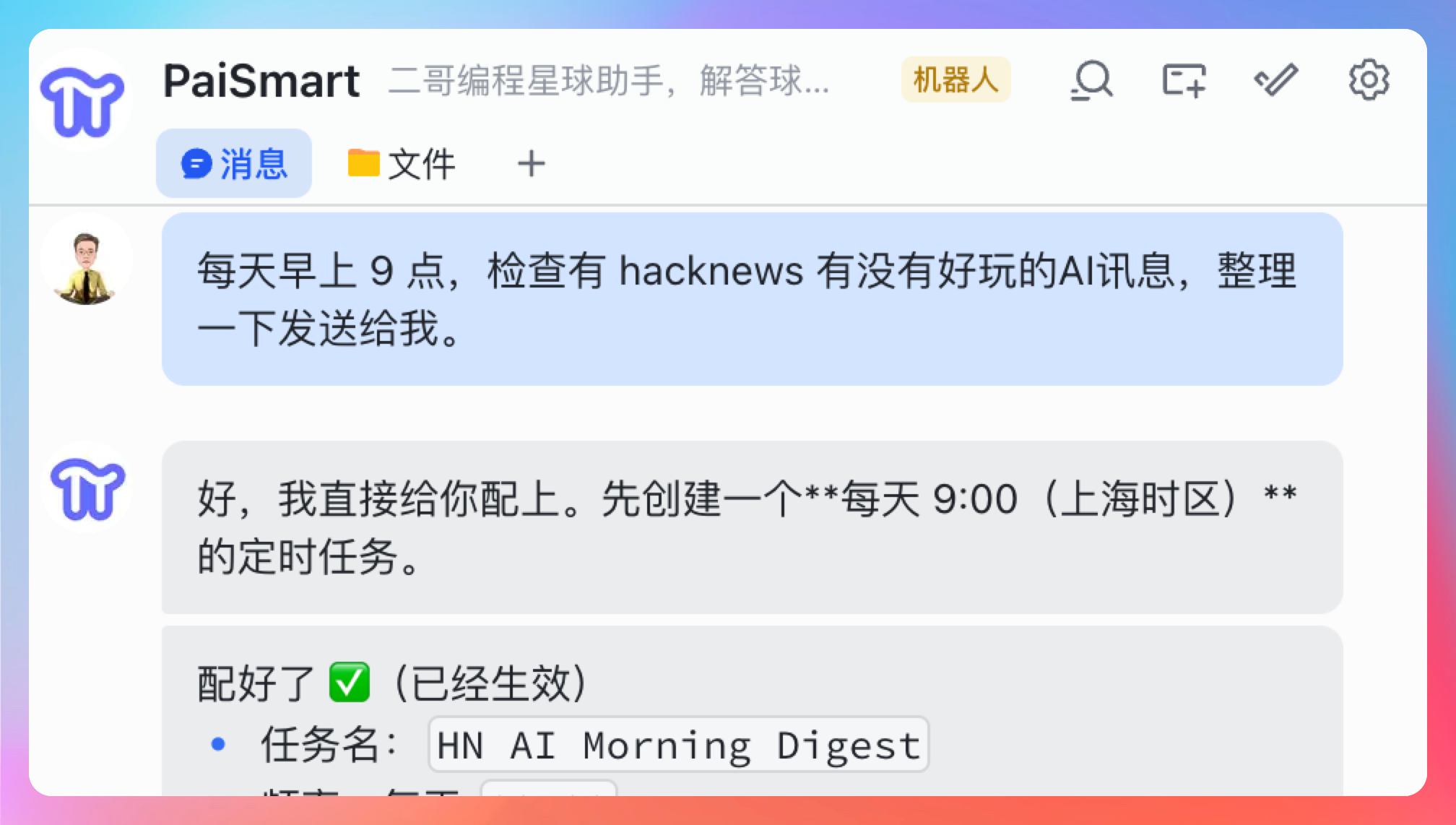
OpenClaw 会创建一个定时任务,到点自动执行。
定时任务的底层实现是 cron。OpenClaw 会把自然语言转成 cron 表达式,然后在后台调度执行。
老王追问:“定时任务如果执行失败了怎么办?有没有重试机制?”
我说:“目前 OpenClaw 没有内置重试机制,但可以通过 BOOT.md 里加错误处理逻辑来实现。比如告诉 Agent:'如果任务执行失败,等待 5 分钟后重试,最多重试 3 次'。”
“另外,定时任务执行结果会记录到日志里,可以在 ~/.openclaw/gateway/logs/ 目录下查看。”
老王听完感慨:“这三个场景都挺实用的,不是那种为了用工具而用工具。”
memo:更新与3月26日,顺带给大家分享一下二哥编程星球的喜报,京东云和华为春招拿下,恭喜这位球友。
04、使用龙虾过程中遇到过哪些问题?
老王话锋一转:“那我再问你一个方向——OpenClaw 需要调用大模型 API,在实际使用中,你遇到过哪些问题?比如 token 限制、响应延迟、费用控制。你是怎么解决的?”
我说:“王哥,这个问题太实际了,我踩过不少坑。”
04-1 token 如何优化?
OpenClaw 烧 token 是真的快。一个稍微复杂的任务,Agent 在后台可能调用十几轮甚至几十轮大模型。
我的优化方法:
- prompt 压缩:去除冗余信息,只传必要上下文
- 上下文裁剪:只保留最近 N 轮对话
- 结果缓存:相同问题直接返回缓存结果
04-2 响应慢怎么办?
大模型响应慢是通病。我的方案:
- 流式输出:边生成边返回,减少用户等待
- 异步处理:复杂任务后台执行,先返回 ACK
- 模型选择:简单任务用 Lite 模型,复杂任务用 Pro 模型
04-3 费用控制怎么做?
这个最头疼。我的做法:
- 配额管理:每天/每月设置 token 上限
- 成本追踪:记录每个任务的 token 消耗
- 自动降级:额度用完时切换到便宜模型
老王追问:“如果大模型 API 挂了怎么办?有没有降级方案?”
我说:“有。大模型挂了,切换到本地模型(比如 Qwen)。网络不通,用缓存兜底。超时处理,返回友好提示而非报错。”
04-4 如果让你把 OpenClaw 部署到生产环境,你会考虑哪些问题?
老王最后问了一个很实际的问题:“如果让你把 OpenClaw 部署到生产环境,你会考虑哪些问题?”
我说:“王哥,这个问题我能讲半小时。我挑重点说。”
高可用
- Gateway 集群部署,用负载均衡器分发请求
- 会话状态下沉到 Redis,Gateway 无状态
- 多实例之间用分布式锁协调任务执行
监控
- Gateway 层:监听端口、连接数、QPS
- Agent 层:任务执行成功率、平均响应时间
- 模型层:token 消耗、费用统计、模型调用成功率
日志
- 按模块分割日志(gateway.log、agent.log、plugin.log)
- 关键操作记录审计日志
- 日志轮转和归档(保留 30 天)
安全
- API Key 加密存储,支持动态轮换
- 插件白名单机制,只允许官方插件
- 网络隔离,Gateway 只对外暴露必要端口
老王点点头:“最后一个问题——你在用 OpenClaw 的过程中踩过什么坑?怎么排查的?”
04-5 使用过程中踩过哪些坑?
我说:“我挑几个最典型的说。”
Gateway 启动...
真诚点赞 诚不我欺
回复