


大家好,我是楼仔呀。
之前写过一篇《高频面试:如何保障 MySQL 和 Redis 的数据一致性?》,阅读量直奔 7K,但是里面只有理论,没有实战,今天就结合技术派项目,告诉大家如何去实现 MySQL 和 Redis 的一致性。
在讲解实战部分之前,我们还是先回顾一下理论知识,根据网上的众多解决方案,我们总结出 6 种:
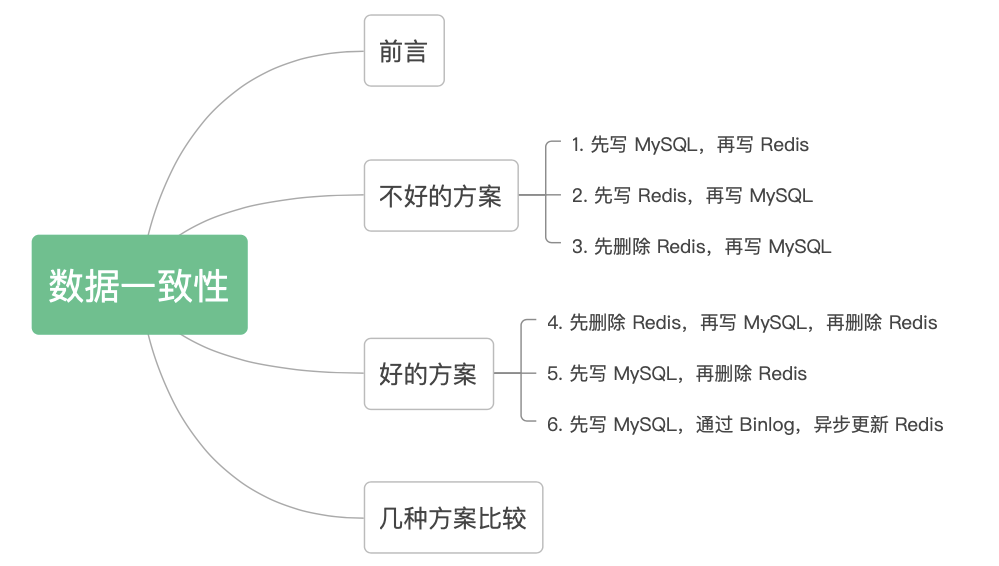
你可以先想想,技术派会采用哪种方案呢?
理论知识
温馨提示:如果你对理论知识已经非常清楚,可以直接跳到文章的实战部分。
不好的方案
1. 先写 MySQL,再写 Redis
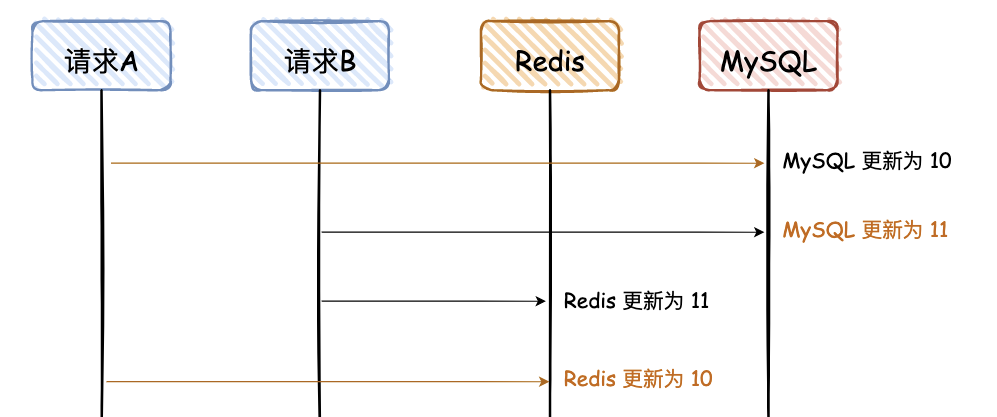
图解说明:
- 这是一副时序图,描述请求的先后调用顺序;
- 橘黄色的线是请求 A,黑色的线是请求 B;
- 橘黄色的文字,是 MySQL 和 Redis 最终不一致的数据;
- 数据是从 10 更新为 11;
- 后面所有的图,都是这个含义,不再赘述。
请求 A、B 都是先写 MySQL,然后再写 Redis,在高并发情况下,如果请求 A 在写 Redis 时卡了一会,请求 B 已经依次完成数据的更新,就会出现图中的问题。
这个图已经画的很清晰了,我就不用再去啰嗦了吧,不过这里有个前提,就是对于读请求,先去读 Redis,如果没有,再去读 DB,但是读请求不会再回写 Redis。 大白话说一下,就是读请求不会更新 Redis。
2. 先写 Redis,再写 MySQL
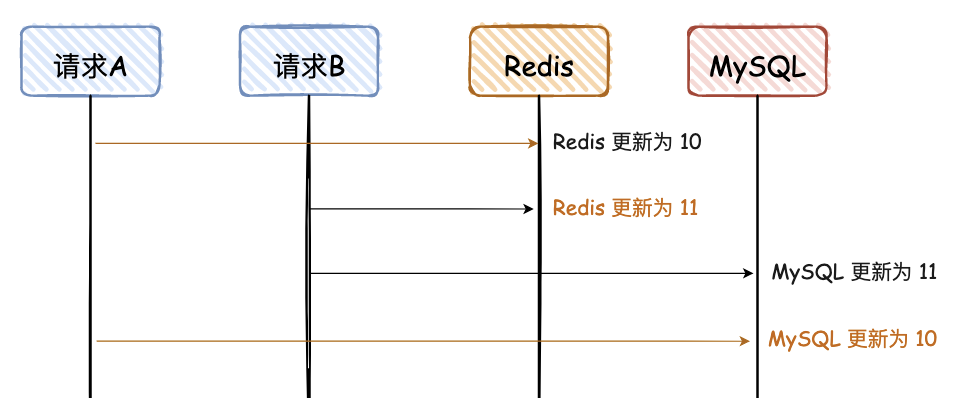
同“先写 MySQL,再写 Redis”,看图可秒懂。
3. 先删除 Redis,再写 MySQL
这幅图和上面有些不一样,前面的请求 A 和 B 都是更新请求,这里的请求 A 是更新请求,但是请求 B 是读请求,且请求 B 的读请求会回写 Redis。

请求 A 先删除缓存,可能因为卡顿,数据一直没有更新到 MySQL,导致两者数据不一致。
这种情况出现的概率比较大,因为请求 A 更新 MySQL 可能耗时会比较长,而请求 B 的前两步都是查询,会非常快。
好的方案
4. 先删除 Redis,再写 MySQL,再删除 Redis
对于“先删除 Redis,再写 MySQL”,如果要解决最后的不一致问题,其实再对 Redis 重新删除即可,这个也是大家常说的“缓存双删”。
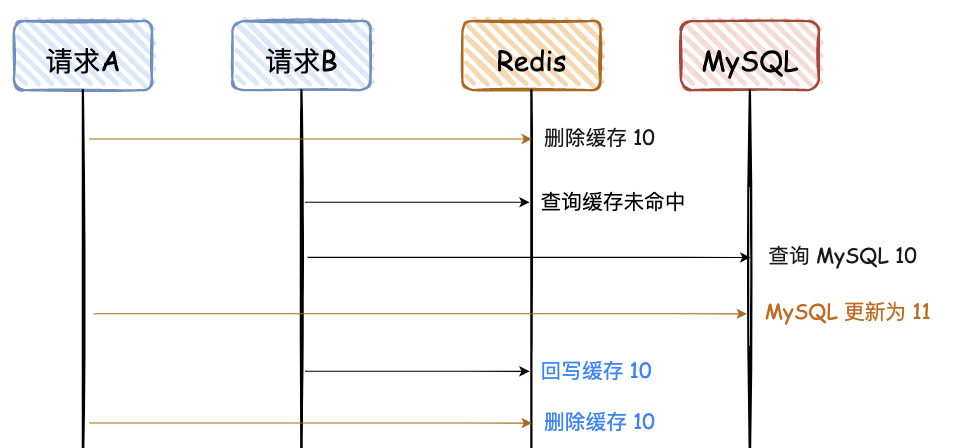
为了便于大家看图,对于蓝色的文字,“删除缓存 10”必须在“回写缓存10”后面,那如何才能保证一定是在后面呢?网上给出的第一个方案是,让请求 A 的最后一次删除,等待 500ms。
对于这种方案,看看就行,反正我是不会用,太 Low 了,风险也不可控。
那有没有更好的方案呢,我建议异步串行化删除,即删除请求入队列


5人已点赞





回复