


大家好,我是二哥呀。
途虎养车今年校招薪资真的杀疯了,比肩一线梯队的互联网大厂,以至于有几个拿到途虎养车 offer 的球友感慨说秋招签三方太早了,真的很想毁约签虎子。
从《Java 面试指南》专栏收录的途虎 26 届薪资来看,确实让人心动。
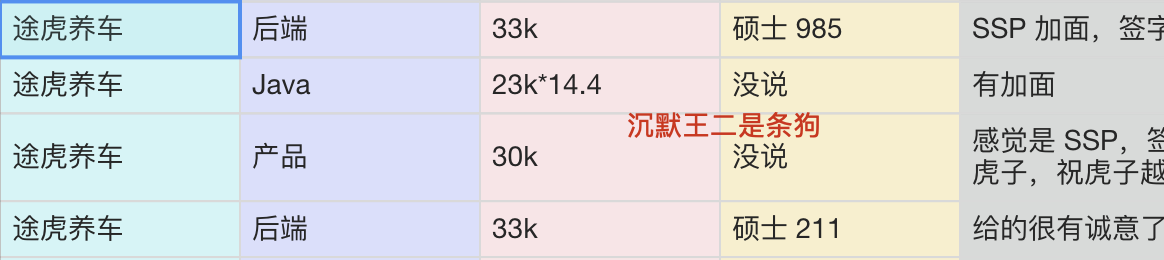
- 硕士 985,后端岗,开了 33k,ssp 有加面,签字费可 A,base 上海;
- Java 岗,开了 23k,有加面,base 武汉;
- 产品岗,开了 30k,感觉是 ssp,签字费 2+1 万,我爱虎子,祝虎子越办越好,base 上海;
- 后端岗,开了 33k,硕士 211,给的很有诚意了,base 上海。
上一点点证据,一位球友拿到了途虎养车的 ssp offer,还有两个互联网大厂,途虎的 base 是最高的,只不过球友对途虎养车的 title 和工作强度抱有一丝的不确定。
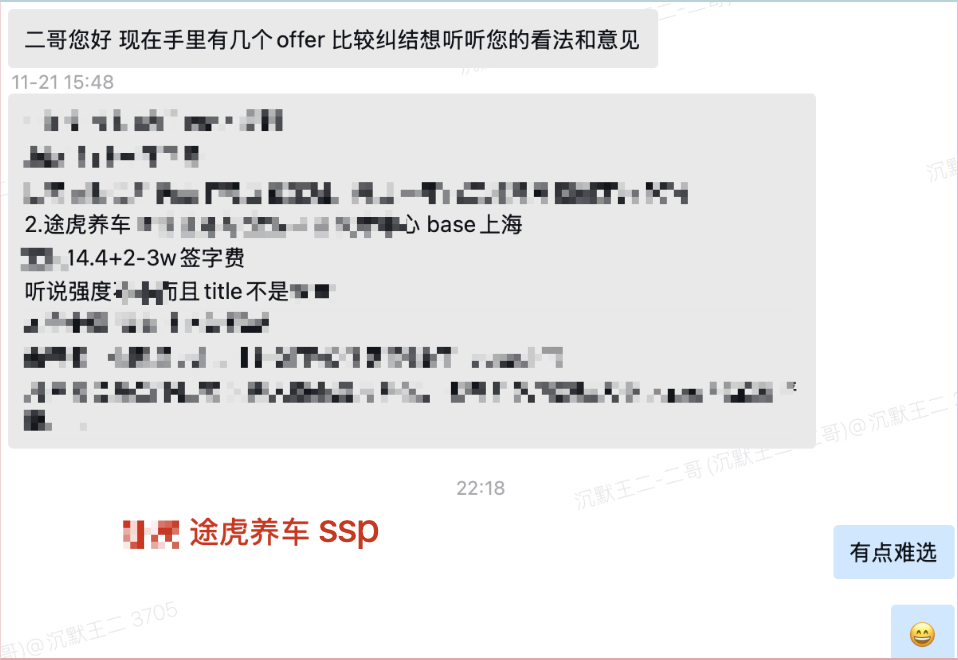
这样的担心也是人之常情,虎子并非传统的互联网大厂。对于新人来说,平台还是非常重要的,尤其是打算干两三年后跳槽的同学。
但如果你没有更大平台的 offer,那么选择途虎我觉得是完全 ok 的(据说用户规模达 1.4 亿)。
据途虎养车的平台负责人讲:“途虎每年在产研上的投入是亿万量级的,这么持续化地在数据化和人才方面进行投入,在汽后行业也是独一份”。
说到这里,很多同学会下意识问:既然途虎敢给到接近一线互联网的校招薪资,那他们面试到底看什么?
据一个拿到途虎养车 offer 的球友给我反馈,面试官对派聪明 RAG 项目非常感兴趣,至少他在面试的过程中,面试官基本上都会围绕着这个项目来展开提问。

我只能说,AI 已经渗透了各行各业啊,是人是鬼都在卷(我是鬼 🤣)
接下来,再给大家分享一些派聪明 RAG 在面试中被问到的题目,我总结了详细的答案,可供大家直接背诵。

二哥回复
答:对于复杂文档或手写文件,我们采用分层处理策略:
1、Tika 本身支持 1000+ 种文件格式,可通过 AutoDetectParser 自动识别并解析 PDF、Word、PPT 等文档;
// PaiSmart 使用 Tika AutoDetectParser 自动检测文件类型
AutoDetectParser parser = new AutoDetectParser();
parser.parse(bufferedStream, handler, metadata, context);
2、针对扫描件/手写文档,Tika 本身就可以集成 Tesseract OCR(通过 tika-parsers-standard-package 依赖自动引入)。对于 Java 技术栈,可以考虑使用 Tess4J (Tesseract OCR 的 Java 封装)。它通过 JNA 调用本地的 Tesseract 引擎,性能很高,对于印刷体识别效果很好。
对于高精度需求,可以接入商业 OCR 服务,如 百度 OCR、腾讯 OCR、阿里 OCR,或者开源的 PaddleOCR。
解析结果会通过置信度阈值过滤,低于阈值的会标记为待人工审核。
亮点:考虑到 OCR 是 CPU 密集型操作,为了避免阻塞文件上传的主线程,我们将 OCR 任务做了异步化。ParseService 在识别出需要 OCR 的文件后,会发布一条 Kafka 消息,由一个独立的服务来消费并执行 OCR。处理完成后,再将结果写回数据库和 Elasticsearch,以确保系统快速响应。
3、表格处理确实是 RAG 的难点,我们考虑从这几个层面解决:
- Excel 和 CSV 文件可以用 Tika 直接解析为文本;对于 Word/PDF 中的嵌入表格,Tika 会尽量保留结构转为纯文本
- 可以将表格转为 Markdown 表格格式或 JSON 结构保留语义,然后使用分隔符(如 |)保持行列关系,最后为表格添加元信息注释(如"此表格包含 3 列:姓名、年龄、城市"),LLM 对 markdown 的理解能力还是非常强的
- 对于 PDF 中的表格,可以引入 Tabula-Java 进行专业提取,这是一个专门从 PDF 中提取表格的 Java 工具
需要注意的是,表格不应被随意切分,应该作为完整的语义单元保留在一个 chunk 中。
// FileTypeValidationService.java
"xls", "xlsx", // Microsoft Excel表格
"csv", // CSV文件
"ods", // OpenDocument电子表格
"numbers", // Apple Numbers表格
亮点:对于特别重要的复杂表格,我们还会采用【摘要+原文】的双路径索引策略。先用 LLM 对表格生成一段自然语言的摘要(例如:‘这是一个关于 2025 年各产品线销售额的表格,其中 A 产品线最高’),将【摘要和 Markdown 原文】都进行向量化索引。这样,无论是模糊查询(‘哪个产品卖得最好’)还是精确查询,都能有效命中。
4、关于数据量和测试,我从几个维度来说明:
- 派聪明 RAG 采用 Elasticsearch 8.10 存储向量,支持 dense_vector 类型,单索引可支持百万级文档
- 向量维度为 2048 维(阿里 Embedding),使用 cosine 相似度
- 文本分块大小为 512 字符,一个 100 页 PDF 大约生成 500-1000 个 chunk
{
"vector": {
"type": "dense_vector",
"dims": 2048,
"index": true,
"similarity": "cosine"
}
}
对于单文件,我最大测试过 50MB 的 PDF(约 500 页),解析+向量化全流程约 1-2 分钟。知识库总量测试过 10 万+ chunk,混合搜索响应时间 < 200ms。
另外,针对性能优化,我们使用了 Kafka 进行异步处理,解耦文件上传和解析,避免主线程阻塞;并且采用流式解析(父子文档策略),避免大文件 OOM; 通过 HanLP 分词,以保证中文分块的语义完整性;混合搜索结合了 KNN 召回 + BM25 重排,以保证召回精度。
最后,我想说的是,途虎养车敢给出接近一线互联网的校招薪资,那咱们就要敢接。😄
求职就这几件事,八股、项目、算法、简历、场景题,千万不要有畏难情绪,不管是你现在投日常实习,还是秋招捡漏,不要放弃,不要气馁。
机会来了的时候,挡都挡不住的,哈!
ending
一个人可以走得很快,但一群人才能走得更远。二哥的编程星球已经有 10900 多名球友加入了,如果你也需要一个优质的学习环境,戳链接 🔗 加入我们吧。这是一个 简历精修 + 编程项目实战(RAG 派聪明 Java 版/Go 版本、技术派、微服务 PmHub)+ Java 面试指南的私密圈子,你可以阅读星球专栏、向二哥提问、帮你制定学习计划、和球友一起打卡成长。
最后,把二哥的座右铭送给大家:没有什么使我停留——除了目的,纵然岸旁有玫瑰、有绿荫、有宁静的港湾,我是不系之舟。共勉 💪。


回复