



大家好,我是二哥呀。
每到年底,我都会有一种时不我待的感觉——还有好多事情没有做完呢!
不知道大家有没有相同的感受(想紧紧抓住多干点事)~
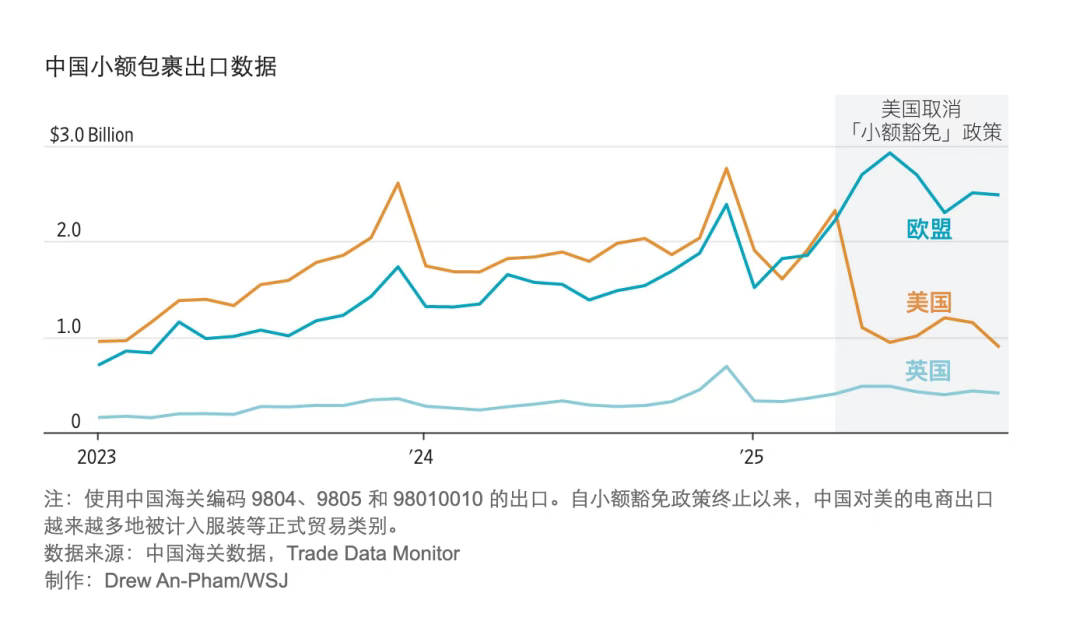
今天我们来盘点一下拼多多的 26 届校招薪资, 我已经收录在《Java 面试指南》 专栏中。这几乎是互联网大厂最后的期盼,通常都会开的比较高。

- 硕士 211,Java 后端开发岗,开了 36k,认识的全都比我高,心态有点崩,base 上海;
- TOP2,算法岗,开了 50k,明确 11116,比预期中的低很多;
- 硕士 985,后端岗,开了 39k,感觉开的还可以;
- 硕士 985,服务器研发,开了 35k,实习转正,和预期差距有点大,拒了。
对比其他家,拼多多开的其实很高 了,但无一例外,大家希望拼多多能开的更高(😄)
毕竟工作强度摆在那。另外,也可以间接证明,互联网大厂在疯狂卷 AI 这一年,开的薪资都很高,26 届几乎可以说是 23、24、25 届最羡慕的一届。
27 届看这势头,应该也会非常值得期待,这就是 AI 时代的红利,人们在 AI 的浪潮中又看到了新的曙光。
视金钱如废土,哦不,视金钱为动力的同学们还是要激发斗志,猛猛冲啊 🤣。
国内的大模型公司智谱、MiniMax 纷纷递交了招股书,释放的信号可见一斑。
拼多多虽然没有直接去卷大模型,但也在积极的推进大模型基建,上周的文章里我们也提到过。一位球友拿到了拼多多的 AI infra offer,薪资给的非常可观。

拼多多母公司的另外一个产品 Temu,相信大家也都有所耳闻,海外版的拼多多,目前体量可能已经接近拼多多的国内主站了。
拼多多联席董事长陈磊就曾在股东大会上讲过:Temu 用 3 年走完了拼多多国内电商 10 年的路。
可能有同学存在这样那样的偏见,觉得拼多多肯定没人去,但我要告诉大家一个数字:拼多多目前的员工数约为 2.3 万,妥妥的互联网大厂啊。
该冲还是要冲,你可以拿到 offer 后不去,但千万别简历都舍不得投(😄)。

多说一句,考研结束了,26 届参加考研的同学,估计接下来会有一大波冲入到春招的准备当中(往年就是这么一个情况)。
虽然复试的准备也很辛苦,但奔着两手准备的原则,只能咬牙再坚持坚持,毕竟春节后春招就开始了,也就还有 2 个多月的时间。
对了,冲寒假前日常实习的 27 届同学,记得把简历准备好,我现在每天改的简历中,也几乎都是 27 届的同学。

对于没办法实习,但仍然想要拿派聪明 RAG 这个项目去面试的同学,我这里分享一个攻略:如何掷地有声地介绍派聪明这个项目,打动面试官。
面试官你好,简单来说,派聪明是一个企业级的 RAG 问答知识库。您可以把它想象成一个私有化部署的、专门针对企业内部文档的 ChatGPT。

员工可以上传公司的各种资料,比如产品手册、技术文档、规章制度、会议纪要等,然后通过自然语言对话的方式,快速准确地从这些海量资料中获取信息。
我是借鉴了 anythingLLM 这个产品来实施的,代码层面有使用 Claude Code 来辅助完成。
这个项目的核心是基于目前业界非常流行的 RAG 架构。
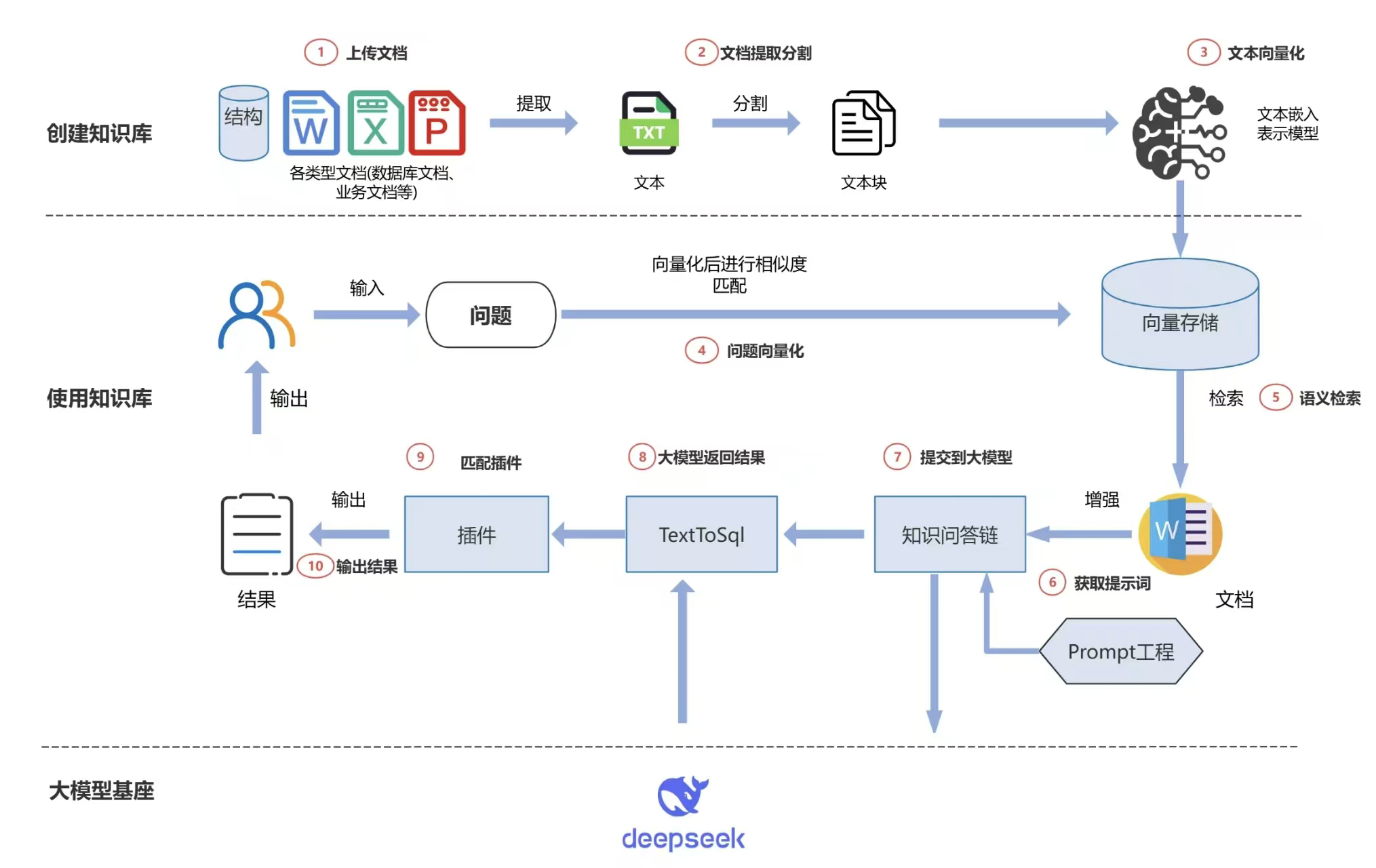
我来为您拆解一下整个技术流程:
后端主要采用 Spring Boot 3 全家桶,配合 Java 17 。前端是 Vue 3 结合 Vite 。数据和中间件层面,我用了 MySQL 做业务数据存储, Redis 做缓存, Kafka 作为消息队列, Elasticsearch 作为向量数据库和全文检索引擎,以及 MinIO 作为对象存储服务。
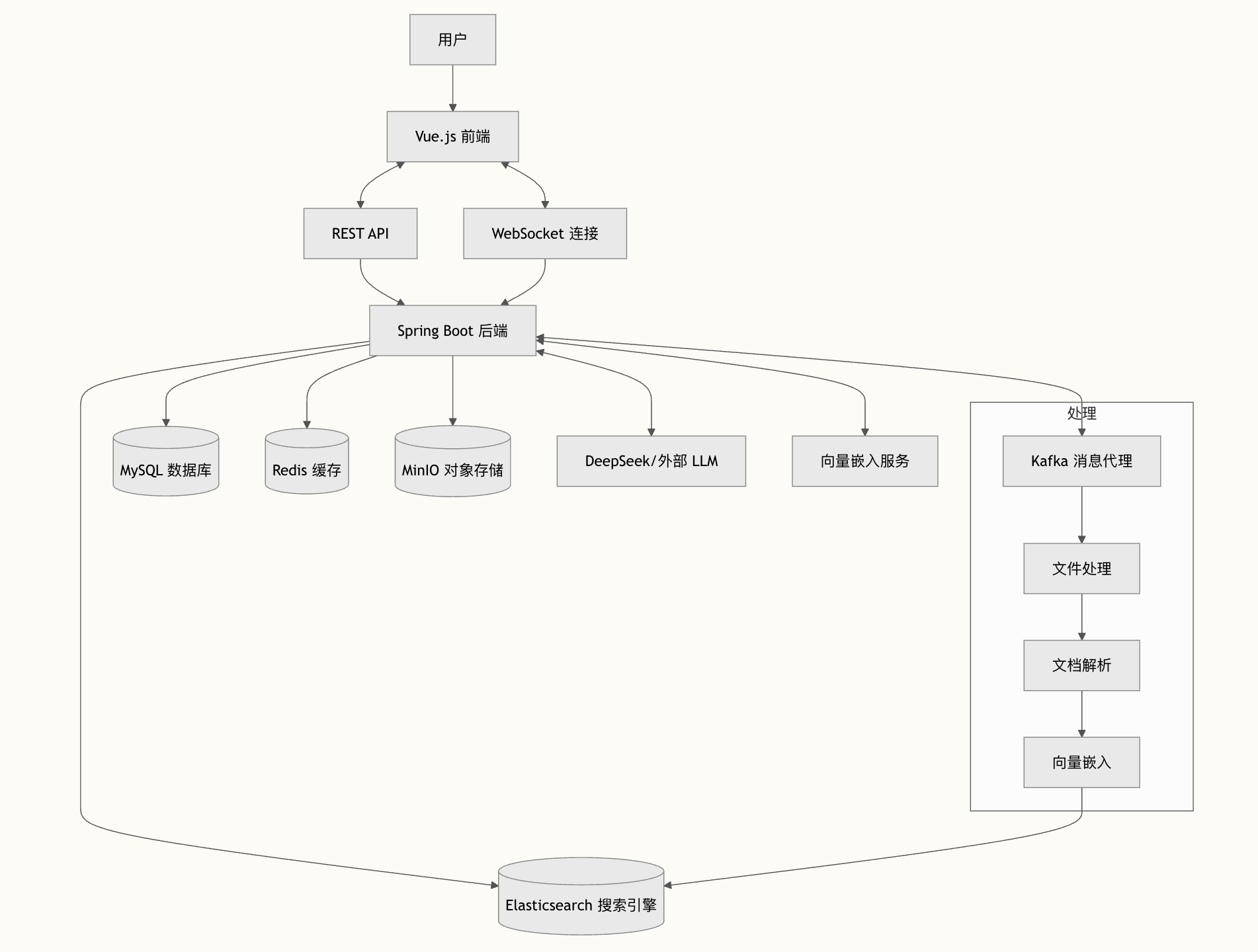
用户通过前端界面上传文件。后端接收到文件后,会将其存入 MinIO 对象存储中,这样做的好处是便于管理非结构化数据。文件存入 MinIO 后,系统不会立即处理它,而是创建一个文件处理任务对象,包含文件的路径、上传者信息等,然后将这个任务发送到 Kafka 的 file-processing-topic 主题中。使用 Kafka 的目的是异步和削峰填谷,即使瞬间有大量文件上传,系统也能平稳处理,不会阻塞用户请求。
Kafka 的消费者监听到任务后,会从 MinIO 下载文件。我使用 Apache Tika 这个库来解析文件内容,它很强大,能自动识别并提取 Word, PDF, Markdown 等多种格式的文本。提取出的长文本会被切分成小的文本块(Chunks) ,为后续向量化做准备。
接下来,系统会调用一个外部的 Embedding 模型服务,将每一个文本块都转换成一个高维度的数学向量。然后, 文本块原文和它对应的向量会一起被存储到 Elasticsearch 中。Elasticsearch 在这里扮演了向量数据库的角色,同时我也利用了它强大的 BM25 全文检索能力。
当用户提出一个问题时,系统同样会将用户的问题文本进行向量化。
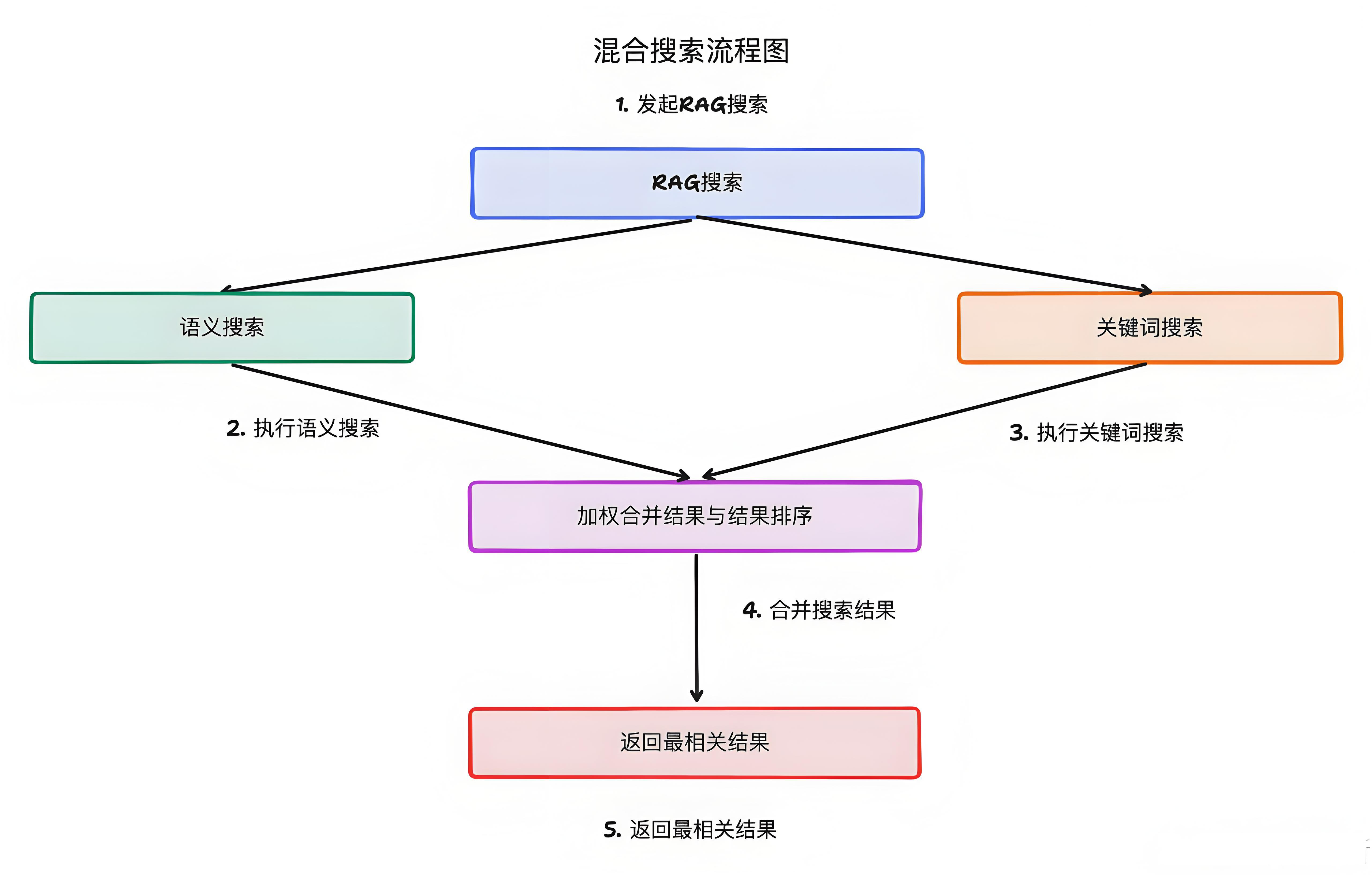
然后,系统会执行一次混合搜索(Hybrid Search):一方面在 Elasticsearch 中进行 向量相似度搜索 ,找到与问题向量最接近的文本块;另一方面进行关键词搜索(BM25) ,匹配关键词。结合两者的结果,就能非常精准地召回最相关的知识片段。
最后,派聪明会将召回的这些知识片段作为上下文(Context),连同用户的原始问题,一起打包成一个 Prompt,发送给一个大型语言模型(LLM)。
LLM 会根据我提供给它的上下文内容,生成一个忠于原文的、流畅的回答,并通过流式接口实时返回给前端,用户体验就像和真人对话一样。
大家可以把这段介绍反复背,背到滚瓜烂熟。
就像球友在 VIP 群里吐槽说,现在面试除了派聪明,其他都问的少,面试官巴不得派聪明的每一个标点符号都问一遍。

别抗拒,现在每个人都在被 AI 裹挟着往前,面试官不例外,我们求职者也无法置身事外。
当前这个节点,更像是一个时代切片——每一家公司都在把钱、技术往 AI 上靠,拼多多也不例外。
这本身就说明了一件事:大家都在用最现实的方式下注未来。
跟着拼吧!吧!
ending
一个人可以走得很快,但一群人才能走得更远。二哥的编程星球已经有 10900 多名球友加入了,如果你也需要一个优质的学习环境,戳链接 🔗 加入我们吧。这是一个 简历精修 + 编程项目实战(RAG 派聪明 Java 版/Go 版本、技术派、微服务 PmHub)+ Java 面试指南的私密圈子,你可以阅读星球专栏、向二哥提问、帮你制定学习计划、和球友一起打卡成长。
最后,把二哥的座右铭送给大家:没有什么使我停留——除了目的,纵然岸旁有玫瑰、有绿荫、有宁静的港湾,我是不系之舟。共勉 💪。







回复